基于bag of words的图像检索
引言
最初的Bag of words,也叫做“词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
现在的Bag of words来表示图像的特征描述也是很流行的。通过构建Bag of words模型了,生成特征词典,用这个n维的向量来表示这幅图像。对所有图像计算完成之后,就可以进行分类聚类训练预测之类的了。
基本步骤
第一阶段
(一)特征检测
(二)特征表示
(三)单词本的形成
1.利用SIFT算法,先从每类图像中提取独立的视觉词汇,再将所有的视觉词汇集合在一起。如下图,人脸,自行车,吉他三类图像提取出的特征词汇,可以看出,不同的种类,特征差别还是较大的。

2.对于集合的所有视觉词汇,利用K-Means算法构造单词表。K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。SIFT提取的视觉词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近的词汇合并,作为单词表中的基础词汇,假定我们将K设为4,那么单词表的构造过程如下图所示
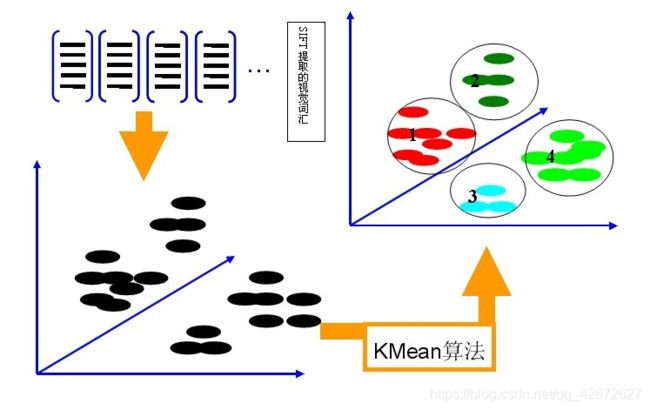
3.到这里,我们就算生成了“特征词汇词典”。接下来,我们要用“词汇词典”中的词汇来表示每一副图像。我们可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维(k的数值取决于你生成词典词汇的数量,在这边例子为4。实际应用中,为了达到较好的效果,单词表中的词汇数量K往往非常庞大,并且目标类数目越多,对应的K值也越大。这里取K=4仅仅是为了方便说明)数值向量。每副图像的直方图表示为如下:

第二阶段
1.图像检索
一般情况,对于给定输入图像的BOW直方图,在数据库中查找k个最近邻的图像,对于图像分类,可以根据k各近邻图像的分类标签投票获得分类结果,这在训练数据足以表述所有图像时,效果良好。
2.构建倒排索引,快速查询:
这边我们采用构建倒排索引(由属性值来确定记录的位置。)来检索图像。它通过用户给定的查询特征单词,用“单词–>图像”的方式从局部得到整体的查询方式。
3.根据索引结果进行直方图匹配,获得更加精确的结果。
代码及运行结果
1.开始前先将PCV包和SIFT文件放到代码目录下,如下图:

![]()
(1)提取特征,生成词汇:
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#提取文件夹下图像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
#生成词汇
voc = vocabulary.Vocabulary('ukbenchtest')
voc.train(featlist, 1000, 10)
#保存词汇
# saving vocabulary
with open('first1000/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print ('vocabulary is:', voc.name, voc.nbr_words)
运行如下:
(2)生成词汇词典,跑这代码之前需要安装python 的pysqlite库。这边给出下载地址:点击下载。代码:
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
# load vocabulary
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
#创建索引
indx = imagesearch.Indexer('testImaAdd.db',voc)
indx.create_tables()
# go through all images, project features on vocabulary and insert
#遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:1000]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
# commit to database
#提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print (con.execute('select count (filename) from imlist').fetchone())
print (con.execute('select * from imlist').fetchone())
运行后会生成一个db文件。
(3)图片查询:
# -*- coding: utf-8 -*-
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
# load image list and vocabulary
#载入图像列表
imlist = get_imlist('./test10/')
nbr_images = len(imlist)
#载入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
with open('./test10/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)
# index of query image and number of results to return
#查询图像索引和查询返回的图像数
q_ind = 0
nbr_results = 20
# regular query
# 常规查询(按欧式距离对结果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print('top matches (regular):', res_reg)
# load image features for query image
#载入查询图像特征
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
# RANSAC model for homography fitting
#用单应性进行拟合建立RANSAC模型
model = homography.RansacModel()
rank = {}
# load image features for result
#载入候选图像的特征
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1
# get matches
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
# compute homography, count inliers. if not enough matches return empty list
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
# store inlier count
rank[ndx] = len(inliers)
# sort dictionary to get the most inliers first
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print('top matches (homography):', res_geom)
# 显示查询结果
imagesearch.plot_results(src,res_reg[:8]) #常规查询
imagesearch.plot_results(src,res_geom[:8]) #重排后的结果
运行结果:

常规查询结果:

倒排查询:
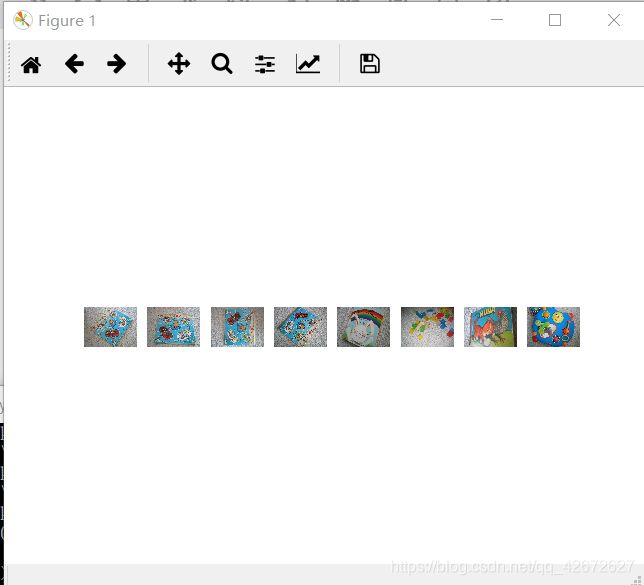
从上面运行结果上看,倒排和常规查询几乎一致,没啥区别。但在匹配图片量大的情况下,倒排匹配的结果会相对精确一点。