Pandas中resample方法详解,处理datetime 分时间段统计问题
Pandas中的resample,重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。
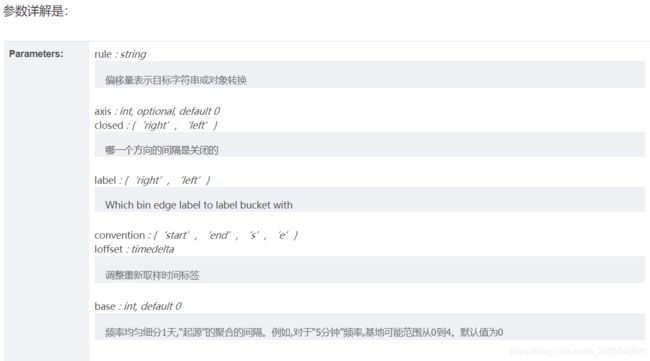
方法的格式是:
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention=‘start’,kind=None, loffset=None, limit=None, base=0)
#如果需要的话,需将df中的date列转为datetime
df.date = pd.to_datetime(df.date,format="%Y%m%d")
#将改好格式的date列,设置为df的index
df.set_index(‘date’,drop=True)
#按年来提数据 (因为此时的datetime已经为index了,可以直接[]取行内容)
df[‘2018’]
df[‘2018’:‘2021’]
#按月来提数据
df[‘2018-01’]
df[‘2018-01’:‘2018-05’]
#按天来提出数据
df[‘2018-05-24’:‘2018-09-27’]
resample方法处理时间序列问题
#按日期汇总数据
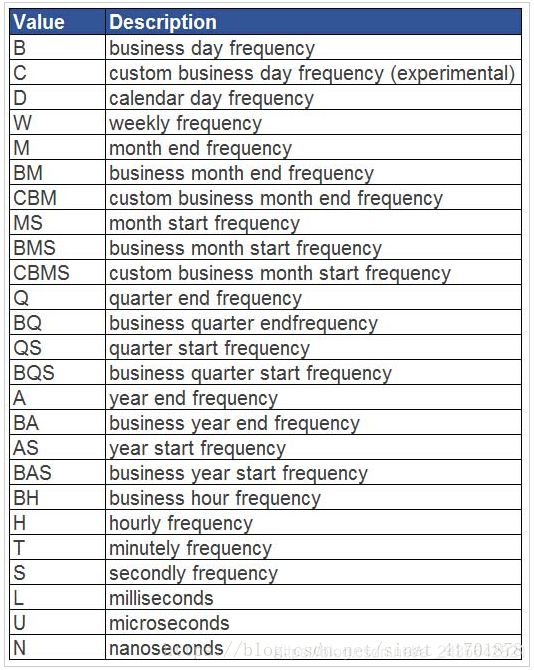
#将数据以W星期,M月,Q季度,QS季度的开始第一天开始,A年,10A十年,10AS十年聚合日期第一天开始.的形式进行聚合
df.resample(‘W’).sum()
df.resample(‘M’).sum()
#具体某列的数据聚合
df.price.resample(‘W’).sum().fillna(0) #星期聚合,以0填充NaN值
#某两列
df[[‘price’,‘num’]].resample(‘W’).sum().fillna(0)
#某个时间段内,以W聚合,
df[“2018-5”:“2018-9”].resample(“M”).sum().fillna(0)
还有以下方式聚合
其它参数讲解
首先创建一个Series,采样频率为一分钟。
>>> index = pd.date_range('1/1/2000', periods=9, freq='T')
>>> series = pd.Series(range(9), index=index)
>>> series
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
Freq: T, dtype: int64
降低采样频率为三分钟
>>> series.resample('3T').sum()
2000-01-01 00:00:00 3
2000-01-01 00:03:00 12
2000-01-01 00:06:00 21
Freq: 3T, dtype: int64
降低采样频率为三分钟,但是每个标签使用right来代替left。请注意,bucket中值的用作标签。
>>> series.resample('3T', label='right').sum()
2000-01-01 00:03:00 3
2000-01-01 00:06:00 12
2000-01-01 00:09:00 21
Freq: 3T, dtype: int64
降低采样频率为三分钟,但是关闭right区间。
>>> series.resample('3T', label='right', closed='right').sum()
2000-01-01 00:00:00 0
2000-01-01 00:03:00 6
2000-01-01 00:06:00 15
2000-01-01 00:09:00 15
Freq: 3T, dtype: int64
增加采样频率到30秒
>>> series.resample('30S').asfreq()[0:5] #select first 5 rows
2000-01-01 00:00:00 0
2000-01-01 00:00:30 NaN
2000-01-01 00:01:00 1
2000-01-01 00:01:30 NaN
2000-01-01 00:02:00 2
Freq: 30S, dtype: float64
增加采样频率到30S,使用pad方法填充nan值。
>>> series.resample('30S').pad()[0:5]
2000-01-01 00:00:00 0
2000-01-01 00:00:30 0
2000-01-01 00:01:00 1
2000-01-01 00:01:30 1
2000-01-01 00:02:00 2
Freq: 30S, dtype: int64
增加采样频率到30S,使用bfill方法填充nan值。
>>> series.resample('30S').bfill()[0:5]
2000-01-01 00:00:00 0
2000-01-01 00:00:30 1
2000-01-01 00:01:00 1
2000-01-01 00:01:30 2
2000-01-01 00:02:00 2
Freq: 30S, dtype: int64
通过apply运行一个自定义函数
>>> def custom_resampler(array_like):
... return np.sum(array_like)+5
>>> series.resample('3T').apply(custom_resampler)
2000-01-01 00:00:00 8
2000-01-01 00:03:00 17
2000-01-01 00:06:00 26
Freq: 3T, dtype: int64