NLP-Lecture 4 Part-Of-Speech Tagging
NLP-Lecture 4 Part-Of-Speech Tagging
- Learning Objective
- Part-of-Speech Tagging
- Introduction to Part-Of-Speech (POS) Tagging
- POS Tag Sets
- On-Line Part-of-Speech (POS) Tagging Demos
- POS Tagging Approach
- Rule-based
- Statistic-based
- Neural-Network-based
- Statistical-based Tagging
- POS Bi-Gram Model
- Hidden Markov Model (HMM)
- Unknown Words
- Maximum Entropy Markov Model (MEMM)
- References
Learning Objective
- Part-of-Speech Tags
- Part-of-Speech Tagging
-
- Simple Statistic Models
-
- Sequence Labeling Models: Hidden Markov Model (HMM)
-
- Maximum Entropy Markov Model (MEMM)
-
- Conditional Random Fields (CRF)
Part-of-Speech Tagging
Introduction to Part-Of-Speech (POS) Tagging
- Part-of-Speech (for short POS) is the name for a group words, which have similar grammatical functions, such as noun, verb, pronoun, proposition, adverb, conjunction, participle and article.
-
- They are also known as syntactic classes(句法类别序列).
- A semantic class associates to the general meaning, such as human, animal and plant.
- Part-of-Speech tagging is a task of assigning a part-of-speech tag (like noun, verb, adjectives) to each word in a sentence. In such labelings, parts of speech are generally represented by placing the tag after each word, delimited by a slash.

-
Part-of-speech tagging is the process of assigning a part-of-speech marker to each word in an input text.3
The input to a tagging algorithm is a sequence of (tokenized) words and a tagset, and the output is a sequence of tags, one per token. -
Tagging is a disambiguation task; words are ambiguous—have more than one possible part-of-speech—and the goal is to find the correct tag for the situation. The goal of POS-tagging is to resolve these resolution ambiguities, choosing the proper tag for the context.
-
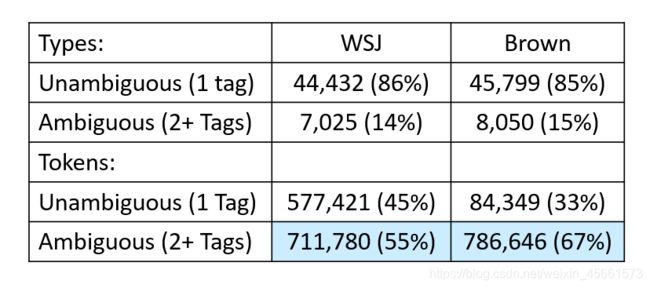
How common is tag ambiguity? Fig. 8.2 shows that most word types (85-86%) are unambiguous (Janet is always NNP, funniest JJS, and hesitantly RB). But the ambiguous words, though accounting for only 14-15% of the vocabulary, are very common words, and hence 55-67% of word tokens in running text are ambiguous. Some of the most ambiguous frequent words are that, back, down, put and set; here are some examples of the 6 different parts of speech for the word back:

-
POS Tagging is a disambiguation task, i.e., finding the correct tag for the word according to the context.
POS Tag Sets
-
Penn Treebank Tag Set
NLTK uses Penn Treebank Tagset -
UCREL CLAW Tag Sets
-
ICE Tag Set
On-Line Part-of-Speech (POS) Tagging Demos
- Cognitive Computation Group
- Infogistics
- Stanford Parser
POS Tagging Approach
Rule-based
Statistic-based
- It calculates how likely each tag is to be assigned to a word (i.e., the probability for assigning each candidate tag to a word).
Neural-Network-based
Recurrent Neural Network (LSTM, GRU[Gated Recurrent Unit])
Statistical-based Tagging
- Probabilities are learned from the POS-tagged texts (the training corpus).
- Most-Frequent-Class Model (Baseline)
-
- It chooses the tag which is most frequent in the training corpus.

- It chooses the tag which is most frequent in the training corpus.
-
- How good is this baseline?
The most-frequent-tag baseline achieves an accuracy of 92.34%. The state of the art in POS tagging is around 97% accuracy, a performance that is achievable by most algorithms (HMMs, MEMMs, neural networks).
- How good is this baseline?
A simplistic baseline algorithm for part-of-speech tagging: given an ambiguous word, choose the tag which is most frequent in the training corpus.
How good is this baseline?
If we train on the WSJ training corpus and test on sections 22-24 of the same corpus the most-frequent-tag baseline achieves an accuracy of 92.34%. By contrast, the state of the art in part-of-speech tagging on this dataset is around 97% tag accuracy, a performance that is achievable by most algorithms (HMMs, MEMMs, neural networks, rule-based algorithms).

POS Bi-Gram Model


Hidden Markov Model (HMM)

- HMM is a probabilistic sequence model.
- It computes a probability distribution over possible sequences of labels and chooses the best label sequence.
The HMM is a sequence model. A sequence model or sequence classifier is a model whose job is to assign a label or class to each unit in a sequence,
Thus mapping a sequence of observations to a sequence of labels. An HMM is a probabilistic sequence model: given a sequence of units (words, letters, morphemes, sentences, whatever), it computes a probability distribution over possible sequences of labels and chooses the best label sequence.
 A Markov chain is a model that tells us something about the probabilities of sequences of random variables, states, each of which can take on values from some set. These sets can be words, or tags, or symbols representing anything, for example the weather. A Markov chain makes a very strong assumption that if we want to predict the future in the sequence, all that matters is the current state. All the states before the current state have no impact on the future except via the current state. It’s as if to predict tomorrow’s weather you could examine today’s weather but you weren’t allowed to look at yesterday’s weather.
A Markov chain is a model that tells us something about the probabilities of sequences of random variables, states, each of which can take on values from some set. These sets can be words, or tags, or symbols representing anything, for example the weather. A Markov chain makes a very strong assumption that if we want to predict the future in the sequence, all that matters is the current state. All the states before the current state have no impact on the future except via the current state. It’s as if to predict tomorrow’s weather you could examine today’s weather but you weren’t allowed to look at yesterday’s weather.
- Markov Chain

- First-Order Markov Assumption
 P(hot hot hot hot) = 0.1 * 0.6^3
P(hot hot hot hot) = 0.1 * 0.6^3
P(cold hot cold hot) =0.7 * 0.1 * 0.1 * 0.1
- The states are hidden (not observable).
- For example, the words are observable but the part-of-speech tags are hidden.

A Markov chain is useful when we need to compute a probability for a sequence of observable events. In many cases, however, the events we are interested in are hidden: we don’t observe them directly. For example we don’t normally observe part-of-speech tags in a text. Rather, we see words, and must infer the tags from the word sequence.
A hidden Markov model (HMM) allows us to talk about both observed events (like words that we see in the input) and hidden events (like part-of-speech tags) that we think of as causal factors in our probabilistic model.




 For any model, such as an HMM, that contains hidden variables, the task of determining the hidden variables sequence corresponding to the sequence of observations is called decoding.
For any model, such as an HMM, that contains hidden variables, the task of determining the hidden variables sequence corresponding to the sequence of observations is called decoding.
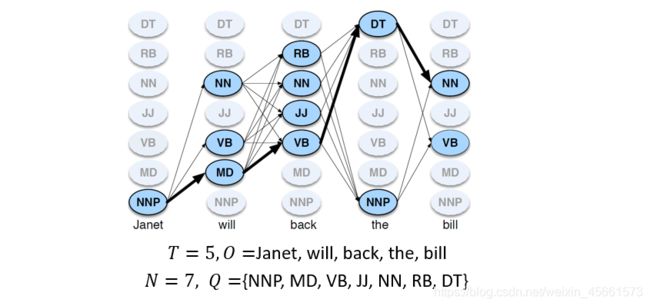
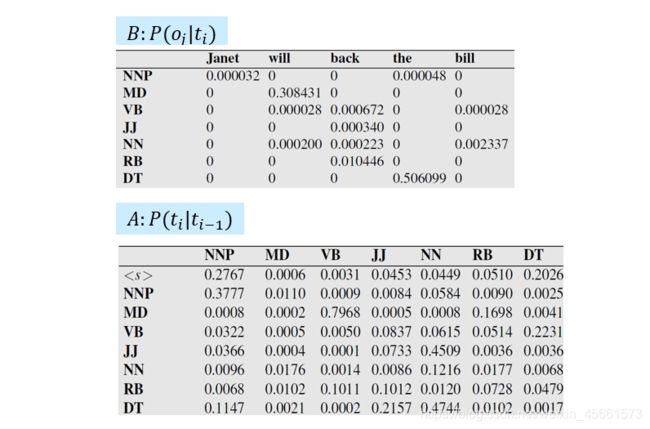
HMM taggers make two further simplifying assumptions.
- Assumption 1: The probability of a word appearing depends only on its own tag and is independent of neighboring words and tags.

- Assumption 2: the bigram assumption, The probability of a tag is dependent only on the previous tag, rather than the entire tag sequence.



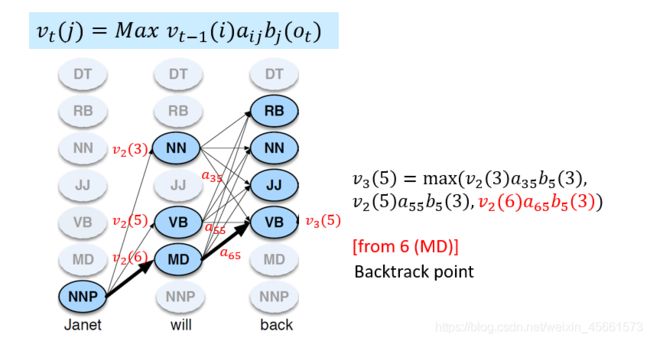

Unknown Words
- Using Suffix(后缀) to Guess

One useful feature for distinguishing parts of speech is word shape: words starting with capital letters are likely to be proper nouns (NNP).
But the strongest source of information for guessing the part-of-speech of unknown words is morphology.
Words that end in -s are likely to be plural nouns (NNS), words ending with -ed tend to be past participles (VBN), words ending with -able adjectives (JJ), and so on.
We store for each final letter sequence (for simplicity referred to as word suffixes) of up to 10 letters the statistics of the tag it was associated with in training. We are thus computing for each suffix of length i the probability of the tag ti given the suffix letters.
Maximum Entropy Markov Model (MEMM)
- MEMM (LR+HMM)
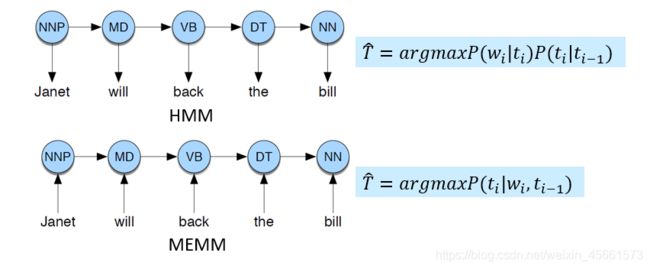
It would be so much easier if we could add arbitrary features directly into the model in a clean way, but that’s hard for generative models like HMMs. Luckily, we’ve already seen a model for doing this: the logistic regression model of Chapter 5! But logistic regression isn’t a sequence model; it assigns a class to a single observation. However, we could turn logistic regression into a discriminative sequence model simply by running it on successive words, using the class assigned to the prior word as a feature in the classification of the next word. When we apply logistic regression MEMM in this way, it’s called the maximum entropy Markov model or MEMM. - Features

- Features for Unknown Words

References
- Speech and Language Processing Chapter 8: Part-of-Speech Tagging