hadoop环境搭建(详解)
hadoop 环境搭建
引言: 随着人工智能和大数据的热潮的到来,大数据变得越来越火了,坏蛋哥的信念就是致力于大数据的发展和进步,希望能为大数据的发展和推广尽一份绵薄之力。如果要做大数据,那么大数据相关的环境的搭建就是开始的一步。hadoop环境可能是大数据大家最开始搭建的环境吧。对于很多小白,如果盲目的搭建,那么很可能会崩溃,那么坏蛋哥就出一期文章专门讲解搭建大数据环境。首先我们就来搭建大象级别的hadoop。
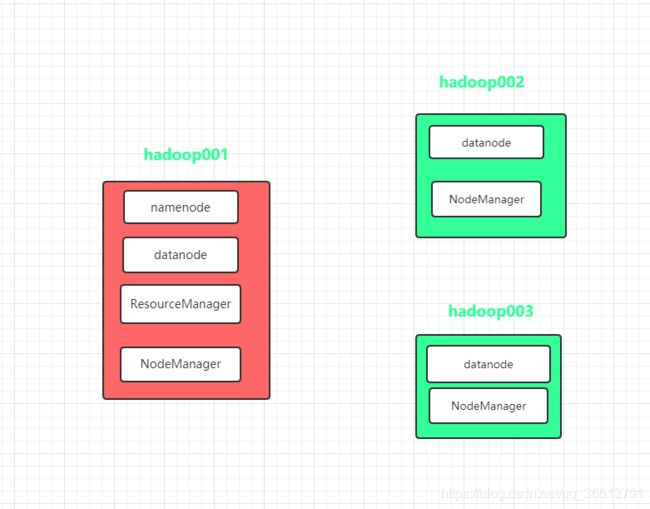
集群结构图:
文章结构:
- 基础软件准备
- hadoop安装包下载和解压
- 环境变量配置和配置文件配置
- hdfs读写性能和mapreduce性能测试
- 总结
1. 基础软件准备
hadopp基础软件需要ssh和java的jdk支持。因为hadoop程序是运行在jvm虚拟机中和需要ssh来提供安装的连接和通信。jdk需要安装jdk8及以上。我用的是oracle的java8,可以在官网上下载,如果有需要指导的可以百度,毕竟他不是我们这篇文章的重点。ssh安装ubuntu可以通过 apt install ssh安装。
下面如何用ssh来配置整个环境
首先配置ip地址映射
vim /etc/hosts
#添加ip地址后退出,下面的ip地址根据自己自己集群的实际进行设置
192.168.133.1 hadoop001
192.168.133.2 hadoop002
192.168.133.3 hadoop003
#给hadoop001生成ssh密钥
ssh-keygen -ras
#配置hadoop001免密登陆
ssh-copy-id username@hadoop001
ssh-copy-id username@hadoop002
ssh-copy-id username@hadoop003
#在hadoop001中验证ssh免密登陆是否配置成功
ssh hadoop001 date
ssh hadoop002 date
ssh hadoop003 date
2. 软件包下载
hadoop的包有三个版本:1.apache官方版本 2.CDH版本(对apache相互组件进行了兼容性优化) 3.HDP(可以二次开发,但是没有CDH稳定,国内使用较少)
我用的是: hadoop-2.6.0-cdh5.15.2.tar.gz 注:后面的5.15.2是cdh版本,如果需要其他组件,那么这个版本要保证一致性。
下载网址 : http://archive.cloudera.com/cdh5/cdh/5/
解压:
#创建指定的文件夹
mkdir /usr/hadoop
#解压
tar -zxvf tar -zxvf hadoop-2.6.0-cdh5.15.2.tgz -C /usr/hadoop
#更名
mv hadoop-2.6.0-cdh5.15.2 hadoop
3. 环境变量和配置文件配置
vim /etc/profile
#添加hadoop环境变量
export HADOOP_HOME=/usr/hadoop/hadoop/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#激活
source /etc/profile
hadoop主要配置文件有8个(core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml,hadoop-env.sh,yarn-env.sh,mapred-env.sh,slaves)
此次我们搭建需要配置 hadoop-env.sh,core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml和slaves
下面依次配置为:
hadoop-env.sh:
# 指定JDK的安装位置
export JAVA_HOME=/usr/java/jdk1.8/
core-site.xml:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop001:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/tmpvalue>
property>
configuration>
hdfs-site.xml
<property>
<name>dfs.namenode.name.dirname>
<value>/home/hadoop/namenode/datavalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/home/hadoop/datanode/datavalue>
property>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop001rvalue>
property>
configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
slaves:
配置所有从属节点的主机名或 IP 地址,每行一个。所有从属节点上的 DataNode 服务和 NodeManager 服务都会被启动
#添加slaves
hadoop001
hadoop002
hadoop003
最后需要通过hadoop001分发配置好的配置文件和/etc/profile:
#分发配置文件
scp -r /usr/hadoop hadoop1:/usr/
scp -r /usr/hadoop hadoop2:/usr/
#分发/etc/profile
scp -r /etc/profile hadoop1:/etc/
scp -r /etc/profile hadoop2:/etc/
#当然需要手敲命令的事都可以用脚本来简化,这儿当然也不例外,但这儿就不写出来了,有机会会出一篇相应的文章讲解各个组件的脚本
4. 测试
首先需要启动集群:
#如果是第一次启动要在hadoop001上对hdfs文件系统进行相应的格式化操作
hdfs namenode -format
#然后启动;
start-dfs.sh
start-yarn.sh
系统在启动后一段时间内会保持安全模式,在此模式下不能对文件进行修改,可以人为的消除安全模式:
#输入命令
hdfs dfsadmin -safemode leave
4.1 测试HDFS写性能
hadoop jar /usr/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
#参数说明:
第一参数是jar绝对路径
第二个参数是运行这个jar包中的main方法所在的那个类名
第三个参数说明是测试写
第四个参数是写入几个文件
第五个参数是每个文件大小(因为hdfs每个块默认是128m所以我们就以它为测试单位)
会算出下面重要信息:
19/05/02 11:45:23 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
19/05/02 11:45:23 INFO fs.TestDFSIO: Date & time: Thu May 02 11:45:23 CST 2019
19/05/02 11:45:23 INFO fs.TestDFSIO: Number of files: 10
19/05/02 11:45:23 INFO fs.TestDFSIO: Total MBytes processed: 1280.0
19/05/02 11:45:23 INFO fs.TestDFSIO: Throughput mb/sec: 10.69751115716984
19/05/02 11:45:23 INFO fs.TestDFSIO: Average IO rate mb/sec: 14.91699504852295
19/05/02 11:45:23 INFO fs.TestDFSIO: IO rate std deviation: 11.160882132355928
19/05/02 11:45:23 INFO fs.TestDFSIO: Test exec time sec: 52.315
4.2 测试HDFS读性能
测试内容:读取HDFS集群10个128M的文件
hadoop jar /usr/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
同样能获取到下面信息:
19/05/02 11:56:36 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
19/05/02 11:56:36 INFO fs.TestDFSIO: Date & time: Thu May 02 11:56:36 CST 2019
19/05/02 11:56:36 INFO fs.TestDFSIO: Number of files: 10
19/05/02 11:56:36 INFO fs.TestDFSIO: Total MBytes processed: 1280.0
19/05/02 11:56:36 INFO fs.TestDFSIO: Throughput mb/sec: 16.001000062503905
19/05/02 11:56:36 INFO fs.TestDFSIO: Average IO rate mb/sec: 17.202795028686523
19/05/02 11:56:36 INFO fs.TestDFSIO: IO rate std deviation: 4.881590515873911
19/05/02 11:56:36 INFO fs.TestDFSIO: Test exec time sec: 49.116
4.3删除测试生成数据
hadoop jar /usr/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar TestDFSIO -clean
4.3使用Sort程序评测MapReduce
- 使用RandomWriter来产生随机数,每个节点运行10个Map任务,每个Map产生大约1G大小的二进制随机数
hadoop jar /usr/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar randomwriter random-data
- 执行Sort程序
hadoop jar /usr/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar sort random-data sorted-data
- 验证数据是否真正排好序了
hadoop jar /usr/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar testmapredsort -sortInput random-data -sortOutput sorted-data
5 总结
是不是感觉迫不及待的想要实操起来了,尽管去实践吧,有什么问题可以和我讨论哦,我会尽量回复大家的。谢谢大家的阅读!欢迎关注我的公众新号,每天会分享大数据相关的干货哦。如果热爱大数据那么一定要关注坏蛋哥哦。

参考文献;
github 文章:https://github.com/heibaiying/BigData-Notes
尚硅谷大数据实战