Pytorch迁移学习之猫狗分类
1.AttributeError: ‘VGG’ object has no attribute 'fc’错误
解决:fc换成classifier[6],并且带【索引】,索引值可以直接打印模型看到结构层
model= models.vgg16(pretrained=True) for param in model.parameters(): #params have requires_grad=True by default param.requires_grad = False num_ftrs = model.fc.in_features
2.element 0 of tensors does not require grad and does not have a grad_fn 错误
解决:这是数据出现错误,需要设置批数据的requires_grad值 data=Variable(data,requires_grad=True),标签值y则不用
for i,(data,y) in enumerate(train_loader):
data=Variable(data,requires_grad=True)
# y=Variable(y,requires_grad=True)
print(data.requires_grad)
数据结构,
3.vgg模型代码
import torch.nn.functional as F
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
data_transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
train_dataset = datasets.ImageFolder(root=r'C:\Users\Lavector\Desktop\项目\分类', transform=data_transform)
test_dataset = datasets.ImageFolder(root=r'C:\Users\Lavector\Desktop\项目\分类test', transform=data_transform)
train_loader = torch.utils.data.DataLoader(train_dataset , batch_size=8, shuffle=True,num_workers=1)
test_loader = torch.utils.data.DataLoader(test_dataset , batch_size=3,shuffle=False,num_workers=1)
model= models.vgg16(pretrained=True)
for param in model.parameters(): #params have requires_grad=True by default
param.requires_grad = False
# num_ftrs = model.fc.in_features
num_ftrs = model.classifier[6].in_features
model.classifier[6] = nn.Linear(num_ftrs, 2)
print(model)
print(num_ftrs)
cost = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=0.001)
if __name__ == '__main__':
model.train(True)
for epoch in range(10):
print("===epoc===%d"%epoch)
for i,(data,y) in enumerate(train_loader):
data=Variable(data,requires_grad=True)
# y=Variable(y,requires_grad=True)
print(data.requires_grad)
out=model(data)
print(out)
loss=cost(out,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('loss:',loss,loss.item())
model.train(False)
# yy=net.test_modle(data)
# print(yy)
testacc = 0
for datas in test_loader:
images, labels = datas
images = Variable(images)
# labels = Variable(labels)
# print(net.test_modle(images))
torch.no_grad()
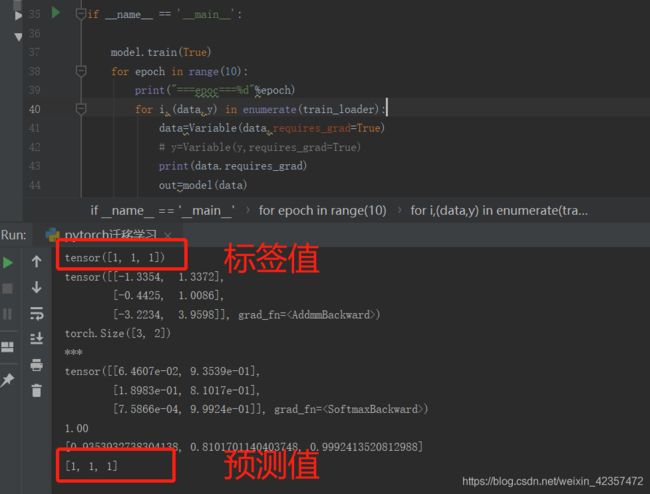
print(labels)
outputs=model(images)
print(outputs)
print(outputs.size())
print('***')
predict = F.softmax(outputs)
print(predict)
print("%.2f" % torch.max(predict).item())
print(torch.max(predict, 1)[0].data.numpy().tolist()) ##返回每行中最大的数,并返回其索引值
print(torch.max(predict, 1)[1].data.numpy().tolist())
4.resnet模型代码
import torch.nn.functional as F
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
data_transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
train_dataset = datasets.ImageFolder(root=r'C:\Users\Lavector\Desktop\项目\分类', transform=data_transform)
test_dataset = datasets.ImageFolder(root=r'C:\Users\Lavector\Desktop\项目\分类test', transform=data_transform)
train_loader = torch.utils.data.DataLoader(train_dataset , batch_size=8, shuffle=True,num_workers=1)
test_loader = torch.utils.data.DataLoader(test_dataset , batch_size=3,shuffle=False,num_workers=1)
model= models.resnet34(pretrained=True)
print(model)
# model= models.vgg16(pretrained=True)
for param in model.parameters(): #params have requires_grad=True by default
param.requires_grad = False
# num_ftrs = model.fc.in_features
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 2)
# num_ftrs = model.classifier[6].in_features
# model.classifier[6] = nn.Linear(num_ftrs, 2)
print(model)
print(num_ftrs)
cost = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=0.001)
if __name__ == '__main__':
model.train(True)
for epoch in range(10):
print("===epoc===%d"%epoch)
for i,(data,y) in enumerate(train_loader):
data=Variable(data,requires_grad=True)
# y=Variable(y,requires_grad=True)
print(data.requires_grad)
out=model(data)
print(out)
loss=cost(out,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('loss:',loss,loss.item())
model.train(False)
# yy=net.test_modle(data)
# print(yy)
testacc = 0
for datas in test_loader:
images, labels = datas
images = Variable(images)
# labels = Variable(labels)
# print(net.test_modle(images))
model.eval()
with torch.no_grad():
print(labels)
outputs=model(images)
print(outputs)
print(outputs.size())
print('***')
predict = F.softmax(outputs)
print(predict)
print("%.2f" % torch.max(predict).item())
print(torch.max(predict, 1)[0].data.numpy().tolist()) ##返回每行中最大的数,并返回其索引值
print(torch.max(predict, 1)[1].data.numpy().tolist())
# mm, prediction = torch.max(outputs.data, 1)
# print(outputs)
# print(mm)
# print(prediction)
# print(labels)
# print(labels.data)
#
# testacc += torch.sum(prediction == labels.data)
# print(testacc)
# print(testacc)