目录
- 前言
- Dispatcher类的属性
- endpoints、endpointRefs
- receivers
- threadpool
- EndpointData
- Dispatcher的调度逻辑
- MessageLoop的实现
- Inbox消息处理
- 向Inbox投递消息
- 停止Dispatcher
- 总结
前言
前一段时间忙于发版,不太顾得上这个系列,今天忙里偷一点闲,继续写。
上一篇文章以NettyRpcEnv的概况结尾,对它内部的一些重要组件进行了简要的介绍。比起继续向下深挖,个人感觉现在平行地来搞比较合适,毕竟我们已经来到了相当底层的地方不是么?
本文着重介绍NettyRpcEnv中调度器Dispatcher的具体实现,它负责将消息正确地路由给要处理它的RPC端点。
Dispatcher类的属性
Dispatcher类内的属性不多,但是都比较重要,有必要看一看。
代码#9.1 - o.a.s.rpc.netty.Dispatcher类的属性成员
private val endpoints: ConcurrentMap[String, EndpointData] =
new ConcurrentHashMap[String, EndpointData]
private val endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef] =
new ConcurrentHashMap[RpcEndpoint, RpcEndpointRef]
private val receivers = new LinkedBlockingQueue[EndpointData]
private val threadpool: ThreadPoolExecutor = {
val availableCores =
if (numUsableCores > 0) numUsableCores else Runtime.getRuntime.availableProcessors()
val numThreads = nettyEnv.conf.getInt("spark.rpc.netty.dispatcher.numThreads",
math.max(2, availableCores))
val pool = ThreadUtils.newDaemonFixedThreadPool(numThreads, "dispatcher-event-loop")
for (i <- 0 until numThreads) {
pool.execute(new MessageLoop)
}
pool
}
endpoints、endpointRefs
这两个ConcurrentHashMap分别用来维护RPC端点名称与端点数据EndpointData的映射,以及RPC端点与其引用的映射。
receivers
存储RPC端点数据的阻塞队列,只有当RPC端点收到要处理的消息时,才会被放进这个阻塞队列,空闲的RPC端点不会进去。
threadpool
一个用来调度消息的固定大小的守护线程池。该线程池内的线程数由spark.rpc.netty.dispatcher.numThreads配置项决定,默认值为1或2(取决于服务器是否只有一个可用的核心)。这个线程池内跑的线程都是MessageLoop类型的。
EndpointData
EndpointData是Dispatcher中的私有内部类,其实现也很简单。
代码#9.2 - o.a.s.rpc.netty.Dispatcher.EndpointData类
private class EndpointData(
val name: String,
val endpoint: RpcEndpoint,
val ref: NettyRpcEndpointRef) {
val inbox = new Inbox(ref, endpoint)
}
它接受三个参数:RPC端点名称、RPC端点实例及其引用,然后创建出一个Inbox对象的实例。什么是Inbox?可以理解为“收件箱”,每个RPC端点都有一个对应的收件箱,里面采用链表维护着它收到并且要处理的消息,这些消息都继承自InboxMessage特征。
Dispatcher的调度逻辑
MessageLoop的实现
上面已经讲到说Dispatcher的线程池执行的都是MessageLoop,它也是一个内部类,来看它的代码。
代码#9.3 - o.a.s.rpc.netty.Dispatcher.MessageLoop类
private class MessageLoop extends Runnable {
override def run(): Unit = {
try {
while (true) {
try {
val data = receivers.take()
if (data == PoisonPill) {
receivers.offer(PoisonPill)
return
}
data.inbox.process(Dispatcher.this)
} catch {
case NonFatal(e) => logError(e.getMessage, e)
}
}
} catch {
case ie: InterruptedException =>
}
}
}
private val PoisonPill = new EndpointData(null, null, null)
可见MessageLoop本质上是一个不断循环处理消息的线程。它每次从receivers队列中取出EndpointData,然后调用Inbox.process()方法,处理该RPC端点收件箱中的消息。如果receivers队列为空的话,其take()方法就会阻塞住,等待该队列有新的EndpointData进入。
队列中有一种特殊的端点信息PoisonPill,即“毒药丸”,在文章#6讲AsyncEventQueue时(代码#6.2),有类似的用法。如果当前线程取到了PoisonPill,就会“中毒”退出循环。但是在线程吃掉PoisonPill之前,还会把它重新放回队列,以使其他还活着的线程也都“中毒”。
Inbox消息处理
下面来看Inbox.process()方法的细节。
代码#9.4 - o.a.s.rpc.netty.Inbox.process()方法
@GuardedBy("this")
protected val messages = new java.util.LinkedList[InboxMessage]()
def process(dispatcher: Dispatcher): Unit = {
var message: InboxMessage = null
inbox.synchronized {
if (!enableConcurrent && numActiveThreads != 0) {
return
}
message = messages.poll()
if (message != null) {
numActiveThreads += 1
} else {
return
}
}
while (true) {
safelyCall(endpoint) {
message match {
case RpcMessage(_sender, content, context) =>
try {
endpoint.receiveAndReply(context).applyOrElse[Any, Unit](content, { msg =>
throw new SparkException(s"Unsupported message $message from ${_sender}")
})
} catch {
case NonFatal(e) =>
context.sendFailure(e)
throw e
}
case OneWayMessage(_sender, content) =>
endpoint.receive.applyOrElse[Any, Unit](content, { msg =>
throw new SparkException(s"Unsupported message $message from ${_sender}")
})
case OnStart =>
endpoint.onStart()
if (!endpoint.isInstanceOf[ThreadSafeRpcEndpoint]) {
inbox.synchronized {
if (!stopped) {
enableConcurrent = true
}
}
}
case OnStop =>
val activeThreads = inbox.synchronized {
inbox.numActiveThreads
}
assert(activeThreads == 1,
s"There should be only a single active thread but found $activeThreads threads.")
dispatcher.removeRpcEndpointRef(endpoint)
endpoint.onStop()
assert(isEmpty, "OnStop should be the last message")
case RemoteProcessConnected(remoteAddress) =>
endpoint.onConnected(remoteAddress)
case RemoteProcessDisconnected(remoteAddress) =>
endpoint.onDisconnected(remoteAddress)
case RemoteProcessConnectionError(cause, remoteAddress) =>
endpoint.onNetworkError(cause, remoteAddress)
}
}
inbox.synchronized {
if (!enableConcurrent && numActiveThreads != 1) {
numActiveThreads -= 1
return
}
message = messages.poll()
if (message == null) {
numActiveThreads -= 1
return
}
}
}
}
Inbox的enableConcurrent属性控制是否允许多个线程同时处理收件箱中的消息。如果不允许,且当前活动的线程数不为0,那么当前线程就不应该再继续处理,直接返回。接下来从messages链表中取得消息,增加活动线程数。然后对消息进行模式匹配,根据不同的类型调用RpcEndpoint中对应的方法来处理。如果匹配不到,就通过safelyCall()方法进而调用RpcEndpoint.onError()处理错误。
值得注意的是,代码#9.4中(以及Inbox类的很多其他方法中)多次出现了synchronize代码块,这是因为messages本身只是一个普通链表,是线程不安全的,因此对它的操作都要加锁。
Inbox中的消息定义如下所示,InboxMessage本身就是个标记接口。
代码#9.5 - o.a.s.rpc.netty.InboxMessage特征及其子类的定义
private[netty] sealed trait InboxMessage
private[netty] case class OneWayMessage(
senderAddress: RpcAddress,
content: Any) extends InboxMessage
private[netty] case class RpcMessage(
senderAddress: RpcAddress,
content: Any,
context: NettyRpcCallContext) extends InboxMessage
private[netty] case object OnStart extends InboxMessage
private[netty] case object OnStop extends InboxMessage
private[netty] case class RemoteProcessConnected(remoteAddress: RpcAddress) extends InboxMessage
private[netty] case class RemoteProcessDisconnected(remoteAddress: RpcAddress) extends InboxMessage
private[netty] case class RemoteProcessConnectionError(cause: Throwable, remoteAddress: RpcAddress) extends InboxMessage
向Inbox投递消息
前面已经大致讲清楚了Inbox中的消息是如何处理的,但还没提这些消息到底是怎么来的。我们可以通过receivers.offer()方法的调用来寻找InboxMessage的来源。在Dispatcher.registerRpcEndpoint()方法中就有调用,其代码如下。
代码#9.6 - o.a.s.rpc.netty.Dispatcher.registerRpcEndpoint()方法
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = {
val addr = RpcEndpointAddress(nettyEnv.address, name)
val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv)
synchronized {
if (stopped) {
throw new IllegalStateException("RpcEnv has been stopped")
}
if (endpoints.putIfAbsent(name, new EndpointData(name, endpoint, endpointRef)) != null) {
throw new IllegalArgumentException(s"There is already an RpcEndpoint called $name")
}
val data = endpoints.get(name)
endpointRefs.put(data.endpoint, data.ref)
receivers.offer(data)
}
endpointRef
}
该方法向Dispatcher注册RPC端点,生成EndpointData并将其放入阻塞队列,最后返回RPC端点的引用。但是这并不能看出哪里投递了消息,答案藏在Inbox的主构造方法中,非常简单。
代码#9.7 - Inbox构造方法中投递OnStart消息
inbox.synchronized {
messages.add(OnStart)
}
由于new EndpointData时会同时构建Inbox,所以会自动投递OnStart消息,让RpcEndpoint做一些准备工作。同理,在与这个方法相反的unregisterRpcEndpoint()方法中,会先反注册RPC端点,然后调用Inbox.stop()方法投递OnStop消息,在停止前清理一些东西,看官可以自行去翻代码,这里就不赘述了。
另外,在Dispatcher.postMessage()方法中也有向Inbox投递消息的逻辑。
代码#9.8 - o.a.s.rpc.netty.Dispatcher.postMessage()方法
private def postMessage(
endpointName: String,
message: InboxMessage,
callbackIfStopped: (Exception) => Unit): Unit = {
val error = synchronized {
val data = endpoints.get(endpointName)
if (stopped) {
Some(new RpcEnvStoppedException())
} else if (data == null) {
Some(new SparkException(s"Could not find $endpointName."))
} else {
data.inbox.post(message)
receivers.offer(data)
None
}
}
error.foreach(callbackIfStopped)
}
该方法先根据RPC端点的名称,在代码#9.1的endpoints映射中取得对应的EndpointData。如果存在的话,就调用Inbox.post()方法将消息加入收件箱中,并将该EndpointData加入阻塞队列,让MessageLoop来处理。
Dispatcher类中还有一些方法复用了postMessage()方法来发送特定类型的消息,比如postOneWayMessage()用来发送OneWayMessage,postLocalMessage()/postRemoteMessage()用来发送RpcMessage,等等。
停止Dispatcher
代码#9.9 - o.a.s.rpc.netty.Dispatcher.stop()方法
def stop(): Unit = {
synchronized {
if (stopped) {
return
}
stopped = true
}
endpoints.keySet().asScala.foreach(unregisterRpcEndpoint)
receivers.offer(PoisonPill)
threadpool.shutdown()
}
调度器的停止是通过调用stop()方法来实现的。首先它会将状态改为已经停止,然后遍历endpoints映射,对其中的每个RpcEndpoint进行反注册。最后向receivers阻塞队列里放“毒药丸”PoisonPill,杀掉线程池中的所有线程,并关闭线程池。
总结
本文从Dispatcher类入手,首先介绍了其内部的属性,进而引申出Spark RPC环境内消息调度的逻辑。而Dispatcher内涉及到的主要是消息接收与处理的机制,NettyRpcEnv作为一个成熟的RPC环境,必然也需要向远端的RpcEndpoint发送请求。下一篇文章就来探讨NettyRpcEnv作为客户端的能力。
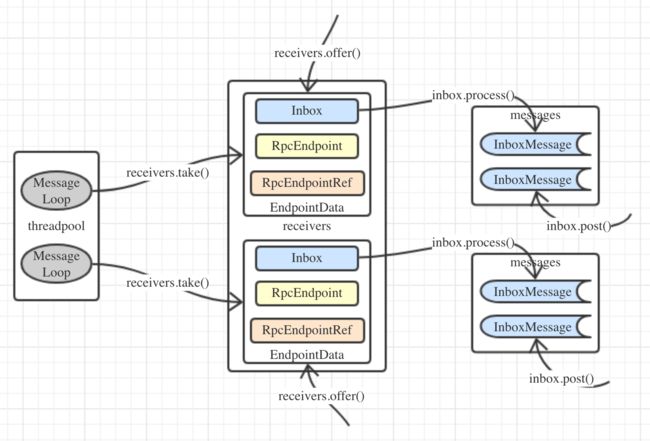
最后应该要画一张图来演示Dispatcher的运作流程的,但是马上还要去忙工作的事情,这张图就等周日休息时补上吧。祝周末快乐哦。
Update:已经画好了的说~