Spark HA集群的分布式安装
Spark安装部署
对文档不理解的,想了解更多精彩的,请看对应视频地址:https://edu.csdn.net/course/detail/27028
前置:
已经安装jdk1.8,zookeeper,hadoop
1、Spark的安装与部署
Spark的安装部署方式有以下几种模式
- Standalone
- YARN
- Mesos
- Amazon EC2
Spark Standalone伪分布的部署
1) 配置文件:conf/spark-env.sh
export JAVA_HOME=/export/server/jdk1.8
export SPARK_MASTER_HOST=192.168.1.141
export SPARK_MASTER_PORT=7077
下面的可以不写,默认为机器所有资源:
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1024m
2) 配置文件:conf/slave
192.168.1.141
Spark Standalone全分布的部署
配置文件:conf/spark-env.sh
export JAVA_HOME=/export/server/jdk1.8
export SPARK_MASTER_HOST=192.168.1.141
export SPARK_MASTER_PORT=7077
配置文件:conf/slave
parktest141
sparktest145
拷贝:
[root@sparktest141 server]# scp -r ./spark2.1/ [email protected]:/export/server/
运行实例:
运行:
[root@sparktest141 bin]# pwd
/export/server/spark2.1/bin
[root@sparktest141 bin]# ./spark-shell --master spark://sparktest141:7077 --executor-memory 2g --total-executor-cores 2
启动Spark集群:start-all.sh
2、Spark HA的实现
(1)基于文件系统的单点恢复
主要用于开发或测试环境。基于文件系统的单点恢复,主要是在spark-en.sh里对SPARK_DAEMON_JAVA_OPTS设置
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/export/server/spark/hadata" 测试: 1、在sparktest141上启动Spark集群 2、在sparktest145上启动spark shell MASTER=spark://sparktest141:7077 spark-shell 3、在sparktest141上停止master stop-master.sh 4、观察sparktest145上的输出 5、在sparkatest141上重启master start-master.sh
(2)基于Zookeeper的Standby Masters
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=sparktest141:2181, sparktest145:2181, sparktest146:2181 -Dspark.deploy.zookeeper.dir=/spark"
另外:每个节点上,需要将以下两行注释掉。
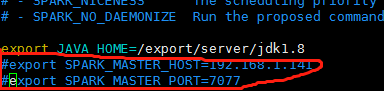
ZooKeeper中保存的信息
ls /spark
实践实例—Standalone模式:
1.sparktest141中/export/server/spark/conf/spark-env.sh修改
export JAVA_HOME=/export/server/jdk1.8
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=sparktest141:2181,sparktest145:2181,sparktest146:2181 -Dspark.deploy.zookeeper.dir=/spark"
2、拷贝到其他机器
[root@sparktest141 conf]# pwd
/export/server/spark/conf
[root@sparktest141 conf]# scp -r ./spark-env.sh root@sparktest145:/export/server/spark/conf/
spark-env.sh 100% 4020 3.9KB/s 00:00
[root@sparktest141 conf]# scp -r ./spark-env.sh root@sparktest146:/export/server/spark/conf/
spark-env.sh
100% 4020 3.9KB/s 00:00
3、启动激活Master
[root@sparktest141 sbin]# pwd
/export/server/spark/sbin
[root@sparktest141 sbin]# ./start-all.sh
4、启动备用Master
[root@sparktest145 sbin]# pwd
/export/server/spark/sbin
[root@sparktest145 sbin]# ./start-master.sh
5、查看
激活节点:http://192.168.1.141:8080/

备用节点:http://192.168.1.145:8080/
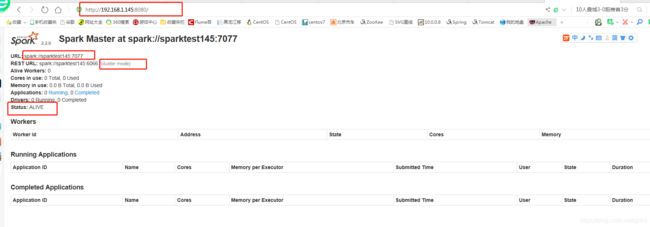
6、启动一个任务
[root@sparktest141 bin]# pwd
/export/server/spark/bin
[root@sparktest141 bin]# ./spark-shell --master spark://sparktest141:7077 --executor-memory 2g --total-executor-cores 2
实践实例2—YARN模式
1、在spark-env.sh中配置:
export JAVA_HOME=/export/server/jdk1.8
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
#export SPARK_WORKER_MEMORY=3072m
#export SPARK_WORKER_CORES=3
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=sparktest141:2181,sparktest145:2181,sparktest146:2181 -Dspark.deploy.zookeeper.dir=/spark"
2、执行一个任务:
[root@sparktest146 bin]# ./spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://192.168.1.141:7077 \
--executor-memory 1000m \
--total-executor-cores 1 \
/export/server/spark2.1/examples/jars/spark-examples_2.11-2.1.0.jar \
100
3、Standalone模式与YARN模式的优缺点
Standalone:独立管理资源,只要安装了sparkt程序,马上可以加入到资源; 但是spark管理资的调度器不如YARN的好。
YARN:YARN专门的调度器,管理资源更合理,但是必须安装Hadoop
4、添加新的节点
[root@sparktest146 sbin]# pwd
/export/server/spark2.1/sbin
[root@sparktest146 sbin]# ./start-slave.sh spark://sparktest141:7077
QQ: 271780243