Task 3: Subword Models (附代码)(Stanford CS224N NLP with Deep Learning Winter 2019)
Task 3: Subword Models
目录
- Task 3: Subword Models
- 回顾:Word2vec & Glove
- 一、人类语言声音:语音学和音系学
- 二、字符级模型(Character-Level Models)
- 三、子词模型(Sub-word models)
- Byte Pair Encoding(BPE)
- 四、混合字符和词级模型
- 1、 Hybrid NMT
- 2、Chars for word embeddings
- 五、FastText
- fastText和word2vec的区别
- 实战
- 【参考资料】
理论部分
- 回顾 word2vec 和 glove,并介绍其所存在问题
- 介绍 n-gram 思想
- 介绍 FastText 模型

回顾:Word2vec & Glove
Glove (global vectors for word representation) 与word2vec,两个模型都可以根据词汇的 “共现 co-occurrence” 信息,将词汇编码成一个向量(所谓共现,即语料中词汇一起出现的频率)。
两者最直观的区别在于,word2vec是 “predictive” 的模型,而GloVe是 “count-based” 的模型。
Glove 和 word2vec 从算法实现的角度来说,它们区别在于loss的计算是不同的。
对于原生的word2vec,其loss是交叉熵损失;
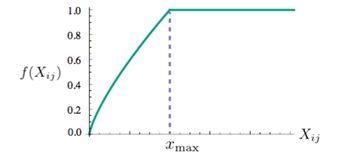
对于Glove来说,其需要先构建一个共现矩阵X,其中的 Xij 表示 i 和 j共同出现的次数,其loss为如下的公式。

f(x) 是一个权重函数,当 Xij 等于0的时候,f(x) = 0,并且当 Xij 过大的时候,f(x) = 1。

之前介绍的模型都是基于词向量的, 自然我们就会想到能不能换一个角度来表示语言。说英文的时候, 每个单词都是由音节构成的, 而人们听到了连续的音节就可以理解其中的含义, 而音节显然比词粒度更细. 我们想想再word-level存在的几个问题:
- 需要系统需要极大的词汇量;
- 如果遇到了不正式的拼写, 系统很难进行处理;
- 做翻译问题时, 音译姓名比较难做到。
为了解决这些问题, 那就可以考虑Subword Models了。
一、人类语言声音:语音学和音系学
- 语音学(Phonetics)是一种非常基本的理论,只要是正常人,有着相同的人体器官和相同的发声结构,就会遵循着相同的发声规则和原理。
- 语音体系(Phonology)是有语义的声音的合集,各国各文明的人都会制定自己的语音体系。
- 音素(Phoneme)是语音中划分出来的最小的语音单位,分为元音和辅音
国际音标(由音素构成)按理来说可以表示所有的语音,但是会发现好多语音是没有语义的,这时我们采取的办法就是看音素的下一级(part of words)。

词法学:一个n-grams的代替方案
在基于单词的模型中存在一些问题:
需要处理很大的词汇表,在英语中单词只要变个形态就是另一个单词了,比如说:gooooood bye
二、字符级模型(Character-Level Models)
通常针对字符级的模型有两种处理思路:一种是把原有的词向量分解处理,一种是把连接的语言分解成字符。

单词嵌入可以由字符嵌入表示:
- 能为不知道的单词生成嵌入
- 相似的拼写有相似的嵌入
- 解决了oov问题
这两种方法都被证明是成功的。后续也有很多的工作使用字符级的模型来解决NMT任务。但这些任务有一些共同的缺点,由于从单词替换成字符导致处理的序列变长,速度变慢;由于序列变长,数据变得稀疏,数据之间的联系的距离变大,不利于学习。于是2017年,Jason Lee, Kyunghyun Cho, Thomas Hoffmann发表了论文Fully Character-Level Neural Machine Translation without Explicit Segmentation 解决了这些问题。
论文的模型结构如图所示:
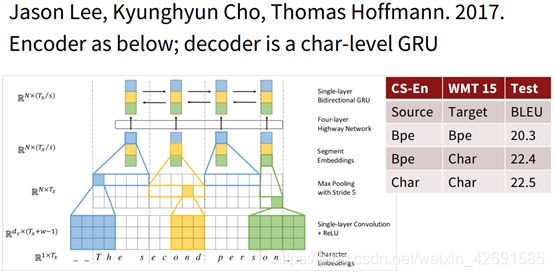
首先是对输入的character首先做一个embedding, 然后分别与大小为3,4,5的filter进行卷积运算,就相当于3-grams, 4-grams和5-grams。之后进行max-pooling操作,相当与选出了有语义信息的segment-embedding。之后将这些embedding送入Highway Network(相当于resnet, 解决了深层神经网络不容易训练的问题)后再通过一个单层的双向GRU,得到最终的encoder的output。之后经过一个character-level的GRU(作为decoder)得到最终结果。
还有一篇2018年的文章(Revisiting Character-Based Neural Machine Translation with Capacity and Compression. 2018.Cherry, Foster, Bapna, Firat, Macherey, Google AI)中展示了纯字符级模型的效果。此论文表明在一些复杂的语言中(比如捷克语),character级别的模型会大幅提高翻译准确率,但在较为简单的语言中(如英语法语),character级别的模型提升效果不显著。同时,研究发现在模型较小时word-level的模型效果更好,在模型较大时character-level 的效果更好。如图所示:
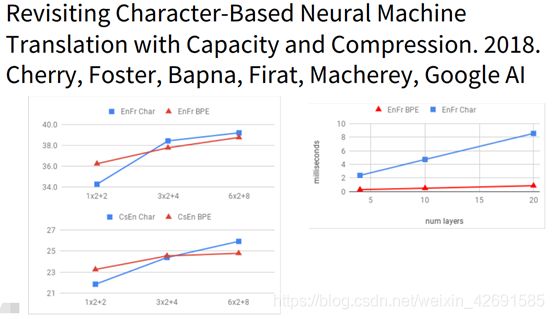
总之,现有的character-level的模型在NMT任务上可以更好的处理OOV的问题,可以理解为我们可以学习一些字符级别的语义信息帮助我们进行翻译。
三、子词模型(Sub-word models)
所谓subword,就是取一个介于字符和单词之间成分为基本单元建立的模型。而所谓Byte Pair Encoding(一下简称BPE),就是寻找经常出现在一起的Byte对,合并成一个新的Byte加入词汇库中。即若给定了文本库,若我们的初始词汇库包含所有的单个字符,则我们会不断的将出现频率最高的n-gram的pair作为新的n-gram加入词汇库中,直到达到我们的要求。
课程在这里介绍了介于word-level和char-leval之间的Sub-word models,主要一般有两种结构,一种是仍采用和word-level相同的结构,只不过采用更小的单元word pieces来代替单词;另一种是hybrid architectures, 主要部分依然是基于word, 但是其他的一些部分用characters。

Hybrid architectures:主要的模型含有单词,一些其他的含有字符、字节对的编码。
使用的是一个压缩算法:将大部分频繁出现的字节对标记为新的字节对。
Byte Pair Encoding(BPE)
Byte Pair Encoding,简称BPE,是一种压缩算法。
给定了文本库,我们的初始词汇库仅包含所有的单个的字符,然后不断的将出现频率最高的n-gram pair作为新的n-gram加入到词汇库中,直到词汇库的大小达到我们所设定的某个目标为止。如图所示:




上述例子是,比如有一个初始的文本库和词汇库。首先,可见此时出现频率最高的n-gram pair是“e,s”,出现了9次,因此我们将“es”作为新词加入到词汇库中同时更新文本库。然后,这时词汇库中出现频率最高的n-gram pair是“es,t”,出现了9次,因此我们将“est”加入词汇库中同时更新文本库。依次类推,可以逐渐的通过增加新的n-gram的方式达到我们的目标。对于现实生活中有很多词汇量非常大的task,这种通过BPE逐步建立词汇库的方式就显得非常有用了。
使用这种方法可以自动生成vocab。
谷歌的NMT模型有两个版本,版本一采用的是BPE模型,版本二对BPE模型进行了改进,称为wordpiece mode。这种方法不在使用n-gram的计算来算,而是使用搜索算法搜索最大化的该语言模型的片段去选择pieces。

另外还有一种模型叫sentence piece,它直接从raw text中获取,同时把空格视为一种特殊的token(_)

课程介绍了几篇在这方面发展的论文,有用Character-level去产生词向量的(Learning Character-level Representations for Part-of Speech Tagging),还有用char-level结合high-way网络进行机器翻译的。
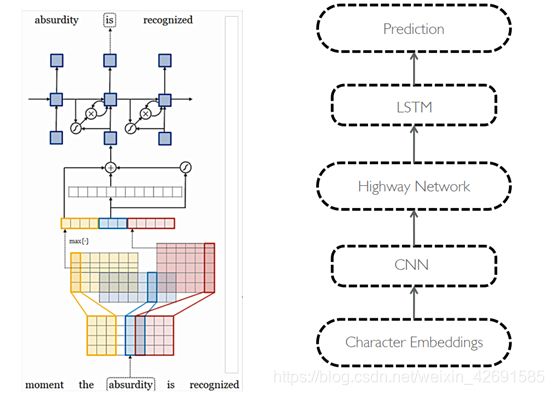
课程分析用char-level得到词向量的特点,经由他们直接输出的word-embedding更倾向于在形状上相似,输入high-way之后,形状上的相似会朝含义上的相似发展。如图所示:

使用char-level的可以轻易解决,此没有出现在词库的情况,如图所示:

四、混合字符和词级模型
1、 Hybrid NMT
核心思想:大部分时候都使用word-level的模型来做translate,只有在遇到rare or unseen的words的时候才会使用character-level的模型协助。这种做法产生了非常好的效果。
混合模型即两种方式并存的模型,在正常处理时采用word-level的模型,当出现奇怪的词的后,使用char-level级的模型。

一篇论文的结构如图所示:

可以看到输入未知的单词时,采用char-level进行编码,输出< unk >时也采用char-level级的进行解码。同时训练跟beam-search也时要同时对两个结构进行。
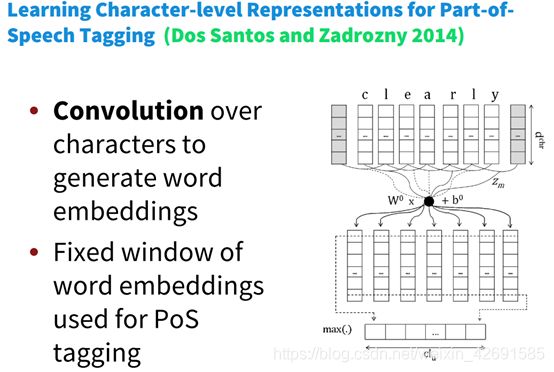
2、Chars for word embeddings
采用subword的方式长生词向量,课程中提到了FastText。主要思路如图所示:
- 字符的卷积来生成词嵌入
- 使用pos标记固定的窗口
五、FastText
使用n-grams和整个单词来代表单词。
我们知道在word2vec方法中我们基于word-level的模型来得到每一个单词的embedding,但是对于含有许多OOV单词的文本库word2vec的效果并不好。由此很容易联想到,如果将subword的思想融入到word2vec中是不是会产生更好的效果呢?
FastText embeddings是一个word2vec like embedding。用where举例, 它把单词表示成了: "where =

然后把它们加起来:
![]()
于是,就可以使用原有的word2vec算法来训练得到对应单词的embedding。其保证了算法速度快的同时,解决了OOV的问题,是很好的算法。
fastText和word2vec的区别
• 相似处:
- 图模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。
- 都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
• 不同处:
- 模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用。
- 模型的输入层:word2vec的输出层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容。
• 两者本质的不同,体现在 h-softmax的使用:
- Word2vec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax也会生成一系列的向量,但最终都被抛弃,不会使用。
- fastText则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)
fastText是一个能用浅层网络取得和深度网络相媲美的精度,并且分类速度极快的算法。按照作者的说法“在标准的多核CPU上,能够训练10亿词级别语料库的词向量在10分钟之内,能够分类有着30万多类别的50多万句子在1分钟之内”。但是它也有自己的使用条件,它适合类别特别多的分类问题,如果类别比较少,容易过拟合。
实战
model.py
# coding: utf8
import torch
import torch.nn as nn
from data_utils import START_TAG_IDX, STOP_TAG_IDX, PAD_IDX
from utils import scalar, LongTensor, Tensor, zeros, randn
WORD_EMBEDDING_DIM = 300
WORD_LSTM_HIDDEN_SIZE = 600
WORD_LSTM_NUM_LAYERS = 1
WORD_LSTM_BIDIRECTIONAL = True
WORD_LSTM_NUM_DIRS = 2 if WORD_LSTM_BIDIRECTIONAL else 1
CHAR_EMBEDDING_DIM = 100
CHAR_LSTM_HIDDEN_SIZE = 200
CHAR_LSTM_NUM_LAYERS = 1
CHAR_LSTM_BIDIRECTIONAL = True
CHAR_LSTM_NUM_DIRS = 2 if CHAR_LSTM_BIDIRECTIONAL else 1
def _sort(_2dtensor, lengths, descending=True):
sorted_lengths, order = lengths.sort(descending=descending)
_2dtensor_sorted_by_lengths = _2dtensor[order]
return _2dtensor_sorted_by_lengths, order
class CRFOnLSTM(nn.Module):
def __init__(
self,
num_word_embeddings,
num_tags,
word_embeddings,
num_char_embeddings,
word_lstm,
char_lstm):
super(CRFOnLSTM, self).__init__()
self.lstm = WordCharLSTM(
num_word_embeddings,
num_tags,
word_embeddings,
num_char_embeddings,
word_lstm=word_lstm,
char_lstm=char_lstm)
self.crf = CRF(num_tags)
self = self.cuda() if torch.cuda.is_available() else self
def forward(self, word_x, char_x, y): # for training
mask = word_x.data.gt(0).float() # because 0 is pad_idx, doesn't really belong here, I guess
h = self.lstm(word_x, mask, char_x)
Z = self.crf.forward(h, mask) # partition function
score = self.crf.score(h, y, mask)
return Z - score # NLL loss
def decode(self, word_x, char_x): # for prediction
mask = word_x.data.gt(0).float() # again 0 is probably because of pad_idx, maybe pass mask as parameter
h = self.lstm(word_x, mask, char_x)
return self.crf.decode(h, mask)
class WordCharLSTM(nn.Module):
def __init__(
self,
num_word_embeddings,
num_tags,
word_embeddings,
num_char_embeddings,
word_lstm,
char_lstm,
char_padding_idx=0,
train_word_embeddings=False):
super(WordCharLSTM, self).__init__()
self.char_embeddings = nn.Embedding(
num_embeddings=num_char_embeddings,
embedding_dim=CHAR_EMBEDDING_DIM,
padding_idx=char_padding_idx)
self.word_embeddings = nn.Embedding(
num_embeddings=num_word_embeddings,
embedding_dim=WORD_EMBEDDING_DIM,
padding_idx=PAD_IDX,
_weight=word_embeddings)
if word_embeddings:
self.word_embeddings.weight.requires_grad = train_word_embeddings
self.char_lstm = char_lstm
self.embedding_dropout = nn.Dropout(0.3)
self.word_lstm = word_lstm
self.output_dropout = nn.Dropout(0.3)
self.out = nn.Linear(WORD_LSTM_HIDDEN_SIZE, num_tags)
nn.init.xavier_uniform_(self.out.weight)
for name, param in self.word_lstm.named_parameters():
if 'weight' in name:
nn.init.xavier_uniform_(param)
for name, param in self.char_lstm.named_parameters():
if 'weight' in name:
nn.init.xavier_uniform_(param)
# TODO : maybe other initialization methods?
def init_hidden(self, batch_size): # initialize hidden states
h = zeros(WORD_LSTM_NUM_LAYERS * WORD_LSTM_NUM_DIRS,
batch_size,
WORD_LSTM_HIDDEN_SIZE // WORD_LSTM_NUM_DIRS) # hidden states
c = zeros(WORD_LSTM_NUM_LAYERS * WORD_LSTM_NUM_DIRS,
batch_size,
WORD_LSTM_HIDDEN_SIZE // WORD_LSTM_NUM_DIRS) # cell states
return (h, c)
def forward(self, word_x, mask, char_x):
char_output = self._char_forward(char_x)
batch_size = word_x.size(0)
max_seq_len = word_x.size(1)
char_output = char_output.reshape(batch_size, max_seq_len, -1) # last dimension is for char lstm hidden size
word_x = self.word_embeddings(word_x)
word_x = torch.cat([word_x, char_output], -1)
word_x = self.embedding_dropout(word_x)
initial_hidden = self.init_hidden(batch_size) # batch size is first
word_x = nn.utils.rnn.pack_padded_sequence(word_x, mask.sum(1).int(), batch_first=True)
output, hidden = self.word_lstm(word_x, initial_hidden)
output, recovered_lengths = nn.utils.rnn.pad_packed_sequence(output, batch_first=True)
output = self.output_dropout(output)
output = self.out(output) # batch x seq_len x num_tags
output *= mask.unsqueeze(-1) # mask - batch x seq_len -> batch x seq_len x 1
return output
def _char_forward(self, x):
word_lengths = x.gt(0).sum(1) # actual word lengths
sorted_padded, order = _sort(x, word_lengths)
embedded = self.char_embeddings(sorted_padded)
word_lengths_copy = word_lengths.clone()
word_lengths_copy[word_lengths == 0] = 1
packed = torch.nn.utils.rnn.pack_padded_sequence(embedded, word_lengths_copy[order], True)
packed_output, _ = self.char_lstm(packed)
output, _ = torch.nn.utils.rnn.pad_packed_sequence(packed_output, True)
_, reverse_sort_order = torch.sort(order, dim=0)
output = output[reverse_sort_order]
indices_of_lasts = (word_lengths_copy - 1).unsqueeze(1).expand(-1, output.shape[2]).unsqueeze(1)
output = output.gather(1, indices_of_lasts).squeeze()
output[word_lengths == 0] = 0
return output
class CRF(nn.Module):
def __init__(self, num_tags):
super(CRF, self).__init__()
self.num_tags = num_tags
# matrix of transition scores from j to i
self.transition = nn.Parameter(randn(num_tags, num_tags))
self.transition.data[START_TAG_IDX, :] = -10000. # no transition to START
self.transition.data[:, STOP_TAG_IDX] = -10000. # no transition from END except to PAD
self.transition.data[:, PAD_IDX] = -10000. # no transition from PAD except to PAD
self.transition.data[PAD_IDX, :] = -10000. # no transition to PAD except from END
self.transition.data[PAD_IDX, STOP_TAG_IDX] = 0.
self.transition.data[PAD_IDX, PAD_IDX] = 0.
def forward(self, h, mask):
# initialize forward variables in log space
alpha = Tensor(h.shape[0], self.num_tags).fill_(-10000.) # [B, S]
# TODO: pytorch tutorial says wrap it in a variable to get automatic backprop, do we need it here? to be checked
alpha[:, START_TAG_IDX] = 0.
transition = self.transition.unsqueeze(0) # [1, S, S]
for t in range(h.size(1)): # iterate through the sequence
mask_t = mask[:, t].unsqueeze(1)
emission = h[:, t].unsqueeze(2) # [B, S, 1]
alpha_t = log_sum_exp(alpha.unsqueeze(1) + emission + transition) # [B, 1, S] -> [B, S, S] -> [B, S]
alpha = alpha_t * mask_t + alpha * (1 - mask_t)
Z = log_sum_exp(alpha + self.transition[STOP_TAG_IDX])
return Z # partition function
def score(self, h, y, mask): # calculate the score of a given sequence
batch_size = h.shape[0]
score = Tensor(batch_size).fill_(0.)
# TODO: maybe instead of unsqueezing following two separately do it after sum in line for score calculation
# TODO: check if unsqueezing needed at all
h = h.unsqueeze(3)
transition = self.transition.unsqueeze(2)
y = torch.cat([LongTensor([START_TAG_IDX]).view(1, -1).expand(batch_size, 1), y], 1) # add start tag to begin
# TODO: the loop can be vectorized, probably
for t in range(h.size(1)): # iterate through the sequence
mask_t = mask[:, t]
emission = torch.cat([h[i, t, y[i, t + 1]] for i in range(batch_size)])
transition_t = torch.cat([transition[seq[t + 1], seq[t]] for seq in y])
score += (emission + transition_t) * mask_t
# get transitions from last tags to stop tag: use gather to get last time step
lengths = mask.sum(1).long()
indices = lengths.unsqueeze(1) # we can safely use lengths as indices, because we prepended start tag to y
last_tags = y.gather(1, indices).squeeze()
score += self.transition[STOP_TAG_IDX, last_tags]
return score
def decode(self, h, mask): # Viterbi decoding
# initialize backpointers and viterbi variables in log space
backpointers = LongTensor()
batch_size = h.shape[0]
delta = Tensor(batch_size, self.num_tags).fill_(-10000.)
delta[:, START_TAG_IDX] = 0.
# TODO: is adding stop tag within loop needed at all???
# pro argument: yes, backpointers needed at every step - to be checked
for t in range(h.size(1)): # iterate through the sequence
# backpointers and viterbi variables at this timestep
mask_t = mask[:, t].unsqueeze(1)
# TODO: maybe unsqueeze transition explicitly for 0 dim for clarity
next_tag_var = delta.unsqueeze(1) + self.transition # B x 1 x S + S x S
delta_t, backpointers_t = next_tag_var.max(2)
backpointers = torch.cat((backpointers, backpointers_t.unsqueeze(1)), 1)
delta_next = delta_t + h[:, t] # plus emission scores
delta = mask_t * delta_next + (1 - mask_t) * delta # TODO: check correctness
# for those that end here add score for transitioning to stop tag
if t + 1 < h.size(1):
# mask_next = mask[:, t + 1].unsqueeze(1)
# ending = mask_next.eq(0.).float().expand(batch_size, self.num_tags)
# delta += ending * self.transition[STOP_TAG_IDX].unsqueeze(0)
# or
ending_here = (mask[:, t].eq(1.) * mask[:, t + 1].eq(0.)).view(1, -1).float()
delta += ending_here.transpose(0, 1).mul(self.transition[STOP_TAG_IDX]) # add outer product of two vecs
# TODO: check equality of these two again
# TODO: should we add transition values for getting in stop state only for those that end here?
# TODO: or to all?
delta += mask[:, -1].view(1, -1).float().transpose(0, 1).mul(self.transition[STOP_TAG_IDX])
best_score, best_tag = torch.max(delta, 1)
# back-tracking
backpointers = backpointers.tolist()
best_path = [[i] for i in best_tag.tolist()]
for idx in range(batch_size):
prev_best_tag = best_tag[idx] # best tag id for single instance
length = int(scalar(mask[idx].sum())) # length of instance
for backpointers_t in reversed(backpointers[idx][:length]):
prev_best_tag = backpointers_t[prev_best_tag]
best_path[idx].append(prev_best_tag)
best_path[idx].pop() # remove start tag
best_path[idx].reverse()
return best_path
def create_crf_on_lstm_model(
word_vocab_size,
tag_vocab_size,
char_vocab_size,
word_embeddings):
char_lstm = nn.LSTM(
input_size=CHAR_EMBEDDING_DIM,
hidden_size=CHAR_LSTM_HIDDEN_SIZE // CHAR_LSTM_NUM_DIRS,
num_layers=CHAR_LSTM_NUM_LAYERS,
bias=True,
batch_first=True,
bidirectional=CHAR_LSTM_BIDIRECTIONAL)
word_lstm = nn.LSTM(
input_size=WORD_EMBEDDING_DIM + CHAR_LSTM_HIDDEN_SIZE,
hidden_size=WORD_LSTM_HIDDEN_SIZE // WORD_LSTM_NUM_DIRS,
num_layers=WORD_LSTM_NUM_LAYERS,
bias=True,
batch_first=True,
bidirectional=WORD_LSTM_BIDIRECTIONAL)
return CRFOnLSTM(
word_vocab_size,
tag_vocab_size,
torch.tensor(word_embeddings, dtype=torch.float) if word_embeddings else None,
char_vocab_size,
word_lstm,
char_lstm)
def log_sum_exp(x):
m = torch.max(x, -1)[0]
return m + torch.log(torch.sum(torch.exp(x - m.unsqueeze(-1)), -1))
训练模型:
CRFOnLSTM(
(lstm): WordCharLSTM(
(char_embeddings): Embedding(85, 100, padding_idx=0)
(word_embeddings): Embedding(26124, 300, padding_idx=0)
(char_lstm): LSTM(100, 100, batch_first=True, bidirectional=True)
(embedding_dropout): Dropout(p=0.3)
(word_lstm): LSTM(500, 300, batch_first=True, bidirectional=True)
(output_dropout): Dropout(p=0.3)
(out): Linear(in_features=600, out_features=11, bias=True)
)
(crf): CRF()
)
training model…
完整代码github地址:https://github.com/chenlian-zhou/nlp/tree/master/pytorch-bilstm-crf-master
【参考资料】
斯坦福cs224n-2019链接:https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/
bilibili 视频:https://www.bilibili.com/video/BV1s4411N7fC?p=2