[论文阅读]DenseBox: Unifying Landmark Localization with End to End Object Detection
文章目录
- contribution
- DenseBox for Detection
- ground truth生成
- 模型设计
- 多任务训练
- 平衡采样
- 结合关键点的模型
- 对比
contribution
(1)使用全卷积网络进行目标检测任务,并可以准确有效的检测多个对象
(2)多任务学习中使用landmark localization会进一步提高目标检测准确性
DenseBox for Detection
测试时,系统将图像(m×n)作为输出,输出m/4 * n/4 的5通道特征图,ground truth是左上角点 p t = ( x t , y t ) p_t =(x_t,y_t) pt=(xt,yt)和右下角 p b = ( x b , y b ) p_b =(x_b,y_b) pb=(xb,yb),输出特征图 x i , y i x_i,y_i xi,yi的5通道表示 { s , d x t = x i − x t , d y t = y i − y t , d x b = x i − x b , d y b = y i − y b } \{s,dx^t = x_i - x_t ,dy^t = y_i -y_t,dx^b = x_i - x_b,dy^b = y_i - y_b\} {s,dxt=xi−xt,dyt=yi−yt,dxb=xi−xb,dyb=yi−yb},s是置信度得分,dx之类表示偏移距离
ground truth生成
没有必要将整个图像放入网络进行训练,因为在背景上进行卷积需要花费大部分计算时间。一个明智的策略是裁剪包含面部的大块补丁和足够的背景信息进行训练。
一般来说,网络使用类似分割的方式进行训练,训练阶段,patch被裁剪出来,并被resize成240×240大小,中心人脸大致高度为50 像素。训练中输出ground truth标签是5通道特征图,大小为60*60。ground truth并没有使用矩形框,而是使用半径为 r c r_c rc的实心圆, r c r_c rc是bounding box的0.3倍,后面4个维度存储像素点到最近ground truth的四个边界的距离???
注意:可能一个patch会出现多个人脸,如果人脸落在中心人脸的.8~1.25处认为是正样本,否则是负样本?????
![[论文阅读]DenseBox: Unifying Landmark Localization with End to End Object Detection_第1张图片](http://img.e-com-net.com/image/info8/b4cefca2b41f47d08b4c5469a5f26573.jpg)
模型设计
参考VGG 19,一共16个卷积层,前12个卷积层由VGG 19预训练模型初始化,conv4_4会被送到4个1×1卷积层,前两个卷积层输出一通道特征图进行类别损失,后两个卷积层输出4通道特征图进行边界框回归
![[论文阅读]DenseBox: Unifying Landmark Localization with End to End Object Detection_第2张图片](http://img.e-com-net.com/image/info8/bf92d980cf734953a8be276d447092ba.jpg)
多级特征融合
连接conv 3_4 conv 4_4,conv3_3的感受野是48×48几乎与训练的人脸大小相同,而conv4_4有较大感受野,大约为118×118,使用双线型上采样层使得他们转换为相同分辨率
多任务训练
分类损失用L2损失,ground turth y 属于{0,1},公式如下,论文提到L2损失在实验中表现比hinge loss和交叉熵损失要好
![]()
回归损失,预测偏移值与真实偏移值的L2损失
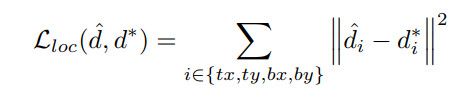
平衡采样
选择负样本是学习很重要的一部分,如果在mini-batch中使用全部的负样本会使得预测偏向负样本,因为负样本占主导地位。此外如果惩罚位于正样本和负样本趋于边缘,检测器会退化。我们对每个输出像素使用二进制mask表示它是否在训练中被选中。
忽略灰色区域
灰色区域定义是正样本和负样本的边缘,它应该被认为既不是正样本也不是负样本,并且loss weight应设置为0。在论文中,长度小于2的边界部分视为灰色区域。DenseBox使用 f i g n f_{ign} fign 对灰色样本进行标注, f i g n = 1 f_{ign}=1 fign=1 表示为灰色区域样本。
难样本挖掘
DenseBox使用的Hard Negative Mining的策略和SVM类似,具体策略是:
计算整个patch的3600个所有样本点,并根据loss进行排序;
取其中的1%,也就是36个作为hard-negative样本;
随机采样36个负样本和hard-negative构成72个负样本;
随机采样72个正样本。
使用上面策略得到的144个样本参与训练,DensoBox使用掩码 f s e l f_{sel} fsel 对参与训练的样本点进行标注:样本被选中 f s e l f_{sel} fsel=1 ,否则 f s e l f_{sel} fsel=0
** 使用mask的loss**
损失函数使用掩码来控制哪些样本参与训练,其掩码 M ( t ^ i ) M(\hat{t}_i) M(t^i) 是由灰色样本区域的 f i g n f_{ign} fign 和男样本挖掘的 f s e l f_{sel} fsel 共同决定的
![[论文阅读]DenseBox: Unifying Landmark Localization with End to End Object Detection_第3张图片](http://img.e-com-net.com/image/info8/ce1bda8f99bb48e89e1d3f79bf9136e5.jpg)
使用掩码后,得到的损失函数如下
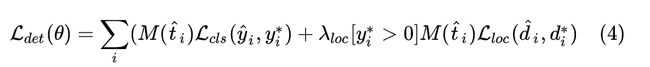
其中 θ \theta θ 为卷积网络的参数, [ y i ∗ > 0 ] [y^*_i>0] [yi∗>0] 表示只有正样本参与bounding box的训练
λ l o c \lambda_loc λloc平衡分类损失和回归损失,实验中取3会很work
其他实施细节
训练中,如果只送正patch,那么负样本仅仅是对象附近的负样本,为了充分探索整个数据集的负样本。还从训练图像随机裁剪补丁,并调整为相同大小送入网络,这种patch我们成为随机patch,训练中正patch和随机patch比例为1:1.为了提高鲁棒性会对对每个patch进行抖动,例如左右反转,平移,缩放变形
结合关键点的模型
![[论文阅读]DenseBox: Unifying Landmark Localization with End to End Object Detection_第4张图片](http://img.e-com-net.com/image/info8/c517630222064c02a52726b00ecfe452.jpg)
假设样本有 N 个关键点(在MALF中 N=72 ),DenseBox的关键点检测的输出是 N 个热图,热图中的每个像素点表示改点为对应位置关键点的置信度。
关键点的标签值的生成方式也很简单,对于标签集中的第i个关键点 (x,y) ,在第i个feature map在 (x,y) 处的值是1,其它位置为0
对比
对比faster rcnn:densebox 没有anchor box
对比yolo:densebox可以检测小目标和高度重叠的对象