CNN系列笔记(五)——Faster RCNN
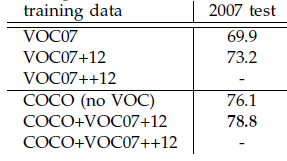
本文是继RCNN[1],fast RCNN[2]之后,目标检测界的领军人物Ross Girshick团队在2015年的又一力作。简单网络目标检测速度达到17fps,在PASCAL VOC上准确率为59.9%;复杂网络达到5fps,准确率78.8%。作者在github上给出了基于matlab和python的源码。
一、基于Region Proposal(候选区域)的深度学习目标检测算法
1.1 Region Proposal(候选区域):
就是预先找出图中目标可能出现的位置,通过利用图像中的纹理、边缘、颜色等信息,保证在选取较少窗口(几千个甚至几百个)的情况下保持较高的召回率(IoU,Intersection-over-Union)。
Region Proposal方法比传统的滑动窗口方法获取的质量要更高。比较常用的Region Proposal方有:SelectiveSearch(SS,选择性搜索)、Edge Boxes(EB)。
1.2 基于Region Proposal目标检测算法的步骤如下:

1.3 常见的CNN模型介绍
https://blog.csdn.net/qq_17448289/article/details/52850223
1.4 边框回归(Bouding Box Regression)
是对RegionProposal进行纠正的线性回归算法,目的是为了让Region Proposal提取到的窗口与目标窗口(Ground Truth)更加吻合。
二、R-CNN、Fast R-CNN、Faster R-CNN三者关系

| 使用方法 |
缺点 |
改进 |
|
| R-CNN (Region-based Convolutional Neural Networks) |
1、SS提取RP; 2、CNN提取特征; 3、SVM分类; 4、BB回归。 |
1、 训练步骤繁琐(微调网络+训练SVM+训练bbox); 2、 训练、测试均速度慢 ; 3、 训练占空间 |
1、 从DPM HSC的34.3%直接提升到了66%(mAP); 2、 引入RP+CNN |
| Fast R-CNN (Fast Region-based Convolutional Neural Networks) |
1、SS提取RP; 2、CNN提取特征; 3、softmax分类; 4、多任务损失函数边框回归。 |
1、 依旧用SS提取RP(耗时2-3s,特征提取耗时0.32s); 2、 无法满足实时应用,没有真正实现端到端训练测试; 3、 利用了GPU,但是区域建议方法是在CPU上实现的。 |
1、 由66.9%提升到70%; 2、 每张图像耗时约为3s。 |
| Faster R-CNN (Fast Region-based Convolutional Neural Networks) |
1、RPN提取RP; 2、CNN提取特征; 3、softmax分类; 4、多任务损失函数边框回归。 |
1、 还是无法达到实时检测目标; 2、 获取region proposal,再对每个proposal分类计算量还是比较大。 |
1、 提高了检测精度和速度; 2、 真正实现端到端的目标检测框架; 3、 生成建议框仅需约10ms。 |
Fast R-CNN框架与R-CNN有两处不同:
- ① 最后一个卷积层后加了一个ROI pooling layer;
- ② 损失函数使用了multi-task loss(多任务损失)函数,将边框回归直接加到CNN网络中训练。分类Fast R-CNN直接用softmax替代R-CNN用的SVM进行分类。
注:Fast R-CNN和Faster R-CNN是端到端(end-to-end)的;R-CNN不是端到端的。
三、Faster R-CNN目标检测
3.1 Faster R-CNN的思想
faster RCNN可以简单地看做“候选区域生成网络+fast RCNN“的系统,用区域生成网络代替fast RCNN中的Selective Search方法。本篇论文着重解决了这个系统中的三个问题:
- 1. 如何设计区域生成网络(RPN)
- 2. 如何训练区域生成网络
- 3. 如何让区域生成网络和fast RCNN网络共享特征提取网络
在整个faster RCNN算法中,有三种尺度。
原图尺度:原始输入的大小。不受任何限制,不影响性能。
归一化尺度:输入特征提取网络的大小,在测试时设置,源码中opts.test_scale=600。anchor在这个尺度上设定。这个参数和anchor的相对大小决定了想要检测的目标范围。
网络输入尺度:输入特征检测网络的大小,在训练时设置,源码中为224*224。
3.2 Faster R-CNN框架介绍
Faster-R-CNN算法由两大模块组成:
- 1.PRN候选框提取模块;
- 2.Fast R-CNN检测模块。
其中,RPN是全卷积神经网络,用于提取候选框;Fast R-CNN基于RPN提取的proposal检测并识别proposal中的目标。
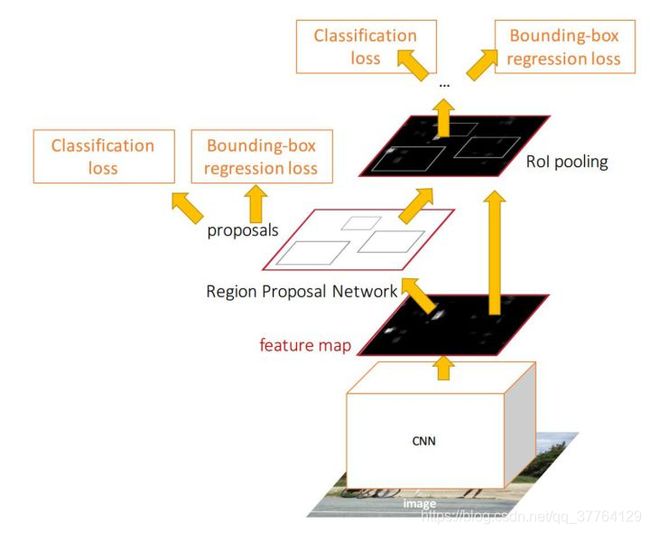
图1 Faster R-CNN基本结构(来自原文)
依作者看来,如图1,Faster RCNN其实可以分为4个主要内容:
- Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
所以本文以上述4个内容作为切入点介绍Faster R-CNN网络。
图2展示了python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构,可以清晰的看到该网络对于一副任意大小PxQ的图像,首先缩放至固定大小MxN,然后将MxN图像送入网络;而Conv layers中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3x3卷积,再分别生成foreground anchors与bounding box regression偏移量,然后计算出proposals;而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
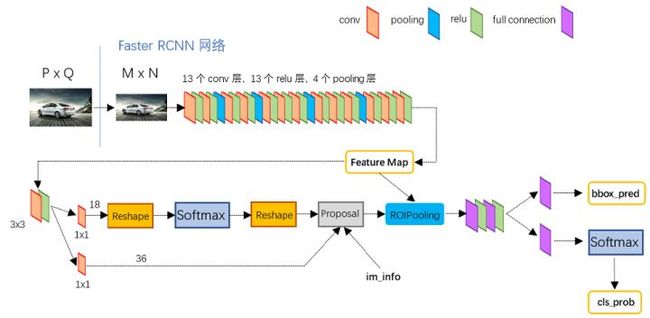
图2 faster_rcnn_test.pt网络结构 (pascal_voc/VGG16/faster_rcnn_alt_opt/faster_rcnn_test.pt)
未完待续。。。
https://zhuanlan.zhihu.com/p/31426458?utm_source=qq&utm_medium=social&utm_oi=827947156655718400
3.3 RPN介绍
3.3.1背景
目前最先进的目标检测网络需要先用Region Proposal算法推测目标位置,像SPPnet和Fast R-CNN这些网络虽然已经减少了检测网络运行的时间,但是计算Region Proposal依然耗时较大。所以,在这样的瓶颈下,RBG和Kaiming He一帮人将Region Proposal也交给CNN来做,这才提出了RPN(Region Proposal Network)候选区域生成网络用来提取检测区域,它能和整个检测网络共享全图的卷积特征,使得Region Proposal几乎不花时间。
3.3.2 RPN详解
RPN的核心思想是使用CNN卷积神经网络直接产生Region Proposal,使用的方法本质上就是滑动窗口(只需在最后的卷积层上滑动一遍),因为anchor机制和边框回归可以得到多尺度多长宽比的Region Proposal。
RPN网络也是全卷积网络(FCN,fully-convolutional network),可以针对生成检测建议框的任务端到端地训练,能够同时预测出object的边界和分数。只是在CNN上额外增加了2个卷积层(全卷积层cls和reg)。
RPN网络的输入可以是任意大小(但还是有最小分辨率要求的,例如VGG是228*228)的图片。如果用VGG16进行特征提取,那么RPN网络的组成形式可以表示为VGG16+RPN。
基本设想是:在提取好的特征图上,对所有可能的候选框进行判别。由于后续还有位置精修步骤,所以候选框实际比较稀疏。
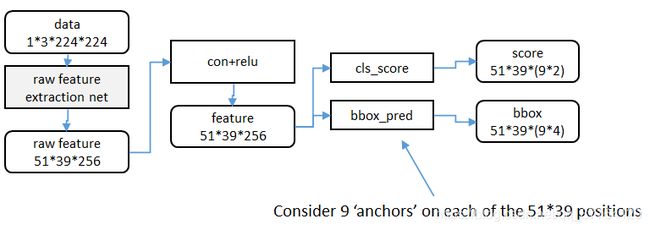
a、特征提取
原始特征提取网络(上图灰色方框)包含若干层conv+relu,直接套用ImageNet上常见的分类网络模型即可,即ZF、VGG等。本文试验了两种网络:5层的ZF[3],16层的VGG-16[4]。具体结构见1.3链接。
RPN需要使用一个CNN网络对原始图片提取特征。为了方便读者理解,不妨设这个前置的CNN提取的特征为51×39×256,即高为51,宽为39,通道数为256。对这个卷积特征再进行一次卷积计算,保持宽、高、通道数不变,再次得到一个51×39×256的特征。
论文里采用了“Anchor”机制来生成候选区域,为了方便叙述,先来定义一个“位置”的概念:对于一个51×39×256的卷积特征,称它一共有51×39个"位置"。让新的卷积特征的每一个"位置"都"负责”原图中对应位置的9种尺寸框的检测,检测的目标是判断框中是否存在一个物体,因此共用51×39×9个“框”。在Faster R-CNN原论文中,将这些框都统一称为"anchor"即锚点。
b、候选区域(anchor)
候选区域生成最简单粗暴的方法就是用多尺度(scale),多视场(aspect ratio)的Sliding Window来生成。
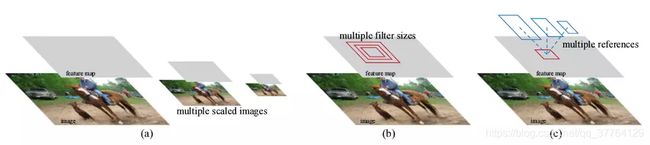
Anchor机制解释图
- 所谓多尺度(scale):可以简单的理解为将图片缩放成一系列图像,这些不同大小的图像就代表不同的尺度。尺度是一个相对的概念。如上图(a)所示。
- 所谓多视场(aspect ratio):多视场这个是自己理解翻译的词。这个可以这么理解:对于图像中的某个目标比如猫,对猫的眼睛给个框,然后扩大这个框,把猫的脑袋也包括进来,然后继续扩大,把整个猫也包含进来。这样得到的一些框内的图像就算是多视场。如上图(b)所示
特征可以看做一个尺度51×39的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积分别是128×128,256×256,512×512,每种面积又分成3种长宽比,分别是2:1,1:2,1:1 。这些候选窗口称为anchors(锚点)。做着就是通过这些anchors引入了检测中常用到的多尺度方法(检测各种大小的目标),下图示出51×39个anchor中心,以及9种anchor示例。
 或
或 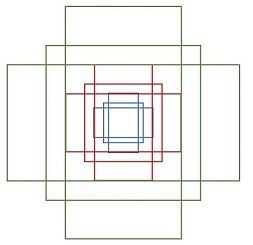
图4 9种anchor(注意:左边是不同位置,右边是同一位置)
对于这51×39个位置和51×39×9个anchor,下图展示了接下来每个位置的计算步骤:
- 设k为单个位置对应的anchor的个数,此时k=9,通过增加一个3×3滑动窗口操作以及两个卷积层完成区域建议功能;
- 第一个卷积层将特征图每个滑窗位置编码成一个特征向量,第二个卷积层对应每个滑窗位置输出k个区域得分,表示该位置的anchor为物体的概率,这部分总输出长度为2×k(一个anchor对应两个输出:是物体的概率+不是物体的概率)和k个回归后的区域建议(框回归),一个anchor对应4个框回归参数,因此框回归部分的总输出的长度为4×k,并对得分区域进行非极大值抑制后输出得分Top-N(文中为300)区域,告诉检测网络应该注意哪些区域,本质上实现了Selective Search、EdgeBoxes等方法的功能。
- 这样得到的候选区域虽然会有误差,不过后面还会有2次bounding box回归来修正检测框位置,所以就无所谓了,只要不是差太多就行。

图5 RPN框架
对于每一个像素都进行预测9个anchor,如果最后一层feature map是51x39大小的话,就要预测51x39x9个anchor,选出前300个得分高的作为候选区域,这样相比于Selective search得到的2000个区域少了很多,而且作者还进行了实验,发现用RPN得到的候选区域比selective search得到的Recall高很多。
在图5中,要注意,3*3卷积核的中心点对应原图(re-scale,源代码设置re-scale为600*1000)上的位置(点),将该点作为anchor(锚点)的中心点,在原图中框出多尺度、多种长宽比的anchors(图4右图)。所以,anchor不在conv特征图上,而在原图上。对于一个大小为H*W的特征层,它上面每一个像素点对应9个anchor,这里有一个重要的参数feat_stride = 16, 它表示特征层上移动一个点,对应原图移动16个像素点(看一看网络中的stride就明白16的来历了)。把这9个anchor的坐标进行平移操作,获得在原图上的坐标。之后根据ground truth label(基本真相标签)和这些anchor之间的关系生成rpn_lables,具体的方法论文中有提到,根据overlap来计算,这里就不详细说明了,生成的rpn_labels中,positive的位置被置为1,negative的位置被置为0,其他的为-1。box_target通过_compute_targets()函数生成,这个函数实际上是寻找每一个anchor最匹配的ground truth box, 然后进行论文中提到的box坐标的转化。http://blog.csdn.net/zhangwenjie89/article/details/52012880
RPN的具体流程如下(参照上图):使用一个小网络在最后卷积得到的特征图上进行滑动扫描,这个滑动网络每次与特征图上n*n(论文中n=3)的窗口全连接(图像的有效感受野很大,ZF是171像素,VGG是228像素),然后映射到一个低维向量(256d for ZF / 512d for VGG),最后将这个低维向量送入到两个全连接层,即bbox回归层(reg)和box分类层(cls)。sliding window的处理方式保证reg-layer和cls-layer关联了conv5-3的全部特征空间。
reg层:预测proposal的anchor对应的proposal的(x,y,w,h)
cls层:判断该proposal是前景(object)还是背景(non-object)。

c、框回归
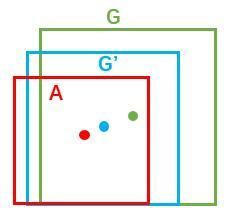
如图绿色表示的是飞机的实际框标签(ground truth),红色的表示的其中一个候选区域(foreground anchor),即被分类器识别为飞机的区域,但是由于红色区域定位不准确,这张图相当于没有正确检测出飞机,所以我们希望采用一种方法对红色的框进行微调,使得候选区域和实际框更加接近:

对于目标框一般使用四维向量来表示(x,y,w,h),分别表示目标框的中心点坐标、宽、高,我们使用A表示原始的foreground anchor,使用G表示目标的ground truth,我们的目标是寻找一种关系,使得输入原始的Anchor A经过映射到一个和真实框G更接近的回归窗口G′,即:
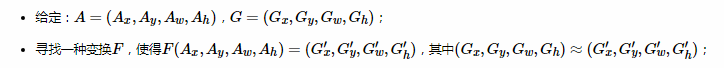
那么如何去计算FF呢?这里我们可以通过平移和缩放实现F(A)=G′:
- 平移:
![]()
![]()
- 缩放:
![]()
![]()
上面公式中,我们需要学习四个参数,分别是dx(A),dy(A),dw(A),dh(A),其中(Aw⋅dx(A),Aw⋅dy(A))表示的两个框中心距离的偏移量。当输入的anchor A与G相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对目标框进行微调(注意,只有当anchors A和G比较接近时,才能使用线性回归模型,否则就是复杂的非线性问题了)。
接下来就是如何通过线性回归获得dx(A),dy(A),dw(A),dh(A)。线性回归就是给定输入的特征向量X,学习一组参数W,使得线性回归的输出WX和真实值Y的差很小。对于该问题,输入X是特征图,我们使用ϕ表示,同时训练时还需要A到G变换的真实参数值:(tx,ty,tw,th);输出是dx(A),dy(A),dw(A),dh(A),那么目标函数可以表示为:
![]()
其中ϕ(A)是对应anchor的特征图组成的特征向量,w是需要学习的参数,d(A)是得到预测值,(*表示x,y,w,h,也就是每一个变换对应一个上述目标函数),为了让预测值dx(A),dy(A),dw(A),dh(A)和真实值差距tx,ty,tw,th最小,代价函数如下:
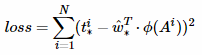
函数优化目标为:
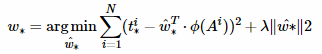
需要说明,只有在G和A比较接近时,才可近似认为上述线性变换成立,下面对于原文中,A与G之间的平移参数(tx,ty)和尺度因子(tw,th)为:
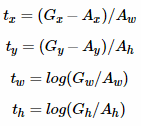
对于训练bouding box regression网络回归分支,输入是特征图ϕ,监督信号是A到G的变换参数(tx,ty,tw,th),即训练的目标是:输入ϕ的情况下使网络输出与监督信号尽可能接近。那么bouding box regression工作时,再输入ϕ时,回归网络分支的输出就是每个anchor的平移参数和变换尺度(tx,ty,tw,th),显然即可用来修正anchor位置了。
d、候选框修正
在得到每一个候选区域anchor A的修正参数(dx(A),dy(A),dw(A),dh(A))之后,我们就可以计算出精确的anchor,然后按照物体的区域得分从大到小对得到的anchor排序,然后提出一些宽或者高很小的anchor(获取其它过滤条件),再经过非极大值抑制抑制,取前Top-N的anchors,然后作为proposals(候选框)输出,送入到RoI Pooling层。
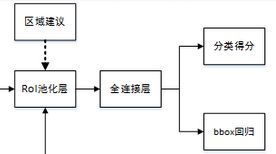
四、RoI Pooling层
RoI Pooling层负责收集所有的候选框,并计算每一个候选框的特征图,然后送入后续网络,从Faster RCNN的结构图我们可以看到RoI Pooling层有两个输入:
- 原始的特征图;
- RPN网络输出的候选框;
4.1、为何使用RoI Pooling
先来看一个问题:对于传统的CNN(如AlexNet,VGG),当网络训练好后输入的图像尺寸必须是固定值,同时网络输出也是固定的大小。如果输入图像大小不定,这个问题就变得比较麻烦。有2种解决办法:
- 从图像中crop(裁剪)一部分传入网络;
- 将图像warp(放大)成需要的大小后传入网络;

两种办法的示意图如上图,可以看到无论采取那种办法都不好,要么crop后破坏了图像的完整结构,要么warp破坏了图像原始形状信息。
回忆RPN网络生成的proposals的方法:对foreground anchors进行bounding box regression,那么这样获得的proposals也是大小形状各不相同,即也存在上述问题。所以Faster R-CNN中提出了RoI Pooling解决这个问题。不过RoI Pooling是从Spatial Pyramid Pooling发展而来,有兴趣的读者可以自行查阅相关论文。
4.2、RoI Pooling原理
我们把每一个候选框的特征图水平和垂直分为pooled_w(文章中为7)和pooled_h(7)份,对每一份进行最大池化处理,这样处理后,即使大小不一样的候选区,输出大小都一样,实现了固定长度的输出:

然后我们把Top-N个固定输出(7×7=497×7=49)连接起来,组成特征向量,大小为Top−N×49Top−N×49,这里可以把Top-N看做样本数,49看做每一个样本的特征维数,送入全连接层。
五、分类和框回归
通过RoI Pooling层我们已经得到所有候选区组成的特征向量,然后送入全连接层和softmax计算每个候选框具体属于哪个类别,输出类别的得分;同时再次利用框回归获得每个候选区相对实际位置的偏移量预测值,用于对候选框进行修正,得到更精确的目标检测框。
这里我们来看看全连接层,由于全连接层的参数w和b大小都是固定大小的,假设大小为49×26,那么输入向量的维度就要为Top−N×49,所以这就说明了RoI Pooling的重要性。
二、候选区域(anchor) 生成
六、区域生成网络的训练
3.1 正负样本的选取
考察训练集中的每张图像:
- a. 对每个标定的真值候选区域,与其重叠比例(IOU)最大的anchor记为前景样本(正样本);
- b. 对a)剩余的anchor,如果其与某个ground truth(标定重叠)比例大于0.7,也记为前景样本;如果其与任意一个标定的重叠比例都小于0.3,记为背景样本(负样本);
- c. 对a),b)剩余的anchor,弃去不用。
- d. 跨越图像边界的anchor弃去不用
3.2 超参数
原始特征提取网络使用ImageNet的分类样本初始化,其余新增层随机初始化。
每个mini-batch包含从一张图像中提取的256个anchor,前景背景样本1:1.
前60K迭代,学习率0.001,后20K迭代,学习率0.0001。
momentum设置为0.9,weight decay设置为0.0005。[5]
四、RPN和Fast R-CNN共享卷积层/特征
区域生成网络(RPN)和fast RCNN(准确来说是Fast R-CNN的分类和bounding box回归部分)都需要一个原始特征提取网络即CNN(下图灰色方框),其中CNN接上RPN,而后是Fast R-CNN,也就是说Fast R-CNN和RPN是共享CNN的。这个网络使用ImageNet的分类库得到初始参数W0,但要如何精调参数,使其同时满足两方的需求呢?本文讲解了三种方法。
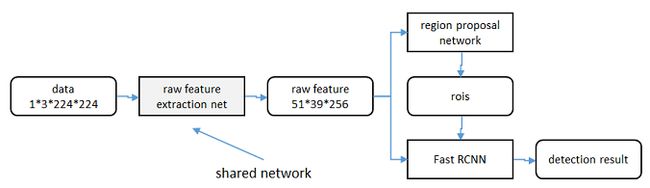
1)轮流训练/非近似联合训练
a. 从W0开始,训练RPN。用RPN提取训练集上的候选区域
b. 从W0开始,用候选区域训练Fast RCNN,参数记为W1
c. 从W1开始,训练RPN…
具体操作时,仅执行两次迭代,并在训练时冻结了部分层。论文中的实验使用此方法。
如Ross Girshick在ICCV 15年的讲座Training R-CNNs of various velocities中所述,采用此方法没有什么根本原因,主要是因为”实现问题,以及截稿日期“。
2)近似联合训练
直接在上图结构上训练。在backward计算梯度时,把提取的ROI区域当做固定值看待;在backward更新参数时,来自RPN和来自Fast RCNN的增量合并输入原始特征提取层。
此方法和前方法效果类似,但能将训练时间减少20%-25%。公布的python代码中包含此方法。
3)联合训练
直接在上图结构上训练。但在backward计算梯度时,要考虑ROI区域的变化的影响。推导超出本文范畴,请参看15年NIP论文[6]。
五、实验对比结果
除了开篇提到的基本性能外,还有一些值得注意的结论
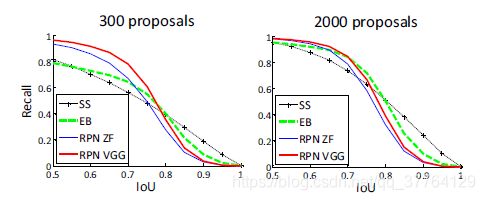
- 与Selective Search方法(黑)相比,当每张图生成的候选区域从2000减少到300时,本文RPN方法(红蓝)的召回率下降不大。说明RPN方法的目的性更明确。
- 使用更大的Microsoft COCO库[7]训练,直接在PASCAL VOC上测试,准确率提升6%。说明faster RCNN迁移性良好,没有over fitting。
六、代价函数:窗口分类和位置精修
同时最小化两种代价:
a. 分类误差
b. 前景样本的窗口位置偏差,即回归损失
- 分类层(cls_score)输出每一个位置上,9个anchor属于前景和背景的概率;
- 窗口回归层(bbox_pred)输出每一个位置上,9个anchor对应窗口应该平移缩放的参数。
对于每一个位置来说,分类层从256维特征中输出属于前景和背景的概率;窗口回归层从256维特征中输出4个平移缩放参数。
就局部来说,这两层是全连接网络;就全局来说,由于网络在所有位置(共51*39个)的参数相同,所以实际用尺寸为1×1的卷积网络实现。
具体参看fast RCNN中的“分类与位置调整”段落。
实际代码中,将51*39*9个候选位置根据得分排序,选择最高的一部分,再经过Non-Maximum Suppression(非极大值抑制)获得2000个候选结果。之后才送入分类器和回归器。
所以Faster-RCNN和RCNN, Fast-RCNN一样,属于2-stage的检测算法。
参考资料:
- faster rcnn解读:很好,很详细,可跟2结合来看,有代码
- 一文读懂Faster RCNN:详细全面,通俗易懂
- Faster R-CNN/RPN/generate_anchors详解:有代码
- 【目标检测】Faster RCNN算法详解 :简单直观,条理清晰
- Faster R-CNN论文阅读笔记 对RPN网络介绍的比较详细
- Fast r-cnn详解 http://www.cnblogs.com/zyly/p/9247863.html
- Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. ↩
- Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩
- M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional neural networks,” in European Conference on Computer Vision (ECCV), 2014. ↩
- K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in International Conference on Learning Representations (ICLR), 2015. ↩
- learning rate-控制增量和梯度之间的关系;momentum-保持前次迭代的增量;weight decay-每次迭代缩小参数,相当于正则化。 ↩
- Jaderberg et al. “Spatial Transformer Networks”
- NIPS 2015 ↩
- 30万+图像,80类检测库。参看http://mscoco.org/。 ↩
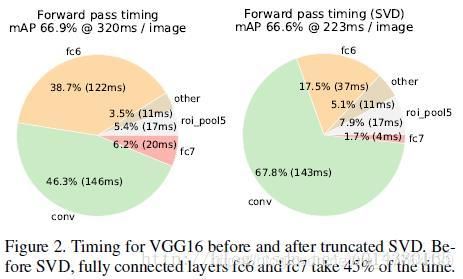
采用SVD分解改进全连接层。如果是一个普通的分类网络,那么全连接层的计算应该远不及卷积层的计算,但是针对object detection,Fast RCNN在ROI pooling后每个region proposal都要经过几个全连接层,这使得全连接层的计算占网络的计算将近一半,如下图,所以作者采用SVD来简化全连接层的计算。另一篇博客链接讲的R-FCN网络则是对这个全连接层计算优化的新的算法。