手把手教你用PyTorch实现图像分类器(第二部分) ...

本文为 AI 研习社编译的技术博客,原标题 :
Implementing an Image Classifier with PyTorch: Part 2
作者 | Jose Nieto
翻译 | Jeffery26
校对 | 酱番梨 审核 | 酱番梨 整理 | 立鱼王
原文链接:
https://medium.com/udacity/implementing-an-image-classifier-with-pytorch-part-2-ae4dd7b2f48
查看第一部分,请戳>>手把手教你用PyTorch实现图像分类器(第一部分)

回想一下,在本系列文章的第一篇中,我们学习了为什么需要载入预训练网络以及如何载入预训练网络,同时我们演示了如何将预训练网络的分类器替换为我们自己的分类器。在本篇推文中,我们将学习如何训练自己的分类器。
训练分类器
首先我们要做的是将训练用的图片喂给我们的分类器,我们可以使用PyTorch中的ImageFolder接口载入图片。预训练网络要求我们输入的都是某种特定格式的图片,因此,在将图片喂给神经网络前,我们需要对图片进行某些变换以达到对图片的裁剪和归一化。
具体来说,我们会将输入图片裁剪至224x224尺寸并且使用[0.485, 0.456, 0.406]和[0.229, 0.224, 0.225]两个参数作为均值和标准差进行归一化。归一化使得图片颜色通道数值中心化于0同时使得标准差为1。
接着我们可以使用PyTorch中的DataLoader接口将所有图片分成不同的批次。因为我们需要三种图片数据集——训练集,验证集和测试集,所以我们需要为每个数据集分别创建一个读取器。好了,万事俱备,我们可以开始训练我们的分类器了。
进行到此处我们将碰到最重要的挑战:模型准确度
让我们的模型去识别一张我们事先已经标注好类别的图片并不难,然而我们需要我们的模型拥有泛化能力,即让模型可以识别我们从未标注过的花卉图片中的花卉种类。我们可以通过防止模型的过拟合达到模型泛化的目的。过拟合的意思为:我们的模型参数太过于满足我们自己的训练图片的准确度,从而可能导致无法对除了训练集之外的其他图片进行准确识别。即模型在训练集上表现优越,但是在测试集和验证集上误差很大。
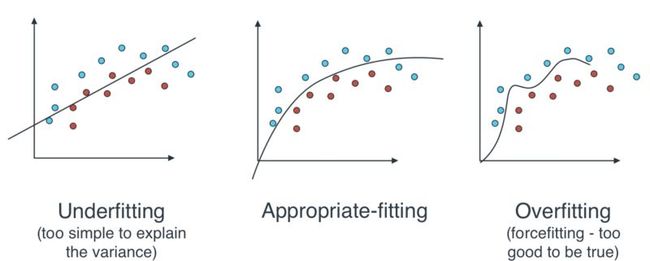
Fitting types
不同的参数可以帮助模型达到最佳拟合
-隐藏层
我们总是很容易陷入更多或更大的隐藏层能够提高分类器准确性这样的思维误区,然而这个说法不总是对的。
增加隐藏层的数量和尺寸会使得我们的分类器考虑更多除了那些至关重要的参数以外的参数。例如,将噪音也视为花卉的一部分。这将导致过拟合以及模型准确度的下降。不仅如此,增加隐藏层的数量和尺寸也将花费我们更多时间去训练分类器和利用分类器去预测结果。
正因如此,我们建议开始训练网络时采用较少数量和较小尺寸的隐藏层,同时隐藏层的数量和尺寸根据训练进展按需增加,而不是一开始便在网络中加入大量和大尺寸的隐藏层。
在Udacity的利用python进行AI编程纳米学位项目中的花卉分类器项目中(我在本系列文章的第一篇推文中介绍了该项目),利用训练集进行第一次全训练轮次时,我仅仅利用包含一层小规模隐藏层的网络便获得了超过70%的准确度
-数据增强
我们有一批图片用来训练我们的模型,这是极好的事情,但是如果我们有更多的图片,这将会变得更好。此时数据增强便派上了用场。在训练模型的每一回合中,每张图片会被喂入网络一次。但是在每次喂给网络之前,我们可以对图片进行任意的变换,例如旋转,平移,缩放。通过这种方式,在不同的训练回合中,同一张图片将会以不同的形式喂给神经网络。增加训练数据的多样性可以减少过拟合的出现概率,相应地也提高了模型的泛化能力,从而提高了模型总体的准确性。
-打乱数据集
当训练神经网络时,为了防止模型出现任何偏向性,我们需要以任意顺序将图片喂给神经网络。
例如,一开始如果我们只将矮牵牛花图片喂给分类器,那么该分类器的张量很容易倾向于矮牵牛花。事实上,此时此刻,我们的分类器将会只知道矮牵牛花这一种花。即使接下来我们使用其他种类花卉图片来继续训练模型,这种最初的对于某种花卉的倾向性将会随着时间继续存在。雷锋网
为了防止这种现象的发生,我们需要在数据载入器中打乱图片顺序,只需要简单的一步——在创建载入器时添加shuffle=True语句即可。
-随机失活
有时,分类器内的神经网络节点会产生过多的影响,从而使得其他节点不能进行正常的训练。同时,节点之间会产生相互依存关系从而导致过拟合。
随机失活是在每一次训练中通过使一些节点随机失活来防止上述现象发生的一种训练技巧。因而,每一次训练中分别训练了所有节点中的不同子集,从而减少了过拟合现象的发生。

Dropout diagram (Source)
暂且先不谈论过拟合,我们需要时刻记住的是学习率可能是最重要的超参数。如果学习率太大,我们可能永远得不到误差的最小值,如果学习率太小,分类器的训练过程会变得非常漫长。典型的学习率数值分别是:0.01,0.001,0.0001等等。
最后但也仍然非常重要的是,对位于分类器最后一层的激活函数的正确选择也会大幅改善模型准确度。例如,如果在神经网络中我们使用了负对数似然损失函数,按照文档所述,那么建议在最后一层使用LogSoftmax激活函数。雷锋网
总结
为了训练一个拥有泛化能力,同时在预测新图片中的花卉种类有着高准确度的模型,理解模型训练过程是非常有用的。
在文章中我们讨论了过拟合是如何影响模型的泛化能力以及如何防止过拟合的发生。同时我们也提及了学习率的重要性以及常用的学习率。最后,我们可以看出在最后一层中选择正确的激活函数也是至关重要的。
既然我们知道了如何训练模型,我们便可以使用模型去识别模型从未见过的图片中的花卉种类。那将是我们在该系列第三篇和最后一篇推文中将要介绍的内容。
我希望此篇文章对你有所帮助同时你能对我们说出你对此篇文章的想法。
想要继续查看该篇文章相关链接和参考文献?
点击【手把手教你用PyTorch实现图像分类器(第二部分)】即可访问:雷锋网(公众号:雷锋网)
https://ai.yanxishe.com/page/TextTranslation/1587
AI入门、大数据、机器学习免费教程
35本世界顶级原本教程限时开放,这类书单由知名数据科学网站 KDnuggets 的副主编,同时也是资深的数据科学家、深度学习技术爱好者的Matthew Mayo推荐,他在机器学习和数据科学领域具有丰富的科研和从业经验。
点击链接即可获取:https://ai.yanxishe.com/page/resourceDetail/417