论文:Deep Residual Learning for Image Recognition
Abstract:
更深层的网络训练十分困难,我们提出了残差网络来实现深层网络。我们重新定制了层间的学习是参考 layer input 的残差函数,而不是一个没有参考的函数。
Introduction:
是否学习更好的网络就是简单的堆积更多的层?一个障碍便是梯度消失或者爆炸,从训练的一开始便会损害收敛,虽然这个问题可以被 normalization initialization 和 intermediate normalization layers解决,可以使网络达到十多层
当深层网络可以收敛后,又出现了退化问题,当网络层数加深,准确率开始变得饱和,然后会快速衰退,这种衰退并不是因为过拟合引起的,加更多的层会引起训练误差变大,如下图
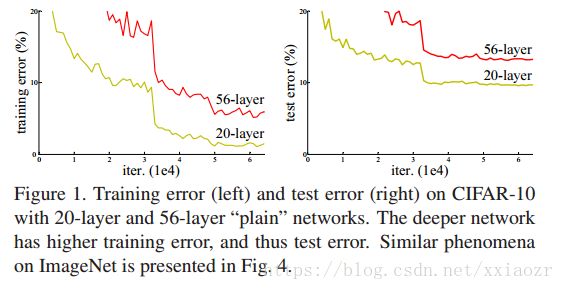
这种训练准确率的退化表明并不是所用的 system 都可以很好的优化。如何从 shallower architecture 到 deeper architecture. 现有的方法是,added layers 是恒等映射(identity mapping),而其它层是 copy from learned shallower model.这种方法本应获得不低于 shallower counterpart 的准确率,但是并没有。
本文通过提出一个 deep residual learning framework 来解决 degradation problem.我们让这些堆叠层拟合一个残差映射,而不是直接拟合底层映射。将期望得到的底层映射设为 H(x),让堆叠的非线性层拟合一个映射,F(x)=H(x)- x,这样,原始的映射 H(x)就是 F(x)+ x . 我们假设优化一个残差映射比无引用的映射更容易。极端情况下,当一个恒等网络是最优的,那么通过残差映射将它的残差变为零比非线性层拟合一个恒等映射更简单。

F(x)+ x 可以通过 feedword 来实现,即如上图的 shortcut connections. 在我们的例子中,shortcut connection 只是简单的执行恒等映射,然后把他们的输入加到堆叠的层。恒等 shortcut connection 没有增加额外的参数,也没有额外的计算。
接下来,我们会在 ImageNet 上进行试验,我们展示了
- 极深的残差网络也可以很简单的优化,但是“plain(simply stack layers)”在层数加深时,训练误差会变大
- 残差网络可以将网络层数加到很大,来获得很好的准确率,结果优于以前的网络
在 Cifar-10 上相同的结果证明我们的方法不是对于某一个数据集的特定方法。
Related Work:
- 残差表达:在低级视觉问题中,多尺度方法将问题分解为多个尺度的子问题,每一个子问题是 coarser 和 finer scale 的残差问题。多尺度的另一种方式是多层基预处理,它依赖于两个 scales 之间的残差变量,这种方法收敛的很快,就是因为残差的特性。这种方法说明一个好的重新表达或者预处理可以简化优化。
- Shortcut 连接:对 shortcut 的研究有很长的一段时间了。早期,多层感知机增加一个线性层来连接网络的输入和输出;后来,一些中间层被用来来接到辅助分类器来解决梯度消失/爆炸的问题;Inception 模型中,一个“inception”层由 shortcut branch 和 deeper branch 组成。和我们的工作同期的, 还有一个“highway network”,将 shortcut connections 和 门函数连接起来。这个门和数据有关,而且具有参数,门可以关闭,就不是代表残差函数了,而且 highway network 并不会随着层数的加深来增加准确率。与之相反,我们的 formulation 总是学习 residual function,我们的 shortcuts 永远都不会关闭,所有的信息都可以通过。
Deep Residual Learning:
Residual Learning: 假设多堆叠层可以拟合一个底层函数 H(x),假设多层非线性层可以逼近复杂的函数,那他们也可以逼近残差函数 H(x)- x. 所以我们让这些层来拟合残差函数 F(x)=H(x)- x,原始的函数就变为了 F(x)+ x.这两个函数都可以逼近所需的函数(H(x)),就是难易程度不一样。
退化问题证明如果通过多层非线性来估计恒等映射会比较困难,如果通过残差学习,使得多层非线性层的权重趋于零来学习恒等映射会简单一些。
实际情况中,恒等映射不太可能达到最优,但是重新表达这个问题会有帮助。如果最优函数比较接近于恒等映射而不是零映射,那么求解器学习一个恒等映射的扰动比学习恒等映射简单。我们的实验证明,训练好的残差函数 response 都比较小,即恒等映射是比较合理的处理。
Identity Mapping by Shortcuts:我们在每一个堆叠层应用残差学习。一个残差的构建模块如上图2所示。我们定义一个 building block 函数为:![]() , x 和 y 分别为输入和输出,函数 F 是需要学习的残差函数。上图例2 中,有两层那么
, x 和 y 分别为输入和输出,函数 F 是需要学习的残差函数。上图例2 中,有两层那么 ![]() ,其中激活函数是 ReLU.bais被省略了。F + x 由 shortcut connection和 element-wise addition来实现。shortcut 连接并没有增加参数或者计算量。
,其中激活函数是 ReLU.bais被省略了。F + x 由 shortcut connection和 element-wise addition来实现。shortcut 连接并没有增加参数或者计算量。
上面的式子中 F 和 x 必须有相同的维度。残差函数 F 很灵活,可以有不同的形式,本文会有两层或者三层的结构,但是如果只有一层就变成了线性层![]() 并不会有提升。
并不会有提升。
Network Architectures:我们测试了很多的 plain/residual nets.
- Plain Network: 使用VGG模型,遵循两个规则,一是对于相同feature map size的层具有相同数量的 filter ,二是如果 feature map 的 size 减半,filter 的数量需要加倍来保持时间复杂度。通过卷积层来实现下采样,网络最后是 global average pooling layer 和softmax 层,整个结构如图三的中间,我们的模型比原始的 VGG 简单,有3.6 billion FLOPS(乘-加),是 VGG-19 的百分之十八。
- Residual Network:在 plain network 上增加 shortcut 来改成残差版本。如果输入和输出的维度相同,identity shortcut(恒等shortcut)可以直接使用,当维度增加时,考虑两点:1)仍然使用恒等映射,增加的维度使用 0 来填充,2)通过 1*1 的卷积来增加维度,如果 feature map 的尺寸发生变化,卷积的 stride 为2
Implementation:
image resize shorter side ,224*224 crop,per-pixel mean substracted,采用标准的颜色增强,在每一个卷积层后使用 BN,batch-size 为256,学习率为0.1,每次错误率平稳后,将学习率除以10,weight decay 为 0.0001,momentum 为 0.9.,不使用 drop out.
测试的时候,使用标准的 10-crop.使用全卷积的形式并且平均多尺度的分数(将图片的短边 resize 到{224,256,384,480,640})
Experiments:
ImageNet Classification:在 ImageNet 2012 分类数据集上评估方法
- Plain Networks: 首先评估 18 层和 34 层 plain nets.34 层就是上图的中间,18 层和它具有相似的结构,具体如下表所示
 我们发现 34 层比 18 的验证误差要大,在整个训练过程中,34 层的训练误差也比 18 层的大,即退化问题。这个问题不可能是因为梯度消失引起的,BN 层会确保前向传播的信号有非零的方差,后向传播梯度有健康的范式。所以前向后向信号都不会消失。我们推测深层网络的收敛速度是指数衰减的,这将会减少训练误差。这个原因我们未来会进行研究。
我们发现 34 层比 18 的验证误差要大,在整个训练过程中,34 层的训练误差也比 18 层的大,即退化问题。这个问题不可能是因为梯度消失引起的,BN 层会确保前向传播的信号有非零的方差,后向传播梯度有健康的范式。所以前向后向信号都不会消失。我们推测深层网络的收敛速度是指数衰减的,这将会减少训练误差。这个原因我们未来会进行研究。 - Residual Networks: 接下来我们评估了 18 层和 34 层残差网络。首先我们使用了 identity mapping for all shortcut 和 zero-padding 来增加维度,通过表 2 和图 4 ,我们可以发现,深层的残差可以克服退化问题

 而且深层的网络获得了更高的准确率,这证明了残差网络在深层网络的作用。而且残差网络收敛的更快。
而且深层的网络获得了更高的准确率,这证明了残差网络在深层网络的作用。而且残差网络收敛的更快。 - Identity vs Projection Shortcuts: 上面已经说明无参数的 identity shrotcuts 有助于训练,下面将会介绍 projected shrotcuts.在表 3 中我们分析了三种情况:(A)zero-padding;(B)projection shortcuts用来增加维度,其他的shortcuts 还是 identity;(C)所有的 shortcuts 都是 projections。由下表 3 可以看出,B 稍好于 A,我们分析这是因为 A 中的零填充并没有进行残差的学习,C 稍好于 B,我们把这归功于 C 中引入的额外的参数。所以证明 projection shortcuts 对解决退化问题并不是必需的。我们在之后我们将不会使用 C ,减少复杂度和模型的参数。Identity shortcut 对之后的 bottleneck 结构很重要。
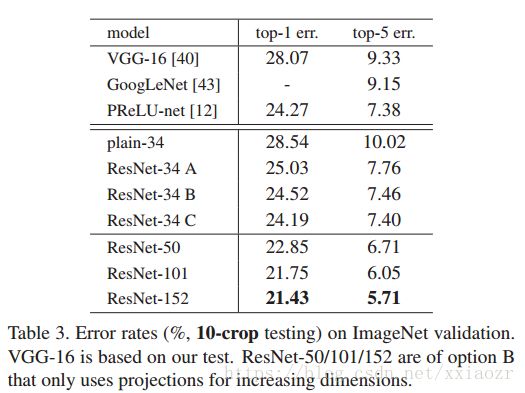
- Deeper Bottleneck Architectures:我们将 building block 修改为 bottleneck 来减少训练时间。对每一个残差函数 F,我们使用 3 层而不是 2 层,3 层分别为 1*1,3*3 , 1*1 的卷积。1*1 的卷积用来改变输入和输出的维度,使得 3*3 是一个具有小的输入输出维度的瓶颈。如下图 5 .这样 parameter-free 的 identity shortcuts 对 bottleneck 就十分重要了,因为 shortcut 和两个 high-dimensional ends 相连,使得模型复杂度加倍。

- 50-layer ResNet: 我们将 2-layer 的 block 用三层的 bottleneck block 代替,变成一个 50-layer 的 ResNet,使用 plan B 的 shortcuts
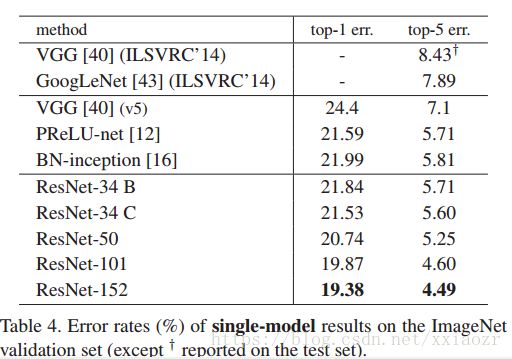
- 101-layer 和 152-layer RseNets:堆叠更多的 3-layer blocks来获得更深层的网络,仍然比 VGG-16/19 具有更少的复杂度
Analysis of Layer Responses:
图 7 展示了层响应的标准差。相应是每一个 3*3 卷积后,在 BN 之后,其他非线性(RELU/addition)之前。这个揭示了残差函数的响应强度,这证实了我们的初始动机,残差函数相比于非残差函数会趋近于零,而且更深层的残差网络越趋近于零。

Exploring Over 1000 layers : 对于更深的层,1202,我们没有优化的困难,也可以得到好的训练误差和测试误差,但是虽然它和一百多层有相同的训练误差,但是测试误差高于一百多层,我们把它归咎于过拟合。
Object Detection on PASCAL and MS COCO:
将 Faster R-CNN 的 VGG 替换成 ResNet-101