转自 http://blog.csdn.net/jgwei/article/details/40819577
tomcat 下jsp乱码
我们先看一个例子(包含2个文件一个test.jsp , 和result.jsp):
test.jsp
- <%@ page language="java" isThreadSafe="true" pageEncoding="utf8" %>
- <%@ page contentType="text/html; charset=gbk"%>
- <html>
- <head>
- <title>title>
- <META HTTP-EQUIV="pragma" CONTENT="no-cache">
- <META HTTP-EQUIV="Cache-Control" CONTENT="no-cache, must-revalidate">
- <META HTTP-EQUIV="expires" CONTENT="Mon, 23 Jan 1978 20:52:30 GMT">
- head>
- <body>
- <form name="form1" action="result.jsp" method="get" target="">
- <INPUT TYPE="text" NAME="abc">
- <INPUT TYPE="submit" VALUE="submit">
- form>
- body>
- html>
result.jsp
- <%@ page language="java" isThreadSafe="true" pageEncoding="utf8" %>
- <%@ page contentType="text/html; charset=utf8"%>
- <html>
- <head>
- <title>title>
- <META HTTP-EQUIV="pragma" CONTENT="no-cache">
- <META HTTP-EQUIV="Cache-Control" CONTENT="no-cache, must-revalidate">
- <META HTTP-EQUIV="expires" CONTENT="Mon, 23 Jan 1978 20:52:30 GMT">
- head>
- <body>
- <%
- //request.setCharacterEncoding("utf8");
- String abc = request.getParameter("abc");
- if(abc == null) {
- out.println("空值");
- }
- else
- {
- out.println("原始编码:");
- out.println(abc);
- out.println("br>");
- out.println("utf8编码:");
- String abc1 = new String(abc.getBytes("ISO-8859-1"),"utf8");
- System.out.println(abc1);
- out.println(abc1);
- out.println("br>");
- out.println("gbk编码:");
- String abc2 = new String(abc.getBytes("ISO-8859-1"),"gbk");
- out.println(abc2);
- }
- %>
- br>
- br>
- br>
- <a href="test.jsp">返回a>
- body>
- html>
这是2个测试用网页,功能很简单, 就是在把test.jsp页面输入框中输入的内容提交到result.jsp页面然后显示 。麻雀虽小五脏俱全, 乱码时候涉及的要素这个jsp文件里面都有了。 首先我们先搞清这样几个重要的概念。
1、文件的编码
2、浏览器的编码
3、字符串的解码、编码
4、容器的编码,这里的容器就是tomcat。 这个页面的运行在tomcat内部, 一切都受到它的控制。
下面咱们结合上面那个jsp文件来对上面4点一一来说明:
1、文件的编码
我们日常使用记事本或者其他文本工具的时候, 写一个文本文档, 然后点击“另存”的时候, 会弹出一个对话框, 里面都会有让你选择encoding 这样一个选项。只是咱们默认都是gbk。 如图:
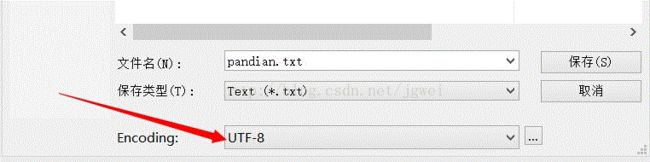
为啥需要这么多编码? 如果这个地方你就有困惑的话, 就需要好好补补计算机基础知识, 然后再来看下面的内容。
好咱们再说下jsp,jsp是什么?其实就是servlet, 但是比servlet多一个步骤, 恰恰是多的这个步骤,这个步骤是什么? 就是在tomcat的work路径下面每个jsp都会被tomcat自动解析成一个servlet文件。注意:我们编写的jsp在运行的时候变成了servlet, 这样是不是就存在2个文件了(一个我们自己编写的jsp, 一个tomcat根据jsp自动产生的servelet)。特别说明这个servlet是自动生成的。 这个地方就有像你刚刚在记事本里面点“另存”一样, 需要设置这个另存的文件的编码的。 不然这个servlet会已何种编码生成? jsp的发明者就设定了这样个语法:
- <%@ page language="java" isThreadSafe="true" pageEncoding="gbk" %>
pageEncoding 就是做这个用的。所以你的这个jsp文件的编码是utf8, 这个pageEncoding 就设置成utf8, 要一致, 否则, 从jsp生成的servlet就乱码了(当然是里面有中文的时候)。
2、浏览器的编码
好了jsp可以编译成正确的servlet, 在浏览器中也可以正常看到了。
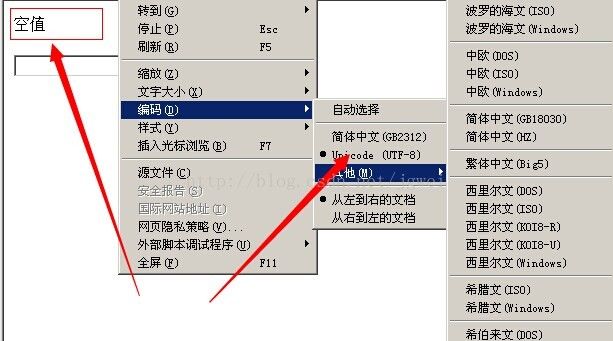
如图, 在浏览器的设置里面可以看到“编码”这个选项, 注意页面显示正常的时候,编码选择在utf-8, 如果我们这时候把浏览器的页面编码选择成“gbk“ , 就乱码了。
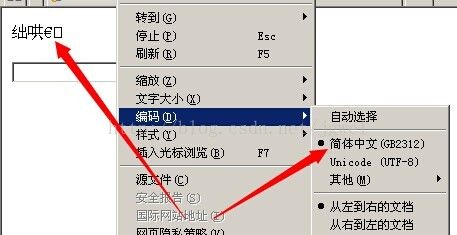
为啥会这样呢?
我们再看看源码中, 有这样一句:
- <%@ page contentType="text/html;charset=utf8"%>
这就是servlet说, 我要返回utf8编码的内容, 同时浏览器才可以使用utf8的编码识别返回的页面, 如果使用其他编码的话, 自然出现乱码。这点我们可以打开tomcat下面jsp自动生成的那个servlet, 会看到如下代码:
- public void _jspService(final javax.servlet.http.HttpServletRequest request, final javax.servlet.http.HttpServletResponse response)
- throws java.io.IOException, javax.servlet.ServletException {
- final javax.servlet.jsp.PageContext pageContext;
- javax.servlet.http.HttpSession session = null;
- final javax.servlet.ServletContext application;
- final javax.servlet.ServletConfig config;
- javax.servlet.jsp.JspWriter out = null;
- final java.lang.Object page = this;
- javax.servlet.jsp.JspWriter _jspx_out = null;
- javax.servlet.jsp.PageContext _jspx_page_context = null;
- try {
- response.setContentType("text/html;charset=utf8");
- pageContext = _jspxFactory.getPageContext(this, request, response,
- null, true, 8192, true);
- _jspx_page_context = pageContext;
- application = pageContext.getServletContext();
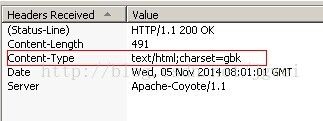
通过代码, 我们可以清楚的看到, servlet里面明确设置了response.setContentType("text/html;charset=utf8");
通用我们使用工具也可以在浏览器里面看到这样的标示:
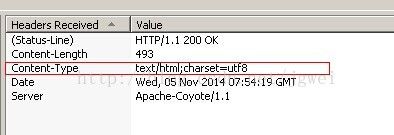
编码一致: servlet 和浏览器配合一致, 才可以正常显示。
我们如果把源码中做下修改:
那么servlet中的源码就变成了:
- public void _jspService(final javax.servlet.http.HttpServletRequest request, final javax.servlet.http.HttpServletResponse response)
- throws java.io.IOException, javax.servlet.ServletException {
- final javax.servlet.jsp.PageContext pageContext;
- javax.servlet.http.HttpSession session = null;
- final javax.servlet.ServletContext application;
- final javax.servlet.ServletConfig config;
- javax.servlet.jsp.JspWriter out = null;
- final java.lang.Object page = this;
- javax.servlet.jsp.JspWriter _jspx_out = null;
- javax.servlet.jsp.PageContext _jspx_page_context = null;
- try {
- response.setContentType("text/html;charset=gbk");
- pageContext = _jspxFactory.getPageContext(this, request, response,
- null, true, 8192, true);
servlet中设置编码的地方变成了response.setContentType("text/html;charset=gbk");
浏览器接收到网页内容的地方也变成了gbk
这个地方还有另外一个写法, jsp直接按照html的语法写就可以
- <meta http-equiv="Content-Type" content="text/html; charset=utf-8">
这个的作用和jsp的写法
- <%@ page contentType="text/html;charset=gbk"%>
等效, 2者是等效的, 后者是jsp语法, 前者是html脚本。 这点可以通过查看jsp生成的servlet的源码验证jsp语法的作用。
到目前为止我们可以发现显示的时候只是关系到浏览器如何识别读取到的页面的编码。只要页面本身里面没有乱码, 还是可以通过手工切换浏览器的编码来适应页面的编码。当然如果你的程序仅仅是一个页面用了显示数据的话, 这个charset你可以随便写, 对你的程序不会产生任何影响, 是服务器告诉浏览器如何解析编码。 但是这个太不理想, 因为一个系统往往是N多的页面组成的, 那就会产生影响了, 咱们下面就来讨论下。
3、字符串的解码、编码
好了, 讲了半天都是单页面的显示, 总算开始提交以下页面了。 首先我们把test.jsp 和result.jsp 的页面的头都设置成
- <%@ page language="java" isThreadSafe="true" pageEncoding="utf8" %>
- <%@ page contentType="text/html; charset=utf8"%>
在浏览器中访问test.jsp, 输入“中文”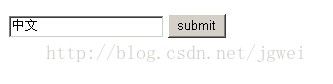
点提交以后:

从页面上看 有乱码, 但是也有正常的。 好先不管其他, 再做个试验:
把test.jsp 的头改成【注意这里只是修改了test.jsp的编码, result.jsp仍然是utf8】:
- <%@ page language="java" isThreadSafe="true" pageEncoding="utf8" %>
- <%@ page contentType="text/html; charset=gbk"%>
然后再重复以上提交步骤, 结果如图:

我们把二者的结果对比下, 可以很清楚的看到区别, 结合我们修改的test.jsp 的编码, 是不是可以得出这样的结论:
test.jsp的charset编码utf8 ---------------------> result.jsp 里面utf8编码显示正常, 而其他的乱码
test.jsp的charset编码gbk ---------------------> result.jsp 里面gbk编码显示正常,而其他的乱码
而且和result.jsp的charset的编码无关, 不管其是utf8或者gbk, 原因上文已经分析过了。
我们的在result.jsp这样接受test.jsp 发送过来的内容
- String abc = request.getParameter("abc");
- if(abc == null) {
- out.println("空值");
- }
- else
- {
- out.println("原始编码:");
- out.println(abc);
- out.println(java.util.Arrays.toString(abc.getBytes("ISO-8859-1")));
- out.println(new String(abc.getBytes("ISO-8859-1")));
- out.println("utf8编码:");
- System.out.println(abc1);
- out.println(abc1);
- out.println("gbk编码:");
-
- out.println(abc2);
- }
看下红色的部分, 就是解码的语句,
例如:
new String(abc.getBytes("ISO-8859-1"),"gbk");
就是把iso8859编码的字符串变成编码为gbk的字符串,如果先让你的最终结果对, 就要保证你的原始的字符串是iso8859编码的。
问题又来了。 为啥要在前面按照iso8859来呢? 我们明明在test.jsp中用的是是gbk或者utf8, 怎么会冒出个iso8859呢? 讲到这里, 不能不引出我们的幕后英雄tomcat。
4、容器的编码,这里的容器就是tomcat。 这个页面的运行在tomcat内部, 一切都受到它的控制。
test.jsp 和 result.jsp 都是放在容器tomcat中, 生成servlet是tomcat做的, 浏览器请求一个url地址, 端口监听、接收数据都是tomcat做的。 什么时候才是result.jsp
运行的时候?
- String abc = request.getParameter("abc");
这个才是第一句代码。 但是这个时候abc已经就是iso8859的编码了。怎么会这样的呢? 我们打开tomcat的源码一窥究竟。
- request.getParameter
实际调用的是
- org.apache.catalina.core.ApplicationHttpRequest.getParameter
然后调用
- org.apache.catalina.core.ApplicationHttpRequest.parseParameters
最后调用了
- org.apache.catalina.core.ApplicationHttpRequest.mergeParameters
让我们看看mergeParameters的具体实现:
- /**
- * Merge the parameters from the saved query parameter string (if any),
- * and the parameters already present on this request (if any),
- * such that the parameter values from the query string show up first if there are duplicate parameter names.
- */
- private void mergeParameters(){
- if ((queryParamString == null) || (queryParamString.length() < 1))
- return;
- HashMap queryParameters = new HashMap();
- String encoding = getCharacterEncoding();
- if (encoding == null)
- encoding = "ISO-8859-1";
- try{
- RequestUtil.parseParameters(queryParameters, queryParamString, encoding);
- }catch (Exception e){
- ;
- }
- Iterator keys = parameters.keySet().iterator();
- while (keys.hasNext()){
- String key = (String) keys.next();
- Object value = queryParameters.get(key);
- if (value == null){
- queryParameters.put(key, parameters.get(key));
- continue;
- }
- queryParameters.put(key, mergeValues(value, parameters.get(key)));
- }
- parameters = queryParameters;
- }
是不是很明白了,当encoding没有设置的时候, 就是ISO-8859-1, tomcat帮你把接收到的数据统统编码。
所以整个过程就变成了这样:
test.jsp --------------------------------------> tomcat --------------------------------------------> result.jsp
gbk/utf8 ===================== > iso8859 =========================> iso8859还原gbk/utf8
所以有了最原始的解码方法, 也就是自己纯手工解码
- String abc1 = new String(abc.getBytes("ISO-8859-1"),"utf8");
- String abc2 = new String(abc.getBytes("ISO-8859-1"),"gbk");
虽然原始、繁琐, 但是这个最基本的方式方法。体现了这个解码的过程。
总结:
jsp乱码的几个基本的原因大概就是这样。 只要明白了以上的道理,合理的运用文件的编码、页面的编码、以及对应的解码,应该就可以避免这些问题的出现。
这里重点于这些问题的原因,等有时间再总结下tomcat下面统一处理jsp乱码的方式方法。以上都是一家之言, 对与不对希望各位多交流。