底层原理图
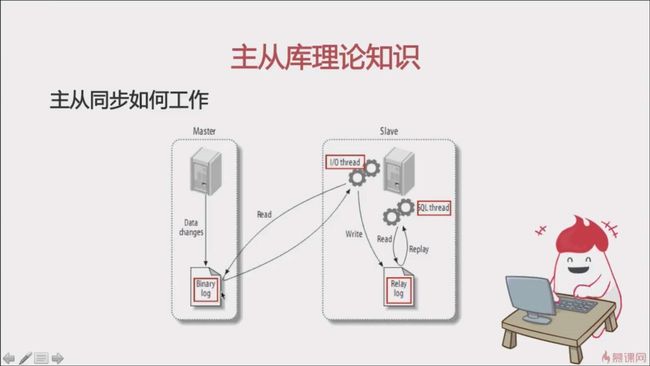
做主从同步配置
主:数据库1(port:3306)和从:数据库2(3307)(分别在两个服务器上)(在同一台机器上要两个端口号不一样)
在第一个服务器上:
cmd
连接数据库1
mysql -root -p
查看有哪些数据库
show databases
在第二个服务器上:
cmd
连接数据库2
mysql -root -p
查看有哪些数据库
show databases
------------------------------------
在第一个服务器上:
vim /etc/my.cnf
打开二进制日志,在#The MySQL server下写入
server-id=1
log-bin=master-bin
log-bin-index=master-bin.index
在最下面命令输入wq 保存退出
重启数据库(方法一)
service mysqld restart
重新去数据库去看一眼
mysql -uroot -p
show databases;
show master status
创建主库别名
create user repl;
赋予从库的连接的权限
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'115.28.159.6' INENTIFIED BY '123456' 从库的IP地址,及连接的密码
刷新一下
flush privileges;
------------------------------------
在第二个服务器上:
vim /etc/my.cnf
打开二进制日志,在#The MySQL server下写入
server-id=2
relay-log-index=slave-relay-bin.index
relay-log=slave-relay-bin
在最下面命令输入wq 保存退出
重启数据库(方法二)
/etc/init.d/mysql stop 停止
/etc/init.d/mysql start 重新开始
重新去数据库去看一眼
mysql -uroot -p
show databases;
------------------------------------
将两个服务器数据库连接起来:
在从服务器控制台上输入
mysql -uroot -p
输入密码后进入
show databases; 能显示出有哪些数据库,说明配置是没有问题的
change master to master_host='120.24.64.163',master_port=3306,master_user='repl',master_password='123456',master_log_file='master-bin.000001',master_log_pos=0; 主服务器的IP地址,主数据库的端口号、别名、密码、二进制文件、同步起始位置(服务器挂了,可以设为0)
开启主从跟踪
start slave;
查看相关的状态
show slave status \G
如果报错是两个库的id是一样的
停止
stop slave;
exit
看看cnf配置文件
vim /etc/my.cnf
搜索命令:/server-id
找到server-id=1,删除,留下server-id=2
wq 保存退出
重启一下mysql
/etc/init.d/mysql stop
/ect/init.d/mysql start
调用完成后,重新连接数据库
mysql -uroot -p
(password:)
将主从同步打开
start slave;
show slave status \G;
不报错,即可去做同步
可以看到Slave_IO_State: Waiting for master to send event (正在等待主库发送一个变动的事件过来)
---------------------------------
即完成主从库的配置
主库负责写,从库负责读
三个要点:
show master status;
1、Position下的文件是放的缓存的数据,如果数据过大,会被划分到其他文件中去,原来的变成0
2、两库的版本可以不一样,但是这个是向后兼容,从的版本不能比主库低
3、主库只写,从库只读,否则会冲突