LabelEncoder 和 OneHotEncoder 辨析
在特征工程工程中处理离散数据时候,需要将原来的数据转化成数字格式才能传入 模型,这时候需要用到两个编码函数
1 labelEncoder
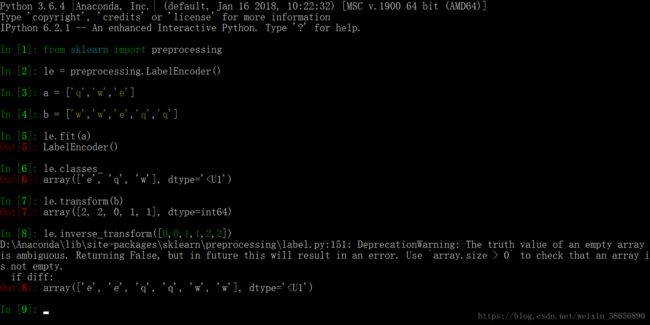
LabelEncoder 可以理解为一个打标签的机器
首先 通过 fit 列表 a 来得到所有标签的种类, a 中可以有重复的数据,这个种类也就是 a 中所有不同数据的 集合,可以通过 le.classes_ 来查看,并且会给定顺序,每个数据有对应的序号,在对其他数据列表进行标记时候,返回 每个数据对应的序号,通过 inverse_transform 还可以实现反向编码
2、OneHotEncoder
这个就比较厉害 了 ,我们用一个例子来说明
有如下三个特征属性:
性别:[“male”,“female”]
地区:[“Europe”,“US”,“Asia”]
浏览器:[“Firefox”,“Chrome”,“Safari”,“Internet Explorer”]
对于某一个样本,如[“male”,“US”,“Internet Explorer”],我们需要将这个分类值的特征数字化,最直接的方法,我们可以采用序列化的方式:[0,1,3]。但是这样的特征处理并不能直接放入机器学习算法中。
对于上述的问题,性别的属性是二维的,所以编码是两位 对应male 和 female 分别是 [1,0] , [0,1]
地区为三位 分别是 [1,0,0] , [0,1,0] , [0,0,1]
浏览器为 [1,0,0,0] ,[0,1,0,0] , [0,0,1,0] , [0,0,0,1]
那么样本对应就是 [ 1,0 , 0,1,0 , 0,0,0,1]
这样导致的一个结果就是数据会变得非常的稀疏
下面我们用代码实现

解释一下 第一位数字有两个 1 或者 3 所以编码后是二维的
第二位数字有 三个 2,4,5 所以是三维的
第三位数字有两个 3,6 所以是二维的
