【架构设计】——k8s云平台上分布式应用架构浅谈
一、前言
这篇文章我其实写了很久,有小半年时间。迟迟没发,也是犹豫了很久,都不知道怎么取名,因为内容有点形而上的感觉,没贴出具体实现代码,所以干脆大言不惭的说这是架构设计吧。
二、系统架构
在基于k8s的云平台上我们要设计一套完整的业务系统,一般都可以分成四个模块:无状态服务管理子系统、有状态服务管理子系统、调度子系统和持久化子系统四个模块,系统总体框架图如图1所示:
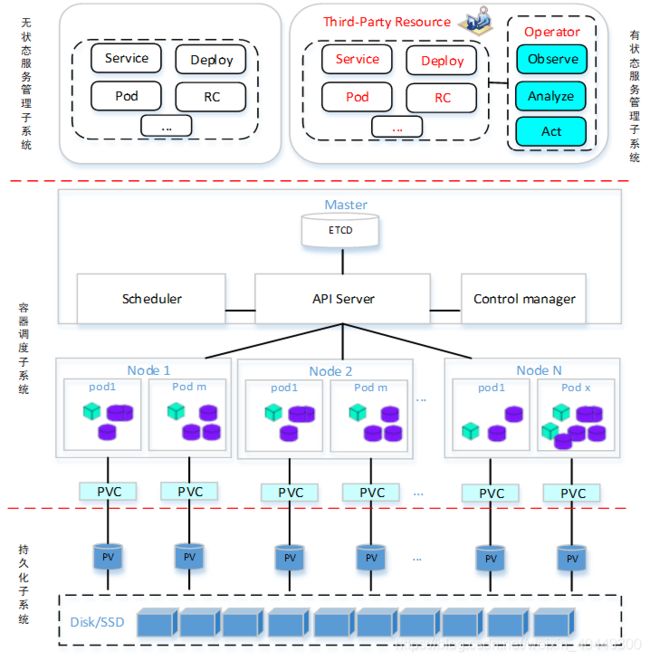
图 1 系统总体框架简图
1. 模块一:无状态服务管理子系统
这部分具体结合业务需求定制。通过 Kubernets 中的无状态服务管理资源Deployment和ReplicationController 控制器可以方便地在部署了kubernetes 的集群中部署一套高可用、可扩展的分布式无状态服务,供上层调度框架使用。无状态服务创建、扩容、缩容和故障恢复均由系统自动实现,用户只需要通过声明式方式编写yaml文件来告知系统所期望的运行状态。
2. 模块二:有状态服务管理子系统
有状态应用和无状态应用最大的不同便是数据存储部分,数据存储部分交给数据库去执行,因为数据库应用的复杂性,Kubernets本身并不支持对数据库这类应用的管理。因此,我们基于Kubernets的API设计开发了一个Operator控制器。该Operator控制器本身以无状态应用的方式部署在集群中,作为守护应用,该 Operator控制器 会持续监听针对特定资源对象的增删改查等操作,并观察该监控对象的状态。
当用户执行了某项操作,例如用户通过声明式yaml文件以键值对的方式指定创建一个redis集群时,一个新的 redisCluster 资源对象会被创建。当 operator 控制器监听到了redisCluster 的创建事件后,会根据用户配置创建符合需求的集群。当 Operator 观察到 redisCluster 的当前状态与期望状态存在差别时,会执行相应的编排操作,保证状态的一致性。
Operator 控制器的工作流程可抽象成以下三个步骤:
- Observe (观察)——operator在集群内部运行,通过无限循环的心跳检测、就绪检测或者存活检测等手段观察目标对象的状态;
- Analyze (分析)——operator分析比对当前状态与期望状态的差别;
- Act(执行)——当当前状态与期望状态不符合时,operator执行调度编排操作,将当前状态调整为期望状态。
3. 模块三:容器调度子系统
该模块采用Kubernets系统的调度模式,用户通过Kubernets API与系统主节点进行交互,把用户自定义的资源清单传入主节点。主节点接收到用户定义的资源清单后解析资源清单的键值对并验证清单的合法性,再交由Kubernets 的API server组件传递到对应子节点的kubelete上,由对应的子节点负责创建资源供集群使用,同时子节点将创建结果返回给主节点,主节点对该服务进行监控。当集群服务状态与用户传入资源清单不一致时,主节点会调整服务状态保证系统的高可用性。
4. 模块四:持久化存储子系统
Kubernets中Deployment资源和ReplicationController 控制器是为无状态服务而设计的,它们中 pod 的名称、主机名、存储等都是不稳定的,随着pod的创建而创建,销毁而销毁。并且 pod 的启动、销毁顺序随机,并不适合数据库这样的有状态应用。对于云平台上的分布式数据管理系统,除了大量的计算资源可抽象为无状态服务在集群中运行以外,更多的部分是像数据库这样的有状态服务。为了解决有状态服务的高可用性问题,Kubernets通过关联存储设备并把存储设备资源化,让用户像调用其他资源一样声明并使用存储设备,以此来保证数据的不丢失。
三、无状态服务子系统
1、原理
Kubernetes 通过各种控制器来管理 Pod 的生命周期。为了满足不同业务场景,Kubernetes 开发了 Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job 等多种 控制器。Deployment 经常会用来创建 ReplicaSet 和 Pod, 因为ReplicaSet 部署一个新的微服务一些常见的更新、扩容和缩容运维操作都不支持,Deployment 的引入就是为了就是为了支持这些复杂的操作。我们采用声明式API来部署无状态服务,Kubernetes 项目最具价值的理念,就是它围绕 etcd 构建出来的一套面向终态的编排体系——声明式 API。Kubernetes 通过启动一种叫做控制器模式(Controller Pattern)的无限循环对API对象进行监控,最后确保整个集群的状态与资源声明中的期望状态一致。控制器是依靠 etcd 的 Watch API 来实现对 API 对象变化的感知的。控制器模式(Controller Pattern)的无限循环逻辑如下:
for {
期望状态 := 获取Deployment资源声明中的期望状态(spec)
实际状态 := 获取集群中对象Y的实际状态(status)
while 实际状态 == 期望状态{
不执行任何操作
}else{
执行调度编排操作,确保实际状态和期望状态一致
}
}2、实现流程
无状态服务管理子系统是用于管理系统中的无状态应用的。在分布式数据管理系统中,常用的负载均衡器nginx或者web界面(不包含数据库)自身都是不需要保存数据的,对于 web 服务,数据会保存在专门做持久化的节点上。所以这些节点可以随意扩容或者缩容,只要简单的增加或减少副本的数量就可以。无状态服务管理子系统处理的是分布式数据管理系统的无状态服务,主要包括计算任务。比如Nginx 1.7.9。处理流程如图所示:
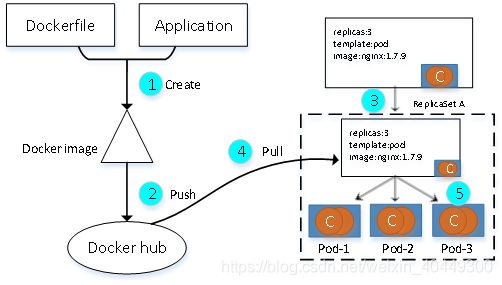
- 编写Dockerfile,将无状态服务所依赖的运行环境封装成docker镜像;
- 将第一步封装好的镜像推送到镜像仓库,可以是镜像仓库或者公有的。
- 编写deployment文件,采用声明式方式定义资源清单及期望集群保持的状态;
- 通过客户端以文件或者命令行的方式部署deployment资源清单到集群,Kubernetes集群自动监测资源清单,发现deployment资源清单中的创建需求后,工作节点会根据deployment资源清单中指定的镜像地址拉取所需镜像来创建集群实例;
- 部署完成deployment资源清单之后,deployment控制器定期检测部署的pod状态,当集群实际状态与资源清单中定义的状态不符合时,集群自动调整来保证集群符合deployment中所期望的状态。例如某个Pod实例由于某种原因故障了无法提供服务。Kubernetes中的RC控制器会立刻用这个Pod的templete模版新启一个Pod来替代它,新启的Pod与原来健康状态下的Pod一样。
四、有状态服务子系统
有状态服务区别于无状态服务状态的是它多了数据存储的需求。Kubernetes 1.7 版本以来就引入了自定义控制器的概念,该功能可以让开发人员扩展添加新功能,更新现有的功能,并且可以自动执行一些管理任务,这些自定义的控制器就像 Kubernetes 原生的组件一样,Operator 直接使用 Kubernetes API进行开发,也就是说他们可以根据这些控制器内部编写的自定义规则来监控集群、更改 Pods/Services、对正在运行的应用进行扩缩容。
1. operator控制器原理
Operator基于第三方资源扩展了新的应用资源,并通过控制器来保证应用处于预期状态。比如etcd operator通过下面的三个步骤模拟了管理etcd集群的行为:
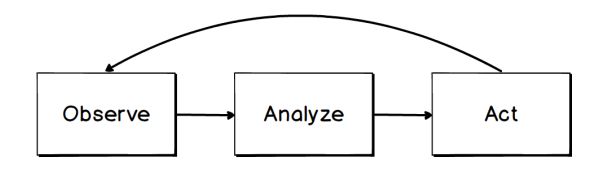
- 通过Kubernetes API观察集群的当前状态
- 分析当前状态与期望状态的差别
- 调用etcd集群管理API或Kubernetes API消除这些差别
Operator本质是通过在Kubenertes中部署对应的Third-Party Resource (TPR)插件,然后通过部署Third-Party Resource的方式来部署对应的应用。Third-Party Resource会调用Kubenertes部署API部署相应的Kubenertes资源,并对资源状态进行管理。
Operator资源控制器启动后会主动对创建的自定义资源清单进行监控。在实现上,Operator是在 Kubernetes 声明式 API 基础上的一种创新。在控制器中,需要提供一个无限的控制循环,用于管理系统状态。Kubernetes的系统状态通过API Server暴露。控制器的逻辑图如下:
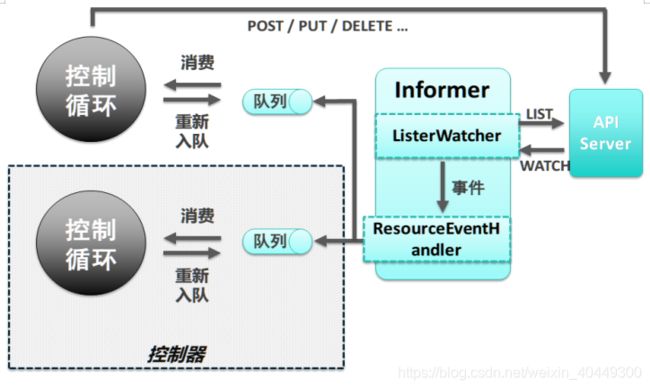
控制器主要使用以下client-go组件:
- Informer/SharedInformer:监控目标资源的变化,并交由ResourceEventHandler进行处理;
- ResourceEventHandler:将事件发送到工作队列;
- Workqueue :暂存资源变更事件,由控制循环取出事件并处理。
2、operator控制器实现方式
Operator是一个感知应用状态的控制器,所以实现一个Operator最关键的就是把管理应用状态的所有操作封装到配置资源和控制器中。通常来说Operator需要包括以下功能:
- Operator自身以deployment的方式部署
- Operator自动创建一个Third Party Resources资源类型,用户可以用该类型创建应用实例
- Operator应该利用Kubernetes内置的Serivce/ReplicaSet等管理应用
- Operator应该向后兼容,并且在Operator自身退出或删除时不影响应用的状态
- Operator应该支持应用版本更新
- Operator应该测试Pod失效、配置错误、网络错误等异常情况
五、容器调度子系统
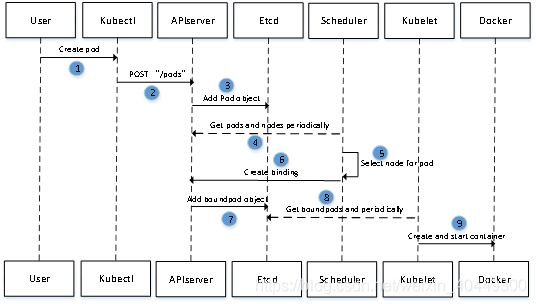
Scheduler调度器做为Kubernetes三大核心组件之一, 承载着整个集群资源的调度功能,其根据特定调度算法和策略,将Pod调度到最优工作节点上,从而更合理与充分的利用集群计算资源。集群的资源可以分为两种,一种是可压缩资源,比如CPU、I/O带宽等。另一种资源是不可压缩资源,例如硬盘、内存等。本文所述的系统采用的便是Kubernetes的Scheduler调度器。具体流程下图.
(1)首先用户通过 Kubernetes 客户端提交创建 Pod 的 声明式文件,准备向系统发起资源请求,这里的客户端可以是kubectl命令行、也可以是helm,或者是其他方式。
(2)步骤一中的资源请求被提交到Kubernetes 系统中,Kubernetes 集群接到请求后交由 API Server 组件。
(3)API Server 接收到请求后把创建 Pod 的信息存储到 Etcd 中,
(4)资源调度系统 Scheduler 就会定时去监控 APIServer组件,获取调度策略字段,如果用户未定义调度策略字段,调度器会采用默认的策略。
(5)资源调度系统Scheduler 根据第四步获取的调度策略执行选择节点的任务。
(6)第五步的调度器选择好节点后,交给APIServer组件进行节点绑定。
(7)APIServer组件和ETCD组件交互,存储节点调度的信息。
(8)kubelete作为从节点上负责和主节点交互的组件采用 watch 机制,一旦 Etcd 存储的调度信息和本节点相关则接受信息,开始从节点内的调度工作。
(9)第八步骤中kubelete获取到调度信息和本节点相关时,会交给本从节点进行管理,如果是镜像的更新或者容器的创建则会和从节点中部署的docker服务进行交互,以此来管理镜像。
六、持久化存储子系统
在系统中,大多数的Pod管理都是基于无状态、一次性的理念。如果一个Pod被认定为不健康的,Kubernetes就会删掉、重建这个pod。相比于无状态的服务,有状态服务是由一组有状态的Pod组成,每个Pod有自己特殊且不可改变的ID,且每个Pod中都有自己独一无二、不能删除的数据。有状态应用的管理是非常困难的。存在以下问题:
- 当一个容器损坏之后, kubelet会重启这个容器, 但是文件会丢失, 这个容器将是一个全新的状态
- 当很多容器运行在同一个pod中时, 很多时候需要数据文件的共享
- 在kubernets中,由于pod分布在各个不同的节点之上,并不能实现不同节点之间持久性数据的共享,并且,在节点故障时,可能会导致数据的永久性丢失。
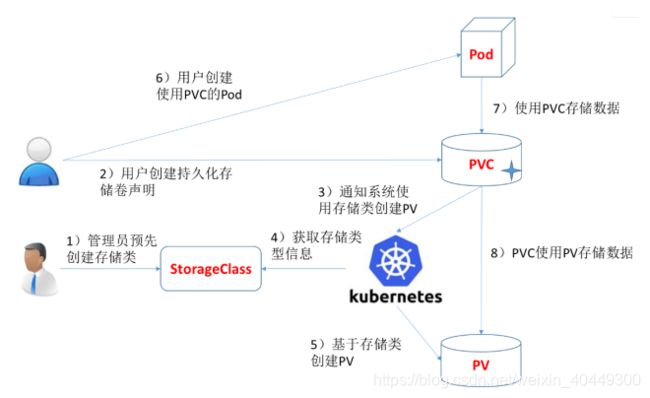
传统意义上,对有状态应用的管理一般思路都是:固定机器、固定IP、持久化存储等。本系统设计的持久化存储子系统利用了PersistentVolume(PV)和PersistentVolumeClaim(PVC)这两种Kubernetes资源。PV和PVC是Kubernetes提供的两种API资源,用于抽象存储细节,实现持久化存储。PV是由管理员设置的存储,它是群集的一部分。就像节点是集群中的资源一样,PV 也是集群中的资源。 PV 是 Volume 之类的卷插件,但具有独立于使用 PV 的 Pod 的生命周期。PersistentVolumeClaim(PVC)是用户存储的请求。
七、参考文献
- 刘福鑫,李劲巍,王熠弘,李琳.基于Kubernetes的云原生海量数据存储系统设计与实现[J/OL].计算机应用:1-7[2020-03-05]
- 姚增增. 大规模环境下容器技术的研究与优化[D].浙江大学,2019.
- 房向阳.基于Kubernetes的OpenStack控制节点高可用性解决方案的设计与实现[D].湖北:华中科技大学,2017. DOI:10.7666/d.D01542339.
- 辛园园,钮俊,谢志军,张开乐,毛昕怡.微服务体系结构实现框架综述[J].计算机工程与应用,2018,54(19):10-17.
- 李春霞.微服务架构研究概述[J].软件导刊,2019,18(08):1-3+7.
- 蒋勇.基于微服务架构的基础设施设计[J].软件,2016,37(05):93-97.
- Kubernetes[EB/OL]. 2018. https://kubernetes.io/zh/
- DockerSwarm[EB/OL], 2018. https://docs.docker.com/engine/Bwarm.
- 辛园园,钮俊,谢志军,张开乐,毛昕怡.微服务体系结构实现框架综述[J].计算机工程与应用,2018,54(19):10-17.
- 王绪国. 基于VT-x虚拟化的容器间资源硬隔离技术研究[D].兰州大学,2017.