InfoGAN学习笔记
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, Pieter Abbeel
https://arxiv.org/abs/1606.03657
一、从GAN到InfoGAN
1.GAN存在的问题
GAN通过生成器与判别器的对抗学习,最终可以得到一个与real data分布一致的fake data,但是由于生成器的输入z是一个连续的噪声信号,并且没有任何约束,导致GAN无法利用这个z,并且无法将z的具体维度与数据的语义特征对应起来,并不是一个可解释的表示。
GAN存在的问题:无约束、不可控、噪声信号z很难解释等问题。
2.InfoGAN:通过最大化生成对抗网络的信息进行可解释的表示学习
InfoGAN是对GAN的一种改进,曾被OPENAI称为2016年的五大突破之一。
InfoGAN以此为出发点,试图利用z寻找一个可解释的表达,于是将z进行拆解,可分为如下两部分:
①z:不可压缩的噪声
②c:可解释的隐变量(latent code)
(其目的在于数据分布的显著结构化语义特征)
作者希望通过约束隐变量c与生成数据之间的关系,可以使得c里面包括有对数据的可解释信息。如文中提到的MNIST数据集,c可以分为categorial latent code指向数字种类信息(0-9),continous latent code指向倾斜度、粗细。
二、InfoGAN理论分析
1.无监督学习
(1)无监督学习是指从无标签数据中学习出关键的语义特征。然后利用该特征用于分类、回归、策略学习等。
(2)无监督学习的流行框架是表征学习,其目标是使用未标记的数据来学习将重要语义特征暴露为易于解码的要素表示。
(3)无监督学习的很大部分是由生成模型驱动的。
这是由于相信生成或创造观察到的数据需要某种形式理解的能力,希望一个良好的生成模型将自动学习一个特征分离的表示,即使很容易构建完美生成模型却具有随机不好的表示的。
2.disentangled representation
(1)无监督学习是一个病态问题,因为相关下游任务通常是未知的。
(2)数据的解耦表示对于相关的,但是未知的下游任务有比较好的效果。
数据的解耦表示:是显示表示数据的显著特征。
比如:对于人脸,一个有用的解耦表示就是将人脸表情、眼睛颜色、是否戴眼镜等一个个特征分别表示一个特征维度,每个维度的不同取值表示各个特征的取值。
3.隐变量c
①对应于语义向量,隐变量编码代表数据分布的显著特征的语义特征。
通过定义一系列的结构潜变量c1,c2,c3,……,相互独立,则:
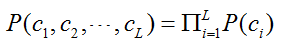
②标准GAN中,直接为网络的输入进行训练,那么生成器将忽略隐变量c的作用,即PG(x|c)=PG(x)。
或者可以看成隐变量c与x相互独立,不相关。
③InfoGAN提出一种无监督方式,让生成网络输入噪声变量z和隐变量c。即生成网络表示为G(z,c)。
④InfoGAN需要强化隐变量c的作用,使c能够直接代表生成的变量的某一方面的属性,所以需要让隐变量与生成的变量G(z,c)拥有尽可能多的共同信息。
4.互信息I(X;Y)(最大化隐变量与生成结果的互信息)
InfoGAN的目标:是加入一个新的隐变量c,使得c与生成的样本具有较高的互信息。这样c用于表示数据某个方面的语义信息,z用于表示样本x中与c无关的其它信息。
![]()
①定量互信息I(c;G(z.c))—>(InfoGAN提出信息正则化约束项)
在信息论中,I(x;y)表示x里面关于y的信息有多少;
②在原始GAN损失函数V(D,G)基础上,提出加入信息正则化约束项I(c;G(z.c))
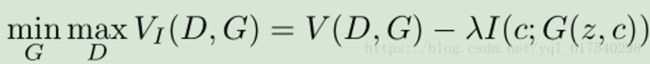
③优化函数,采用近似方法
求I需要涉及到P(c|x),但是分布很难求。使用下界代替I来进行简化。
简化之后,函数I不在需要使用P(c|x)而是使用了一个下界函数Q(c|x) 作为因子高斯来进行替代,而Q(c|x)本质上是对P(c|x)的拟合;
简化之后,虽然不需要使用P(c|x),但是需要从P(c|x)中采样以计算期望。当c包含连续变量时,较小的通常用于确保的微分熵与GAN目标规模相同。

在具体实现中,Q和D共用了所有的卷积层,并只在最后增加了一个全连接层来输出Q(c|x),因此InfoGAN并没有在GAN上增加多少计算量。
三、InfoGAN建模分析
1.InfoGAN三个网络:
①生成网络x=G(c,z)
②判别真伪网络y1=D1(x)
③判别类别c网络y2=D2(x)
当c用于代表类别信息的时候,网络的最后一层是softmax层。且D1(x)和D2(x)共享网络参数。
2.实验设置以及结果
(1)文中提到实验的两个目标:
①第一个目标是调查互信息是否可以有效地最大化;
②第二个目标是评估如果InfoGAN可以通过利用生成器来一次只改变一个潜在因素来学习分离和可解释的表示,以便评估如果这样的变化因素仅导致生成的图像中的一种类型的语义变化。
(2)实验结果分析
①评估隐变量c和生成图像G(z,c)之间的互信息有效最大化
在MNIST数据集上训练InfoGAN,对隐变量c进行统一的分类分布
![]()
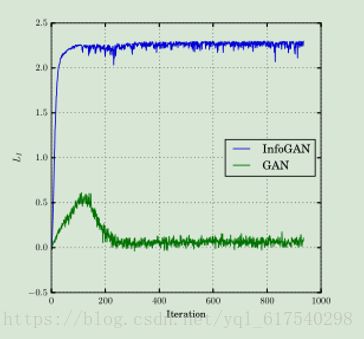
②MNIST数据集
一个分类代码c1对潜在代码进行建模:C1~Cat(K = 10,p = 0.1),可以模拟数据中的不连续变化;可以捕获本质上连续变化的两个连续码:c2,c3~ Unif(-1,1);
连续码c2,c3捕获样式的连续变化:c2控制数字旋转角度和c3控制数字书写宽度。
(a图)c1中的每个类别基于对应一个数字类型;
(b图)在没有信息正则化的情况下,在GAN变化的c1导致不可解释的变化;
(c图)c2小值表示向左倾,大值表示向右倾;
(d图)c3平滑的控制宽度。
③3D Faces数据集
学习连续变量使输出的值从(-1,1)变化不等。
(a图)连续潜变量始终捕捉不同的形状脸的方位角;
(d图)连续潜变量在保留其他视觉特征的同时,学习在宽度和窄面之间进行插值。
④3D Chairs数据集
(a图)用连续码捕捉椅子的方位,并保持其形状(映射在不同的类型变化);
(b图)连续码捕捉不同椅子的宽度,平滑的展示出来。
⑤StreetView House Number(SVHN)数据集
(a图)连续码:光照
(b图)离散码:上下文
⑥CelebA数据集
(a图)方位角:分类码可以通过离散化这种连续性质的变化来捕捉方位角;
(b图)在分类码的一个子集用于表示眼镜是否存在;
(c图)显示发型的变化,大致从较少的发型到较多的发型;
(d图)显示情感的变化,大致从严肃到高兴。
四、结论
(1)InfoGAN介绍了一种称为信息最大化生成对抗网络的表示学习算法
与之前的需要监督的方法相比,InfoGAN完全没有监督,可以在具有挑战性的数据集上学习可解释和解耦的表示。
(2)InfoGAN也是一个生成对抗网络
最大化潜在变量的一小部分与观察(生成)结果之间的互信息。得出可以有效优化的互信息目标的下限。
(3)实验验证结果
InfoGAN成功地将MNIST数据集上的数字形状的写作风格,3D渲染图像的照明姿势,以及SVHN数据集中央数字的背景分离。它还发掘包括发型,是否存在眼镜和CelebA面部数据集上的情感等视觉概念。实验表明,InfoGAN可以学习与现有监督方法学习的表征具有竞争力的可解释性表征。