https://blog.csdn.net/nockinonheavensdoor/article/details/82320580
先看看简单例子:
import torch
import torch.autograd as autograd import torch.nn as nn import torch.nn.functional as F import torch.optim as optim torch.manual_seed(1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 用
torch.tensor让list成为tensor:
# Create a 3D tensor of size 2x2x2.
T_data = [[[1., 2.], [3., 4.]],
[[5., 6.], [7., 8.]]]
T = torch.tensor(T_data)
print(T)- 1
- 2
- 3
- 4
- 5
- 自动求导设
requires_grad=True:
# Computation Graphs and Automatic Differentiation
x = torch.tensor([1., 2., 3], requires_grad=True) y = torch.tensor([4., 5., 6], requires_grad=True) z = x + y print(z) print(z.grad_fn) tensor([ 5., 7., 9.]) 0x00000247781E0BE0> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
detach()方法获取z的值,但是不能对获取后的值求导了。
new_z = z.detach()
print(new_z.grad_fn)
None- 1
- 2
- 3
- 4
- 好了,重点来了
Translation with a Sequence to Sequence Network and Attention
from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata import string import re import random import torch import torch.nn as nn from torch import optim import torch.nn.functional as F device = torch.device("cuda" if torch.cuda.is_available() else "cpu")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
准备数据:
SOS_token = 0
EOS_token = 1
class lang: def __init__(self, name): self.name = name self.word2index = {} self.word2count = {} self.index2word = {0:'SOS', 1:'EOS'} self.n_words = 2 # Count SOS and EOS def addSentence(self, sentence): for word in sentence.split(): self.addWord(word) def addWord(self, word): if word not in self.word2index: self.word2index[word] = self.n_words self.word2count[word] = 1 self.index2word[self.n_words] = word self.n_words += 1 else: self.word2count[word] += 1 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- Unicode字符转为ASCII,用小写字母表示一切,去掉标点符号:
# Turn a Unicode string to plain ASCII, thanks to
# http://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s): return ''.join( c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn' ) # Lowercase,trim,remove non-letter characters #re.sub(pattern, repl, string, count=0, flags=0) def normalizeString(s): s = unicodeToAscii(s.lower().strip()) # (re) 匹配括号内的表达式,也表示一个组 # [...] 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' # \1...\9 匹配第n个分组的内容。 s = re.sub(r"([.!?])", r"\1", s) # [^...] 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 s = re.sub(r"[^a-zA-Z.!?]+",r" ", s) return s - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
继续:
# 文件用的英语到其他语言,用reverse标志置换一对这样的数据。
def readlangs(lang1, lang2, reverse= False): print("Reading lines...") #Read the file and split into lines lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\ read().strip().split('\n') # Split every line into pairs and normalize pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines] # Reverse pairs, make lang instances if reverse: pairs = [list(reversed(p)) for p in pairs] input_lang = lang(lang2) output_lang = lang(lang1) else: input_lang = lang(lang1) output_lang = lang(lang2) return input_lang, output_lang, pairs- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
过滤出部分样本:
MAX_LENGTH = 10
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ", "she is", "she s", "you are", "you re ", "we are", "we re ", "they are", "they re " ) def filterPair(p): return len(p[0].split(' ')) < MAX_LENGTH and \ len(p[1].split(' ')) < MAX_LENGTH and \ p[1].startswith(eng_prefixes) def filterPairs(pairs): return [ pair for pair in pairs if filterPair(pair)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
-
The full process for preparing the data is:
- Read text file and split into lines, split lines into pairs
- Normalize text, filter by length and content
- Make word lists from sentences in pairs
def prepareData(lang1, lang2, reverse= False):
input_lang, output_lang, pairs = readlangs(lang1,lang2,reverse)
print("Read %s sentence pairs " % len(pairs)) pairs = filterPairs(pairs) print("Trimmed to %s sentence pairs " % len(pairs)) print("Counting words...") for pair in pairs: input_lang.addSentence(pair[0]) output_lang.addSentence(pair[1]) print("Counted word:") print(input_lang.name,input_lang.n_words) print(output_lang.name, output_lang.n_words) return input_lang, output_lang, pairs input_lang, output_lang, pairs = prepareData('eng','fra',True) print(random.choice(pairs)) Reading lines... Read 135842 sentence pairs Trimmed to 11739 sentence pairs Counting words... Counted word: fra 5911 eng 3965 ['elle chante les dernieres chansons populaires.', 'she is singing the latest popular songs.'] - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
The Seq2Seq Model

- 允许句子到句子有不同长度和顺序。
The Encoder :

#编码器
class EncoderRNN(nn.Module): def __init__(self, input_size, hidden_size): super(EncoderRNN, self).__init__() self.hidden_size = hidden_size # 指定embedding矩阵W的大小维度 self.embedding = nn.Embedding(input_size, hidden_size) # 指定gru单元的大小 self.gru = nn.GRU(hidden_size, hidden_size) def forward(self, input, hidden): # 扁平化嵌入矩阵 embedded = self.embedding(input).view(1, 1, -1) print("embedded shape:",embedded.shape) output = embedded output, hidden = self.gru(output, hidden) return output, hidden #全0初始化隐层 def initHidden(self): # 这个初始化维度可以 return torch.zeros(1, 1, self.hidden_size, device=device)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
这里的self.gru = nn.GRU(hidden_size, hidden_size)中,hidden_size在后面设置为256
print("embedded shape:",embedded.shape)的结果是:
embedded shape: torch.Size([1, 1, 256])
所以self.gru(output, hidden)中传递的第一个维度是[1,1,256],被压缩为这样的。
nn.GRU源码:
The Decoder:
- seq2seq解码器的简化版:指利用encoder的最后输出,称为context vector,
- context vector 作为decoder的初始化隐层状态值

class DecoderRNN(nn.Module):
def self__init__(self, hidden_size, output_size): super(DecoderRNN, self).__init__() self.hidden_size = hidden_size self.embedding = nn.Embedding(output_size,hidden_size) self.gru = nn.GRU(hidden_size, hidden_size) self.out = nn.Linear(hidden_size, output_size) self.softmax = nn.LogSoftmax(dim=1) def forward(self, input, hidden): output = self.embedding(input).view(1, 1, -1) # 1行X列的shape做relu output = F.relu(output) output, hidden = self.gru(output, hidden) #output[0]应该是shape为(*,*)的矩阵 output = self.softmax(self.out(output[0])) return output, hidden def initHidden(self): return torch.zeros(1, 1, self.hidden_size, device=device)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Attention Decoder:
- 简单的解码器的缺点:把整个句子做编码成一个向量,信息容易丢失,翻译一个词的时候需要追溯之前很长的距离,一般翻译的对应性也没有利用,如翻译第一个词,对应大概率在原句子的第一个位置的信息。
- encoder的输出向量 会乘以一个attention weights,这个权值用NN来计算完成attn,使用解码器的输入和隐藏状态作为输入。。
- 因为在训练数据中有各种大小的句子,为了实际创建和训练这一层,我们必须选择一个最大的句子长度(输入长度,对于编码器输出)因为在训练数据中有各种大小的句子,为了实际创建和训练这一层,我们必须选择一个最大的句子长度(输入长度,对于编码器输出)
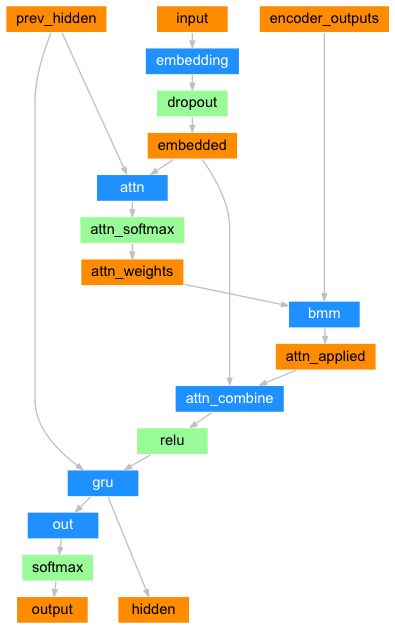
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size,
dropout_p = 0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN,self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p self.max_length = max_length self.embedding = nn.Embedding(self.output_size, self.hidden_size) self.attn = nn.Linear(self.hidden_size * 2, self.max_length) self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size) self.dropout = nn.Dropout(self.dropout_p) #输入向量的维度是10,隐层的长度是10,默认是一层GRU self.gru = nn.GRU(self.hidden_size, self.hidden_size) self.out = nn.Linear(self.hidden_size, self.output_size) def forward(self, input, hidden, encoder_outputs): embedded = self.embedding(input).view(1,1,-1) embedded = self.dropout(embedded) attn_weights = F.softmax( self.attn(torch.cat((embedded[0],hidden[0]),1)),dim=1) # unsqueeze:在指定的轴上多增加一个维度 attn_applied = torch.bmm(attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0)) output = torch.cat((embedded[0],attn_applied[0]),1) output = self.attn_combine(output).unsqueeze(0) output = F.relu(output) output, hidden = self.gru(output, hidden) #print("output shape:",output.shape) #print("output[0]:",output[0]) output = F.log_softmax(self.out(output[0]),dim=1) return output , hidden, attn_weights def initHidden(self): return torch.zeros(1, 1, self.hidden_size, device=device) - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
继续准备数据:
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')] def tensorFromSentence(lang, sentence): indexes = indexesFromSentence(lang, sentence) indexes.append(EOS_token) return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1) def tensorsFromPair(pair): input_tensor = tensorFromSentence(input_lang, pair[0]) target_tensor = tensorFromSentence(output_lang, pair[1]) return (input_tensor, target_tensor)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
训练模型
- 解码器的第一个输入是SOS符,并且把编码器最后的隐层状态作为解码器的第一隐层状态。
- “Teacher forcing”指用真实样本数据作为下一步的输入,而不是解码器猜测的数据作为下一步输入。
teacher_forcing_ratio = 0.5
def train(input_tensor, output_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH): # 这的隐层大小封装在encoder中,然后拿过来在train的时候初始化隐层的大小 encoder_hidden = encoder.initHidden() encoder_optimizer.zero_grad() decoder_optimizer.zero_grad() # 第一维度的大小即输入长度 input_length = input_tensor.size(0) output_length = output_tensor.size(0) encoder_outputs = torch.zeros(max_length, encoder.hidden_size,device=device) loss = 0 for ei in range(input_length): encoder_output, encoder_hidden = encoder(input_tensor[ei],encoder_hidden) # [0,0]选取最大数组的第一个元素组里的第一个 encoder_outputs[ei] = encoder_output[0 , 0] if ei == 0 : print("encoder_output[0, 0] shape: ",encoder_outputs[ei].shape) decoder_input = torch.tensor([[SOS_token]], device=device) decoder_hidden = encoder_output # niubi use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False if use_teacher_forcing: # Teacher forcing: Feed the target as the next input for di in range(output_length): decoder_ouput,decoder_hidden,decoder_attention = decoder( decoder_input, decoder_hidden, encoder_outputs) loss = loss + criterion(decoder_ouput, output_tensor[di]) decoder_input = output_tensor[di] # Teacher forcing else: for di in range(output_length): decoder_output,decoder_hidden,decoder_attention=decoder(decoder_input, decoder_hidden, encoder_outputs) topv ,topi = decoder_output.topk(1) decoder_input= topi.squeeze().detach() # # detach from history as input loss = loss + criterion(decoder_output, output_tensor[di]) if decoder_input.item() == EOS_token: break loss.backward() encoder_optimizer.step() decoder_optimizer.step() return loss.item() / target_length- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
好了,模型准备结束:
import time
import math
def asMinutes(s): m = math.floors(s / 60) s -= m * 60 return "%s(- %s)" % (asMinutes(s), asMinutes(rs)) def timeSince(since, percent): now = time.time() s = now - since es = s / (percent) rs = es - s return '%s (- %s)' % (asMinutes(s), asMinutes(rs))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
训练过程:
def trainIters(encoder, decoder, n_iters, print_every=1000, plot_every=100, learning_rate=0.01): start = time.time() plot_losses = [] print_loss_total = 0 # Reset every print_every plot_loss_total = 0 # Reset every plot_every encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate) decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate) training_pairs = [tensorsFromPair(random.choice(pairs)) for i in range(n_iters)] criterion = nn.NLLLoss() for iter in range(1, n_iters + 1): training_pair = training_pairs[iter - 1] input_tensor = training_pair[0] target_tensor = training_pair[1] loss = train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion) print_loss_total = loss + print_loss_total plot_loss_total = loss + plot_loss_total if iter % print_every == 0: print_loss_avg = print_loss_total / print_every print_loss_total = 0 print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters), iter, iter / n_iters * 100, print_loss_avg)) if iter % plot_every == 0: plot_loss_avg = plot_loss_total / plot_every plot_losses.append(plot_loss_avg) plot_loss_total = 0 showPlot(plot_losses)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
画图的这段:
import matplotlib.pyplot as plt
plt.switch_backend('agg')
import matplotlib.ticker as ticker import numpy as np def showPlot(points): plt.figure() fig, ax = plt.subplots() # this locator puts ticks at regular intervals loc = ticker.MultipleLocator(base=0.2) ax.yaxis.set_major_locator(loc) plt.plot(points)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
验证的代码:
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):
with torch.no_grad(): input_tensor = tensorFromSentence(input_lang, sentence) input_length = input_tensor.size()[0] encoder_hidden = encoder.initHidden() encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device) for ei in range(input_length): encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden) encoder_outputs[ei] += encoder_output[0, 0] decoder_input = torch.tensor([[SOS_token]], device=device) # SOS decoder_hidden = encoder_hidden decoded_words = [] decoder_attentions = torch.zeros(max_length, max_length) for di in range(max_length): decoder_output, decoder_hidden, decoder_attention = decoder( decoder_input, decoder_hidden, encoder_outputs) decoder_attentions[di] = decoder_attention.data topv, topi = decoder_output.data.topk(1) if topi.item() == EOS_token: decoded_words.append('') break else: decoded_words.append(output_lang.index2word[topi.item()]) decoder_input = topi.squeeze().detach() return decoded_words, decoder_attentions[:di + 1] - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
def evaluateRandomly(encoder, decoder, n=10): for i in range(n): pair = random.choice(pairs) print('>', pair[0]) print('=', pair[1]) output_words, attentions = evaluate(encoder, decoder, pair[0]) output_sentence = ' '.join(output_words) print('<', output_sentence) print('')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
最后一步:
hidden_size = 256
encoder1 = EncoderRNN(input_lang.n_words, hidden_size).to(device)
attn_decoder1 = AttnDecoderRNN(hidden_size, output_lang.n_words, dropout_p=0.1).to(device) trainIters(encoder1, attn_decoder1, 75000, print_every=5000)先看看简单例子:
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 用
torch.tensor让list成为tensor:
# Create a 3D tensor of size 2x2x2.
T_data = [[[1., 2.], [3., 4.]],
[[5., 6.], [7., 8.]]]
T = torch.tensor(T_data)
print(T)- 1
- 2
- 3
- 4
- 5
- 自动求导设
requires_grad=True:
# Computation Graphs and Automatic Differentiation
x = torch.tensor([1., 2., 3], requires_grad=True)
y = torch.tensor([4., 5., 6], requires_grad=True)
z = x + y
print(z)
print(z.grad_fn)
tensor([ 5., 7., 9.])
0x00000247781E0BE0> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
detach()方法获取z的值,但是不能对获取后的值求导了。
new_z = z.detach()
print(new_z.grad_fn)
None- 1
- 2
- 3
- 4
- 好了,重点来了
Translation with a Sequence to Sequence Network and Attention
from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata
import string
import re
import random
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
准备数据:
SOS_token = 0
EOS_token = 1
class lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0:'SOS', 1:'EOS'}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
for word in sentence.split():
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- Unicode字符转为ASCII,用小写字母表示一切,去掉标点符号:
# Turn a Unicode string to plain ASCII, thanks to
# http://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# Lowercase,trim,remove non-letter characters
#re.sub(pattern, repl, string, count=0, flags=0)
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
# (re) 匹配括号内的表达式,也表示一个组
# [...] 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k'
# \1...\9 匹配第n个分组的内容。
s = re.sub(r"([.!?])", r"\1", s)
# [^...] 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。
s = re.sub(r"[^a-zA-Z.!?]+",r" ", s)
return s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
继续:
# 文件用的英语到其他语言,用reverse标志置换一对这样的数据。
def readlangs(lang1, lang2, reverse= False):
print("Reading lines...")
#Read the file and split into lines
lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
# Reverse pairs, make lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = lang(lang2)
output_lang = lang(lang1)
else:
input_lang = lang(lang1)
output_lang = lang(lang2)
return input_lang, output_lang, pairs- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
过滤出部分样本:
MAX_LENGTH = 10
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and \
len(p[1].split(' ')) < MAX_LENGTH and \
p[1].startswith(eng_prefixes)
def filterPairs(pairs):
return [ pair for pair in pairs if filterPair(pair)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
-
The full process for preparing the data is:
- Read text file and split into lines, split lines into pairs
- Normalize text, filter by length and content
- Make word lists from sentences in pairs
def prepareData(lang1, lang2, reverse= False):
input_lang, output_lang, pairs = readlangs(lang1,lang2,reverse)
print("Read %s sentence pairs " % len(pairs))
pairs = filterPairs(pairs)
print("Trimmed to %s sentence pairs " % len(pairs))
print("Counting words...")
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("Counted word:")
print(input_lang.name,input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('eng','fra',True)
print(random.choice(pairs))
Reading lines...
Read 135842 sentence pairs
Trimmed to 11739 sentence pairs
Counting words...
Counted word:
fra 5911
eng 3965
['elle chante les dernieres chansons populaires.', 'she is singing the latest popular songs.']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
The Seq2Seq Model
- 允许句子到句子有不同长度和顺序。
The Encoder :
#编码器
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
# 指定embedding矩阵W的大小维度
self.embedding = nn.Embedding(input_size, hidden_size)
# 指定gru单元的大小
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
# 扁平化嵌入矩阵
embedded = self.embedding(input).view(1, 1, -1)
print("embedded shape:",embedded.shape)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
#全0初始化隐层
def initHidden(self):
# 这个初始化维度可以
return torch.zeros(1, 1, self.hidden_size, device=device)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
这里的self.gru = nn.GRU(hidden_size, hidden_size)中,hidden_size在后面设置为256
print("embedded shape:",embedded.shape)的结果是:
embedded shape: torch.Size([1, 1, 256])
所以self.gru(output, hidden)中传递的第一个维度是[1,1,256],被压缩为这样的。
nn.GRU源码:
The Decoder:
- seq2seq解码器的简化版:指利用encoder的最后输出,称为context vector,
- context vector 作为decoder的初始化隐层状态值
class DecoderRNN(nn.Module):
def self__init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size,hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
# 1行X列的shape做relu
output = F.relu(output)
output, hidden = self.gru(output, hidden)
#output[0]应该是shape为(*,*)的矩阵
output = self.softmax(self.out(output[0]))
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Attention Decoder:
- 简单的解码器的缺点:把整个句子做编码成一个向量,信息容易丢失,翻译一个词的时候需要追溯之前很长的距离,一般翻译的对应性也没有利用,如翻译第一个词,对应大概率在原句子的第一个位置的信息。
- encoder的输出向量 会乘以一个attention weights,这个权值用NN来计算完成attn,使用解码器的输入和隐藏状态作为输入。。
- 因为在训练数据中有各种大小的句子,为了实际创建和训练这一层,我们必须选择一个最大的句子长度(输入长度,对于编码器输出)因为在训练数据中有各种大小的句子,为了实际创建和训练这一层,我们必须选择一个最大的句子长度(输入长度,对于编码器输出)
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size,
dropout_p = 0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN,self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
#输入向量的维度是10,隐层的长度是10,默认是一层GRU
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1,1,-1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0],hidden[0]),1)),dim=1)
# unsqueeze:在指定的轴上多增加一个维度
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0],attn_applied[0]),1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
#print("output shape:",output.shape)
#print("output[0]:",output[0])
output = F.log_softmax(self.out(output[0]),dim=1)
return output , hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
继续准备数据:
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
训练模型
- 解码器的第一个输入是SOS符,并且把编码器最后的隐层状态作为解码器的第一隐层状态。
- “Teacher forcing”指用真实样本数据作为下一步的输入,而不是解码器猜测的数据作为下一步输入。
teacher_forcing_ratio = 0.5
def train(input_tensor, output_tensor, encoder, decoder, encoder_optimizer,
decoder_optimizer, criterion, max_length=MAX_LENGTH):
# 这的隐层大小封装在encoder中,然后拿过来在train的时候初始化隐层的大小
encoder_hidden = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# 第一维度的大小即输入长度
input_length = input_tensor.size(0)
output_length = output_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size,device=device)
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei],encoder_hidden)
# [0,0]选取最大数组的第一个元素组里的第一个
encoder_outputs[ei] = encoder_output[0 , 0]
if ei == 0 :
print("encoder_output[0, 0] shape: ",encoder_outputs[ei].shape)
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_output
# niubi
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
# Teacher forcing: Feed the target as the next input
for di in range(output_length):
decoder_ouput,decoder_hidden,decoder_attention = decoder( decoder_input, decoder_hidden, encoder_outputs)
loss = loss + criterion(decoder_ouput, output_tensor[di])
decoder_input = output_tensor[di] # Teacher forcing
else:
for di in range(output_length):
decoder_output,decoder_hidden,decoder_attention=decoder(decoder_input, decoder_hidden, encoder_outputs)
topv ,topi = decoder_output.topk(1)
decoder_input= topi.squeeze().detach() # # detach from history as input
loss = loss + criterion(decoder_output, output_tensor[di])
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
好了,模型准备结束:
import time
import math
def asMinutes(s):
m = math.floors(s / 60)
s -= m * 60
return "%s(- %s)" % (asMinutes(s), asMinutes(rs))
def timeSince(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return '%s (- %s)' % (asMinutes(s), asMinutes(rs))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
训练过程:
def trainIters(encoder, decoder, n_iters, print_every=1000, plot_every=100, learning_rate=0.01):
start = time.time()
plot_losses = []
print_loss_total = 0 # Reset every print_every
plot_loss_total = 0 # Reset every plot_every
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
training_pairs = [tensorsFromPair(random.choice(pairs))
for i in range(n_iters)]
criterion = nn.NLLLoss()
for iter in range(1, n_iters + 1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = train(input_tensor, target_tensor, encoder,
decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total = loss + print_loss_total
plot_loss_total = loss + plot_loss_total
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters),
iter, iter / n_iters * 100, print_loss_avg))
if iter % plot_every == 0:
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
showPlot(plot_losses)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
画图的这段:
import matplotlib.pyplot as plt
plt.switch_backend('agg')
import matplotlib.ticker as ticker
import numpy as np
def showPlot(points):
plt.figure()
fig, ax = plt.subplots()
# this locator puts ticks at regular intervals
loc = ticker.MultipleLocator(base=0.2)
ax.yaxis.set_major_locator(loc)
plt.plot(points)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
验证的代码:
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentence)
input_length = input_tensor.size()[0]
encoder_hidden = encoder.initHidden()
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei],
encoder_hidden)
encoder_outputs[ei] += encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device) # SOS
decoder_hidden = encoder_hidden
decoded_words = []
decoder_attentions = torch.zeros(max_length, max_length)
for di in range(max_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
decoder_attentions[di] = decoder_attention.data
topv, topi = decoder_output.data.topk(1)
if topi.item() == EOS_token:
decoded_words.append('' )
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach()
return decoded_words, decoder_attentions[:di + 1]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
def evaluateRandomly(encoder, decoder, n=10):
for i in range(n):
pair = random.choice(pairs)
print('>', pair[0])
print('=', pair[1])
output_words, attentions = evaluate(encoder, decoder, pair[0])
output_sentence = ' '.join(output_words)
print('<', output_sentence)
print('')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
最后一步:
hidden_size = 256
encoder1 = EncoderRNN(input_lang.n_words, hidden_size).to(device)
attn_decoder1 = AttnDecoderRNN(hidden_size, output_lang.n_words, dropout_p=0.1).to(device)
trainIters(encoder1, attn_decoder1, 75000, print_every=5000)