职业爬虫师进阶之路,可视化爬虫监控系统

阅读文本大概需要 14 分钟。
# 1. 前言
本文并不是讲解爬虫的相关技术实现的,而是从实用性的角度,将抓取并存入 MongoDB 的数据 用 InfluxDB 进行处理,而后又通过 Grafana 将爬虫抓取数据情况通过酷炫的图形化界面展示出来。
在开始之前,先对 Grafana 和 InfluxDB 做一下简要的介绍:
Grafana:是一个开源的分析和监控系统,拥有精美的web UI,支持多种图表,可以展示influxdb中存储的数据,并且有报警的功能。
Influxdb :是一款开源的时间序列数据库,专门用来存储和时间相关的数据(比如我用它存储某个时间点爬虫抓取信息的数量)。
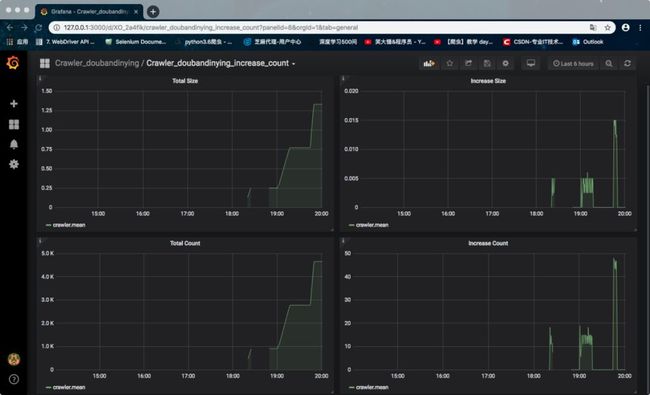
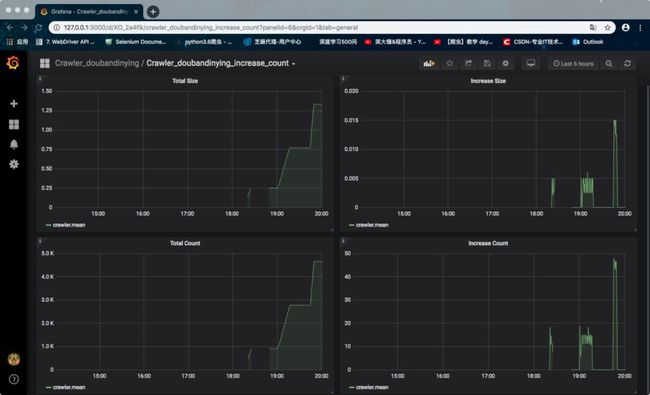
最终能实现的效果是这样的:
请注意以下操作,都是 Mac 下实现的。但是原理是相似的,你可以在自己的 PC 上进行试验。
#2. 安装配置 InfluxDB
安装 InfluxDB
brew update
brew install influxdb
修改配置文件/usr/local/etc/influxdb.conf,如果原文件中没有对应配置项,需自己添加。
[]
dir = "/usr/local/var/influxdb/data"
wal-dir = "/usr/local/var/influxdb/wal"
[]
bind-address='127.0.0.1:8083'
[]
bind-address = ":8086"
#3. 安装配置 Grafana
安装 Grafana
brew update
brew install grafana
并修改 Grafana 配置文件 /usr/local/etc/grafana/grafana.ini,内容如下:
[server]
;protocol = http
;http_addr =
# 此处修改端口号
;http_port = 3000
# The public facing domain name used to access grafana from a browser
;domain = localhost
# Redirect to correct domain if host header does not match domain
# Prevents DNS rebinding attacks
;enforce_domain = false
# The full public facing url you use in browser, used for redirects and emails
# If you use reverse proxy and sub path specify full url (with sub path)
;root_url = http://localhost:3000
#4. 爬虫代码
由于这里主是要介绍如何将 Grafana 和 InfluxDB 与爬虫进行结合的方案,而不是主讲爬虫原理,而且代码也比较多,影响可读性,所以就不贴出爬取的代码。
若你对这代码感兴趣,可以点击原文连接查看详细内容!
#5. 监控脚本
考虑到可能要增加爬虫到监控中,因此这里使用了热更新对监控进行动态配置。
配置文件 influx_settings.conf 主要用于热更新相关设置。
# [需要监控的 MongoDB 数据的 数据库名 和 集合名]
[db]
db_collection_dict = {
'learn_selenium_doubandianying': 'movie_info',
}
# [设置循环间隔时间]
[time]
interval = 15
如何动态读取这个配置文件的设置呢?需要写一个脚本来监控。代码如下:
import ast
import time
import pymongo
import traceback
from configparser import ConfigParser
from influxdb import InfluxDBClient
from datetime import datetime
from os.path import getmtime
# 配置 influxdb
client = InfluxDBClient(host='localhost', port=8086) # influxdb默认端口为8086
# 创建 database
client.create_database('Spider')
# switch 到 database
client.switch_database('Spider')
# 设定配置文件
config_name = 'influx_settings.conf'
WATCHED_FILES = [config_name]
WATCHED_FILES_MTIMES = [(f, getmtime(f)) for f in WATCHED_FILES]
_count_dict = {}
_size_dict = {}
# 获取配置文件中的设置
def parse_config(file_name):
try:
# 创建一个配置文件对象
cf = ConfigParser()
# 打开配置文件
cf.read(file_name)
# 获取配置文件中的统计频率
interval = cf.getint('time', 'interval')
# 获取配置文件中要监控的 dbs 和 collection
dbs_and_collections = ast.literal_eval(cf.get('db', 'db_collection_dict'))
return interval, dbs_and_collections
except:
print(traceback.print_exc())
return None
# 从 MongoDB 获取数据,并写入 InfluxDB
def insert_data(dbs_and_collections):
# 连接 MongoDB 数据库
mongodb_client = pymongo.MongoClient(host='127.0.0.1',port=27017) # 直接使用默认地址端口连接 MongoDB
for db_name, collection_name in dbs_and_collections.items():
# 数据库操作,创建 collection 集合对象
db = mongodb_client[db_name]
collection = db[collection_name]
# 获取 collection 集合大小
collection_size = round(float(db.command("collstats", collection_name).get('size')) / 1024 / 1024, 2)
# 获取 collection 集合内数据条数
current_count = collection.count()
# 初始化数据条数,当程序刚执行时,条数初始量就设置为第一次执行时获取的数据
init_count = _count_dict.get(collection_name, current_count)
# 初始化数据大小,当程序刚执行时,大小初始量就设置为第一次执行时获取的数据大小
init_size = _size_dict.get(collection_name, collection_size)
# 得到数据条数增长量
increase_amount = current_count - init_count
# 得到数据大小增长量
increase_collection_size = collection_size - init_size
# 得到当前时间
current_time = datetime.utcnow().strftime('%Y-%m-%dT%H:%M:%SZ')
# 赋值
_count_dict[collection_name] = current_count
_size_dict[collection_name] = collection_size
# 构建
json_body = [
{
"measurement": "crawler",
"time": current_time,
"tags": {
"spider_name": collection_name
},
"fields": {
"count": current_count,
"increase_count": increase_amount,
"size": collection_size,
"increase_size": increase_collection_size
}
}
]
# 将获取
if client.write_points(json_body):
print('成功写入influxdb!',json_body)
def main():
# 获取配置文件中的监控频率和MongoDB数据库设置
interval, dbs_and_collexctions = parse_config(config_name)
# 如果配置有问题则报错
if (interval or dbs_and_collexctions) is None:
raise ValueError('配置有问题,请打开配置文件重新设置!')
print('设置监控频率:', interval)
print('设置要监控的MongoDB数据库和集合:', dbs_and_collexctions)
last_interval = interval
last_dbs_and_collexctions = dbs_and_collexctions
# 这里实现配置文件热更新
for f, mtime in WATCHED_FILES_MTIMES:
while True:
# 检查配置更新情况,如果文件有被修改,则重新获取配置内容
if getmtime(f) != mtime:
# 获取配置信息
interval, dbs_and_collections = parse_config(config_name)
print('提示:配置文件于 %s 更新!' % (time.strftime("%Y-%m-%d %H:%M:%S")))
# 如果配置有问题,则使用上一次的配置
if (interval or dbs_and_collexctions) is None:
interval = last_interval
dbs_and_collexctions = last_dbs_and_collexctions
else:
print('使用新配置!')
print('新配置内容:', interval, dbs_and_collexctions)
mtime = getmtime(f)
# 写入 influxdb 数据库
insert_data(dbs_and_collexctions)
# 使用 sleep 设置每次写入的时间间隔
time.sleep(interval)
if __name__ == '__main__':
main()
来试着运行一下
python3 influx_monitor.py
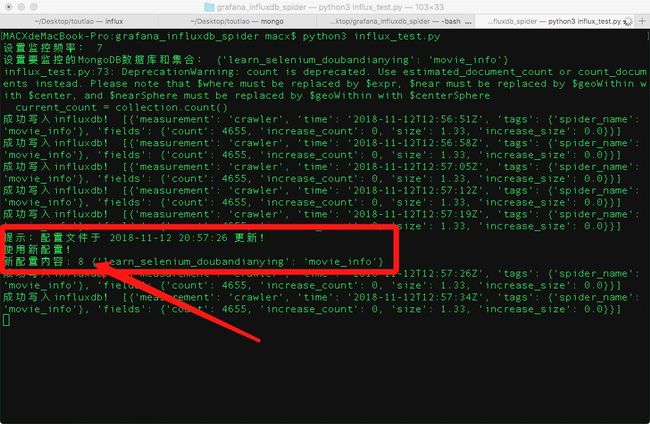
运行,得到下图内容,表示监控脚本运行成功。

另建窗口,修改配置文件 influx_settings.conf
# 修改间隔时间为8秒
interval = 8
切换至第一次运行 influxDB 的窗口,会提示配置更新,说明配置热更新生效。
#6. 配置 Grafana
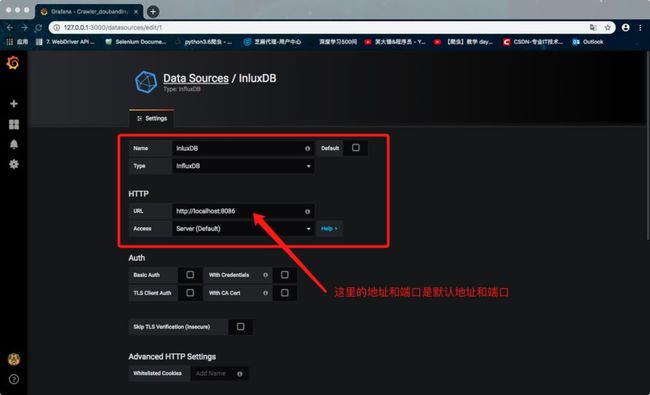
首先打开 Chrome 浏览器,输入 http://127.0.0.1:3000 登录 grafana 页面。
连接本地 influxDB 数据库,操作如下图。
在红色方框内选择 Type 类型为 InfluxDB,并输入URL:http://localhost:8086

在红框内输入influxDB数据库名称
新建 dashboard

新建 graph 类型 dashboard
修改 dashboard 设置

点击红色方框修改设定

修改 dashboard 配置
设置监控的数据对象
在监控脚本中,写入influxDB的代码如下,其中 "measurement" 对应 表名,"fields" 对应写入的字段;
"measurement": "crawler",
"fields": {
"count": current_count,
"increase_count": increase_amount,
"size": collection_size,
"increase_size": increase_collection_size
}
#7. 运行爬虫文件
启动 MongoDB 数据库服务。
brew services mongodb start
新建一个 terminal 窗口,运行爬虫文件。

爬虫文件运行成功
我们可以在刚刚打开的控制台里查看效果展示:
本文来自读者投稿,小明对原文进行了大量的修剪及排版使得内容更适应公众号手机阅读。如需文中提及的代码,请点击左下方原文链接进行查看。
现在微信改版了
好多人跟痴海说
看不到痴海了
其实只要把痴海置顶就可以了
只需要 5 秒钟
痴海教你置顶
推荐阅读: