网易云音乐评论爬取
(给Python开发者加星标,提升Python技能)
作者:法纳斯特(本文来自作者投稿,简介见末尾)
近日,民谣歌手花粥被爆出涉嫌抄袭。
具体的我就不细说了,音乐圈的抄袭风波也是喜闻乐见。
比如,李袁杰的「离人愁」,展展与罗罗的「沙漠骆驼」还有陈柯宇的「生僻字」。
本次通过爬取网易云音乐的评论,即目前热歌榜第一名「出山」的评论。
来看看,在没被指出抄袭时,歌曲的评论画风是如何。
被指出抄袭后,又是怎样的一个画风。
/ 01 / 网页分析
网上关于爬取网易云音乐评论的方法,大多数都是讲如何构建参数去破解。
事实上不用那么复杂,直接调用接口就可以。
而且网易云音乐对评论也做了限制,只放出了2万条的评论数据。
前后各一万,即评论的前500页和后500页。
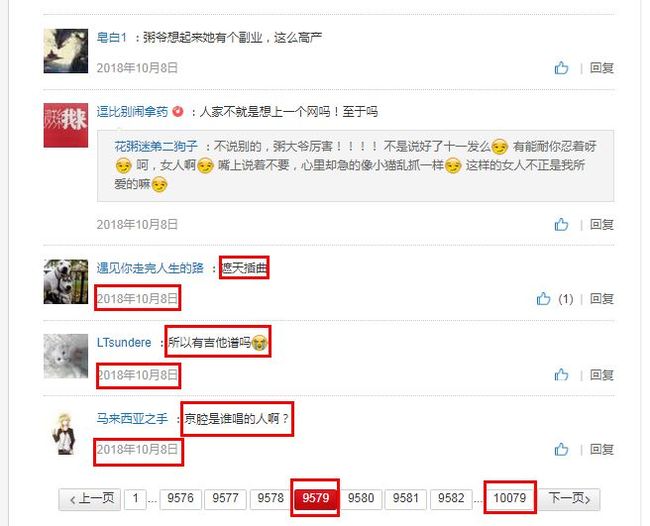
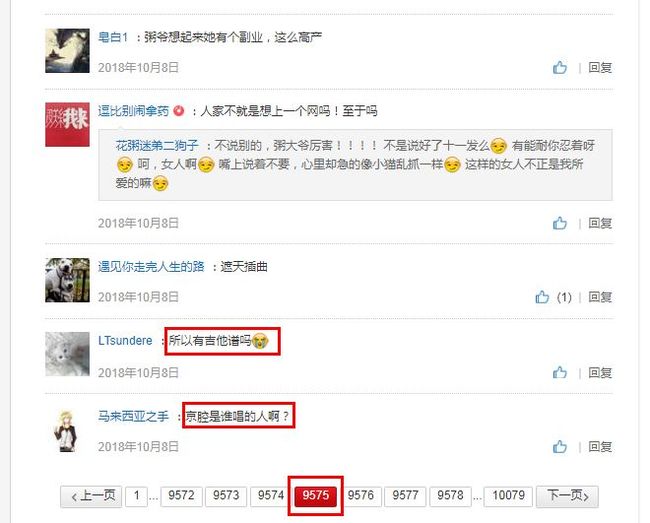
最后一页为10079,减500页应该是9579,然后你会发现9575页和9579页的数据是一模一样的。
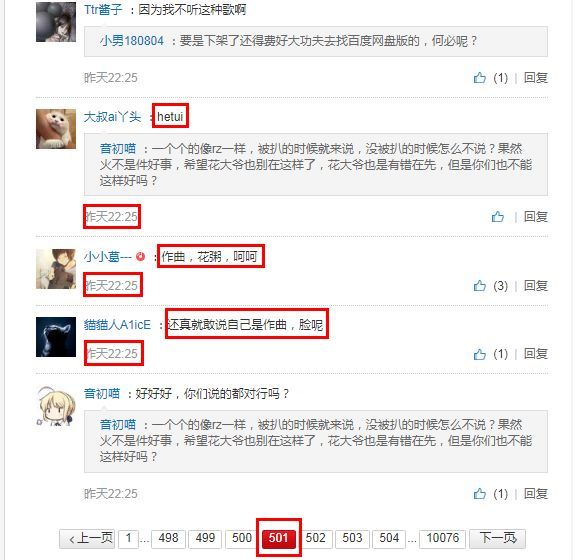
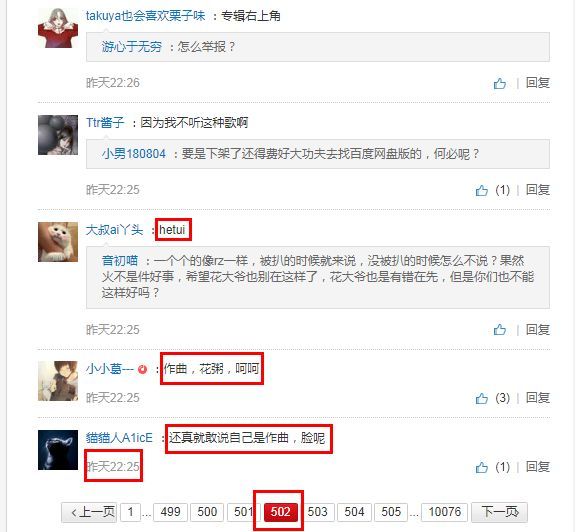
同样,501页和502页的数据也是一模一样的。
所以何必想着去构造参数,直接调用网易云音乐的评论API就是了,用户信息也是一个道理。
# 网易云音乐评论API,其中1313354324为音乐ID,limit为页面结果限制数,最大可设为100,offset为页面偏移量
http://music.163.com/api/v1/resource/comments/R_SO_4_1313354324?limit=20&offset=0
# 用户信息API
https://music.163.com/api/v1/user/detail/{用户ID}
这里就以花粥的「出山」为例,具体情况如下。
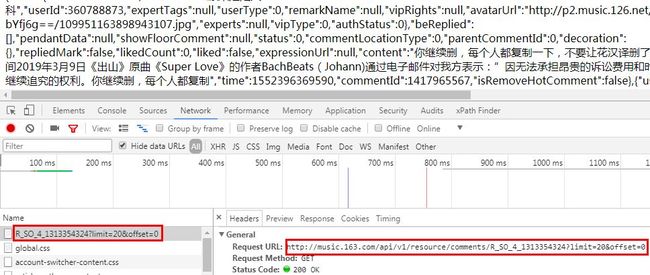
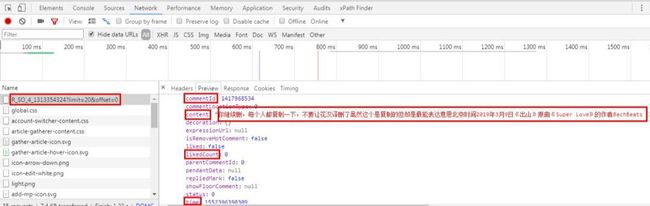
第一页妥妥的差评。这两天「出山」的评论区热闹非凡。
大部分的评论都是希望能尊重原创,然后下架花粥的歌。
当然,也有不少给花粥洗白的水军在评论区游荡...
/ 02 / 评论获取
具体代码如下。
import json
import time
import requests
headers = {
'Host': 'music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
def get_comments(page):
"""
获取评论信息
"""
url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_1313354324?limit=20&offset=' + str(page)
response = requests.get(url=url, headers=headers)
# 将字符串转为json格式
result = json.loads(response.text)
items = result['comments']
for item in items:
# 用户名
user_name = item['user']['nickname'].replace(',', ',')
# 用户ID
user_id = str(item['user']['userId'])
# 获取用户信息
user_message = get_user(user_id)
# 用户年龄
user_age = str(user_message['age'])
# 用户性别
user_gender = str(user_message['gender'])
# 用户所在地区
user_city = str(user_message['city'])
# 个人介绍
user_introduce = user_message['sign'].strip().replace('\n', '').replace(',', ',')
# 评论内容
comment = item['content'].strip().replace('\n', '').replace(',', ',')
# 评论ID
comment_id = str(item['commentId'])
# 评论点赞数
praise = str(item['likedCount'])
# 评论时间
date = time.localtime(int(str(item['time'])[:10]))
date = time.strftime("%Y-%m-%d %H:%M:%S", date)
print(user_name, user_id, user_age, user_gender, user_city, user_introduce, comment, comment_id, praise, date)
with open('music_comments.csv', 'a', encoding='utf-8-sig') as f:
f.write(user_name + ',' + user_id + ',' + user_age + ',' + user_gender + ',' + user_city + ',' + user_introduce + ',' + comment + ',' + comment_id + ',' + praise + ',' + date + '\n')
f.close()
def get_user(user_id):
"""
获取用户注册时间
"""
data = {}
url = 'https://music.163.com/api/v1/user/detail/' + str(user_id)
response = requests.get(url=url, headers=headers)
# 将字符串转为json格式
js = json.loads(response.text)
if js['code'] == 200:
# 性别
data['gender'] = js['profile']['gender']
# 年龄
if int(js['profile']['birthday']) < 0:
data['age'] = 0
else:
data['age'] = (2018 - 1970) - (int(js['profile']['birthday']) // (1000 * 365 * 24 * 3600))
if int(data['age']) < 0:
data['age'] = 0
# 城市
data['city'] = js['profile']['city']
# 个人介绍
data['sign'] = js['profile']['signature']
else:
data['gender'] = '无'
data['age'] = '无'
data['city'] = '无'
data['sign'] = '无'
return data
def main():
# 前500页
# for i in range(210000, 230000, 20):
# 后500页
for i in range(0, 25000, 20):
print('\n---------------第 ' + str(i // 20 + 1) + ' 页---------------')
get_comments(i)
if __name__ == '__main__':
main()
最后成功获取评论信息。
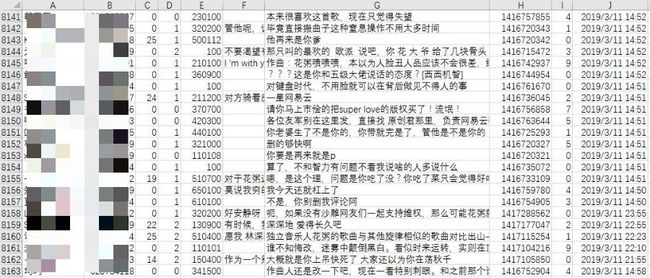
包含了用户名、用户ID、年龄、性别、区域编码、个人介绍、评论、评论ID、点赞数、评论发表时间。
按理说获取前500页,应该是有1w条的评论。
这里主要是因为大家刷的太快,页面信息一直在改变,所以必然会遗漏一些数据。

后500页还算完整的,就差了500条。
总共加起来1.7w条,数据量还是比较可观的,而且能发现不少信息。
/ 03 / 数据可视化
1 评论词云图


评论的词云图,经过抄袭风波,画风绝对不同。
第一张为歌曲发布后的评论词云,第二张为被爆抄袭后的评论词云。
前者是「喜欢」「好听」,后者却是「抄袭」「侵权」。
两相比较,真的天差地别。
2 评论用户的年龄分布
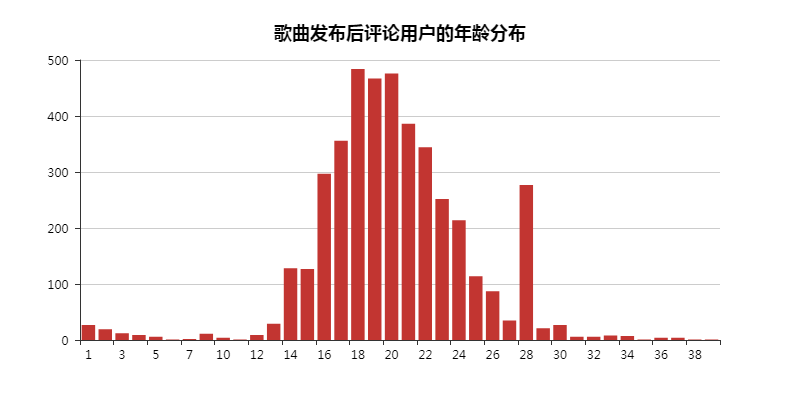
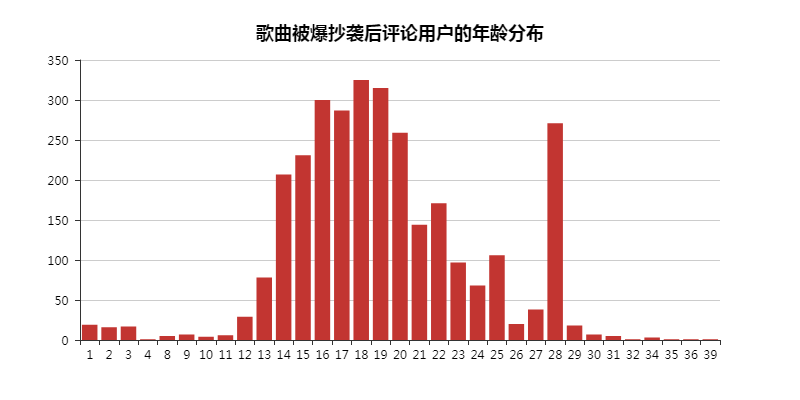
二者的评论用户年龄分布都差不多,大多集中在「14-25」。
这也符合网易云的定位,文艺小青年的聚集地。
其中「28」有异常情况出现,这里我是不清楚的...
3 评论用户的年龄分布
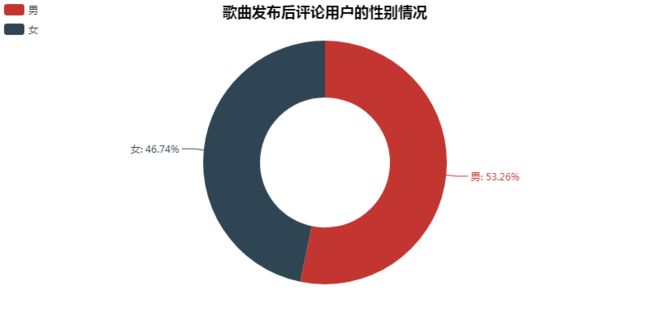
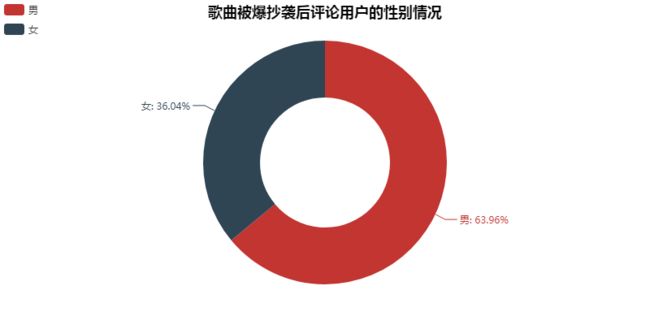
歌曲刚发布的时候,男女比例几乎为「1:1」。
在被爆抄袭后,评论里男性明显比女性多。
那么,这能说明什么呢?说明男的更耿直,更嫉恶如仇吗?
大学时的一位舍友特喜欢花粥,天天在放花粥的「老中医」。
那一句「姐是老中医 专治吹牛逼」,简直要把我耳朵听出茧来了。
每次我们都会吐槽这是什么**歌,真**难听...
哈哈,花粥的抄袭该不会伤到了他的心。
4 评论用户的地区分布
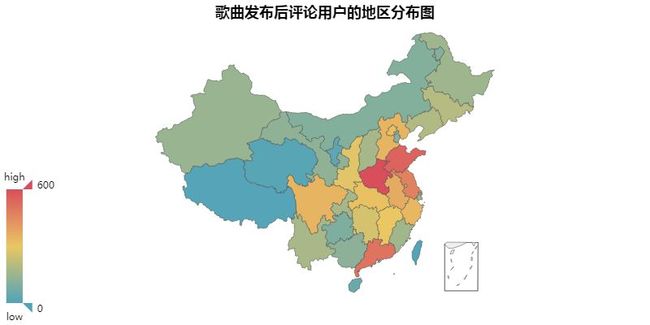

大体上差别不大,前后都是集中在「河南」「山东」「江苏」「广东」这几个地方。
无非就是,变一变评论用户最多省份。
5 评论的时间分布

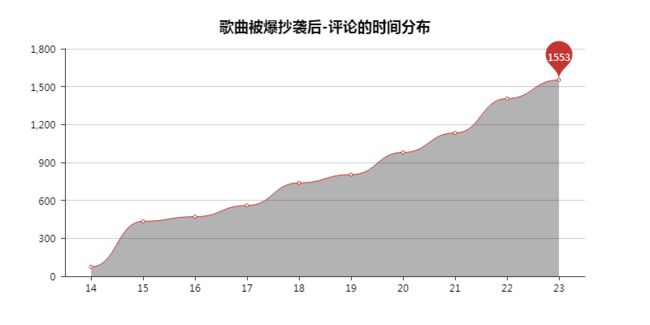
歌曲发布后,评论数以「13:00」这个时间点最高,这是因为歌曲是在那个时间点发布的。
大家都急着抢个前排,占个座,混个脸熟。
第二高峰就是大家所熟悉的黄金时间「19:00」。
被爆抄袭后的评论,评论数是一直在上升的。
8000多条评论,全部都是在3月11号,时间也都是在「14:00-23:00」。
一路飙升,一点没有下降的意思。
直到现在,评论区还在时时更新。
6 评论的日期分布
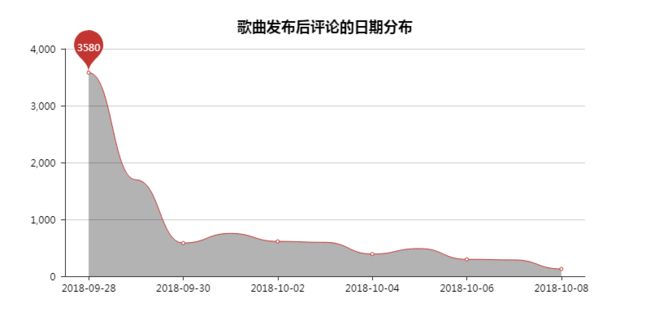
这里只看歌曲发布后的情况,因为最近的根本没法看。
大家都在疯狂刷评论,一天的评论已经远超1w条了。
第一天最多,慢慢的后面就下来了,这也是常态。
7 挖掘水军
最后来看一下谁的评论数最多,发现水军党啦!!!

这位用户果真花粥的铁粉,愣是刷了43条评论,其中还有一条评论点赞数四十几万。
其中红圈为评论ID,都不一样,说明评论都是唯一的,不重复。
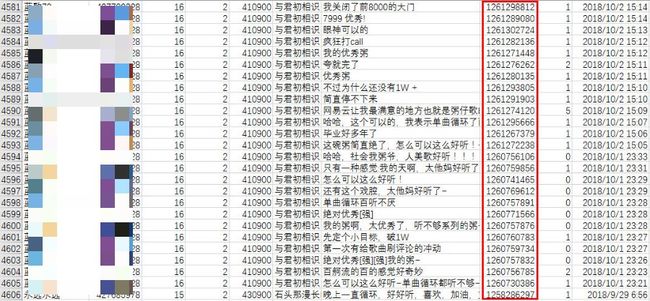
第二位用户,一共25条评论,不过她并没有点赞数多的。

第三位用户,一共24条评论,同样没有点赞数多的评论。
好了,列举三位花粥的铁粉,点到为止。
下面来看一下被爆抄袭后的评论用户。

这位用户愣是评论了99条,其中评论都是一样的,不信看上图,就是末尾变了。
妥妥的水军,疯狂复制粘贴。

这位用户,和评论区喷起来了...
一共94条评论。
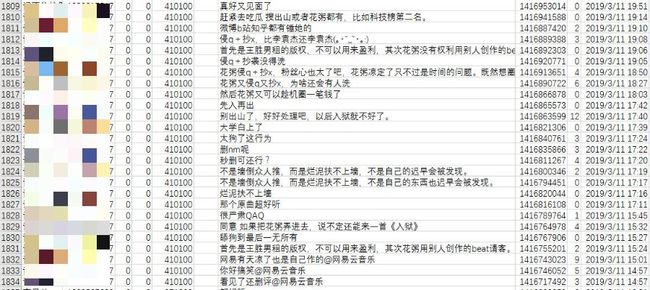
这位用户是狂喷类型的,一共69条评论。
好了点到为止,感兴趣的可以自己去操作一把。
由于用户信息相对隐私,我都打上马赛克了,仅供学习。
/ 04 / 总结
最后来看一下评论的反差(以点赞数为排序)。

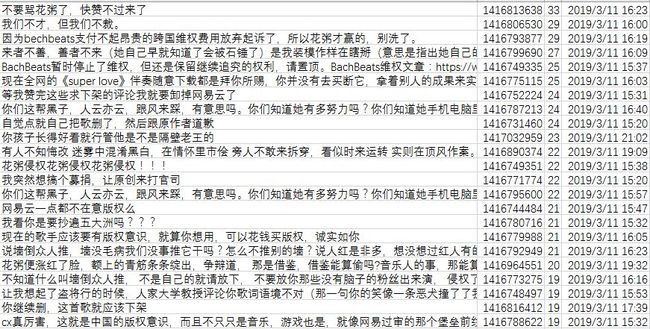
总而言之,一句话,且行且珍惜。
【本文作者】
法纳斯特:Python爱好者,专注爬虫,数据分析及可视化
推荐阅读
(点击标题可跳转阅读)
用 Python 全自动下载抖音小姐姐视频
太嚣张了!他竟用 Python 绕过了“验证码”
我用 Python 和 Twilio 实现自动化选课
觉得本文对你有帮助?请分享给更多人
关注「Python开发者」加星标,提升Python技能

喜欢就点一下「好看」呗~