Spark词频统计的三种方式
利用spark-shell来编程
spark-shell --master spark://hadoop01:7077
已经初始化好了SparkContext sc
回顾wordcount的思路:
读数据,切分并压平,组装,分组聚合, 排序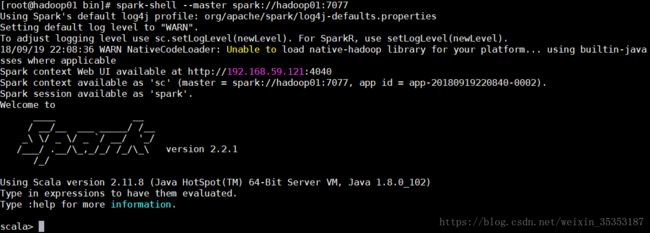
当启动spark-shell启动以后 , 监控页面会监控到spark-shell

当我们使用spark-shell以集群模式读取本地的数据的时候,报错:文件不存在

这是因为 spark-shell 是以集群的方式启动的 , 但是读取本地文件夹的时候 , 只有一台机器上有该文件 , 所以另外的机器的 worker 就读取不到文件 , 就会报这个错 . 如果以local模式运行 , 没有问题 , 把文件发送到所有的 worker 节点中去
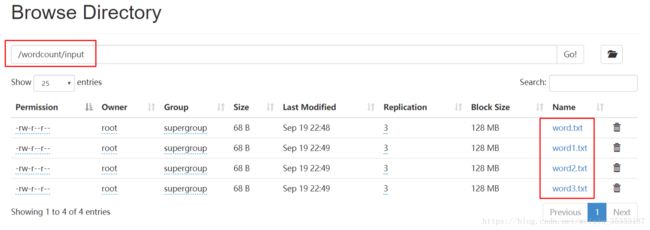
所以我们读取分布式文件系统的文件
spark中的RDD上的方法都称之为算子。
分为两类:
转换 transformation lazy执行。 当遇到action算子的时候,才开始真正的运行。转换类的算子,都会生成新的rdd。
行动类的算子 action




![]()

简洁写法 :

collect saveAsTextFile 是action算子
map flatMap reduceByKey sortBy 都是转换算子
转换算子,是lazy执行的。
IDEA编写
scala版本的
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object ScalaWordCount {
def main(args: Array[String]): Unit = {
if (args.length != 2) {
println("Usage :cn.huge.spark33.day01.ScalaWordCount java版本
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class JavaWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
// java的程序 一定是使用JavaAPI 去实现
JavaSparkContext sc = new JavaSparkContext(conf);
// 读数据
JavaRDD lines = sc.textFile(args[0]);
// 切分并压平 输入和输出参数
JavaRDD words = lines.flatMap(new FlatMapFunction() {
@Override
public Iterator call(String s) throws Exception {
// 调用Arrays 生成指定类型
return Arrays.asList(s.split(" ")).iterator();
}
});
// 组装 第一个:输入参数 输出参数(String,Int)
JavaPairRDD wordAndOne = words.mapToPair(new PairFunction() {
@Override
public Tuple2 call(String s) throws Exception {
// 组装元组
// return Tuple2.apply(s,1);
return new Tuple2<>(s, 1);
}
});
// 分组聚合 两个输入参数 一返回值类型
JavaPairRDD result = wordAndOne.reduceByKey(new Function2() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
// 排序 先把k -v 互换 然后调用 sortByKey 然后再调换回来
JavaPairRDD beforeSwap = result.mapToPair(new PairFunction, Integer, String>() {
@Override
public Tuple2 call(Tuple2 tp) throws Exception {
// 元素交换
return tp.swap();
}
});
// 默认是升序 传false的参数
JavaPairRDD sortedTp = beforeSwap.sortByKey(false);
JavaPairRDD finalRes = sortedTp.mapToPair(new PairFunction, String, Integer>() {
@Override
public Tuple2 call(Tuple2 integerStringTuple2) throws Exception {
return integerStringTuple2.swap();
}
});
// 存储 写到hdfs中
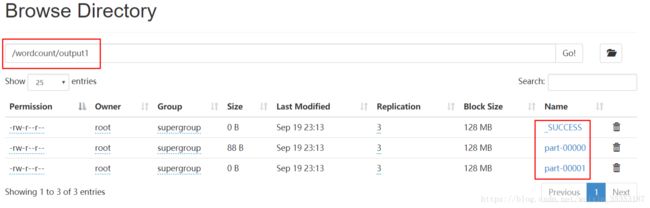
finalRes.saveAsTextFile(args[1]);
sc.stop();
}
} java lambda 版本
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class JavaLambdaWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
// java的程序 一定是使用JavaAPI 去实现
conf.setMaster("local[*]");
conf.setAppName(JavaLambdaWordCount.class.getSimpleName());
JavaSparkContext sc = new JavaSparkContext(conf);
// 读数据
JavaRDD lines = sc.textFile(args[0]);
// t => t ->
JavaRDD words = lines.flatMap(t -> Arrays.asList(t.split(" ")).iterator());
JavaPairRDD wordAndOne = words.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD result = wordAndOne.reduceByKey((a, b) -> a + b);
JavaPairRDD beforeSwap = result.mapToPair(tp -> tp.swap());
JavaPairRDD sorted = beforeSwap.sortByKey(false);
JavaPairRDD finalRes = sorted.mapToPair(tp -> tp.swap());
finalRes.saveAsTextFile(args[1]);
sc.stop();
}
}