多元线性回归--案例分析及python实践
回归分析--多元回归
介绍一下多元回归分析中的统计量
- 总观测值

- 总自变量

- 自由度
 :回归自由度
:回归自由度 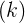 ,残差自由度
,残差自由度 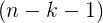
- SST总平方和

- SSR回归平方和

- SSE残差平方和

- MSR均方回归
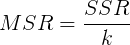
- MSE均方残差
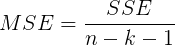
- 判定系数R_square
- 调整的判定系数Adjusted_R_square
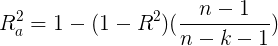
- 复相关系数Multiple_R
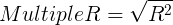
- 估计标准误差
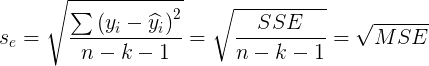
- F检验统计量
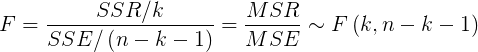
- 回归系数抽样分布的标准误差

- 各回归系数的t检验统计量

- 各回归系数的置信区间
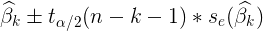
- 对数似然值(log likelihood)
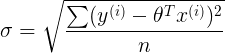

- AIC准则
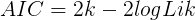
- BIC准则
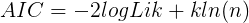
案例分析及python实践
# 导入相关包
import pandas as pd
import numpy as np
import math
import scipy
import matplotlib.pyplot as plt
from scipy.stats import t# 构建数据
columns = {'A':"分行编号", 'B':"不良贷款(亿元)", 'C':"贷款余额(亿元)", 'D':"累计应收贷款(亿元)", 'E':"贷款项目个数", 'F':"固定资产投资额(亿元)"}
data={"A":[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25],
"B":[0.9,1.1,4.8,3.2,7.8,2.7,1.6,12.5,1.0,2.6,0.3,4.0,0.8,3.5,10.2,3.0,0.2,0.4,1.0,6.8,11.6,1.6,1.2,7.2,3.2],
"C":[67.3,111.3,173.0,80.8,199.7,16.2,107.4,185.4,96.1,72.8,64.2,132.2,58.6,174.6,263.5,79.3,14.8,73.5,24.7,139.4,368.2,95.7,109.6,196.2,102.2],
"D":[6.8,19.8,7.7,7.2,16.5,2.2,10.7,27.1,1.7,9.1,2.1,11.2,6.0,12.7,15.6,8.9,0,5.9,5.0,7.2,16.8,3.8,10.3,15.8,12.0],
"E":[5,16,17,10,19,1,17,18,10,14,11,23,14,26,34,15,2,11,4,28,32,10,14,16,10],
"F":[51.9,90.9,73.7,14.5,63.2,2.2,20.2,43.8,55.9,64.3,42.7,76.7,22.8,117.1,146.7,29.9,42.1,25.3,13.4,64.3,163.9,44.5,67.9,39.7,97.1]
}
df = pd.DataFrame(data)
X = df[["C", "D", "E", "F"]]
Y = df[["B"]]# 构建多元线性回归模型
from sklearn.linear_model import LinearRegression
lreg = LinearRegression()
lreg.fit(X, Y)
x = X
y_pred = lreg.predict(X)
y_true = np.array(Y).reshape(-1,1)
coef = lreg.coef_[0]
intercept = lreg.intercept_[0]# 自定义函数
def log_like(y_true, y_pred):
"""
y_true: 真实值
y_pred:预测值
"""
sig = np.sqrt(sum((y_true - y_pred)**2)[0] / len(y_pred)) # 残差标准差δ
y_sig = np.exp(-(y_true - y_pred) ** 2 / (2 * sig ** 2)) / (math.sqrt(2 * math.pi) * sig)
loglik = sum(np.log(y_sig))
return loglik
def param_var(x):
"""
x:只含自变量宽表
"""
n = len(x)
beta0 = np.ones((n,1))
df_to_matrix = x.as_matrix()
concat_matrix = np.hstack((beta0, df_to_matrix)) # 矩阵合并
transpose_matrix = np.transpose(concat_matrix) # 矩阵转置
dot_matrix = np.dot(transpose_matrix, concat_matrix) # (X.T X)^(-1)
inv_matrix = np.linalg.inv(dot_matrix) # 求(X.T X)^(-1) 逆矩阵
diag = np.diag(inv_matrix) # 获取矩阵对角线,即每个参数的方差
return diag
def param_test_stat(x, Se, intercept, coef, alpha=0.05):
n = len(x)
k = len(x.columns)
beta_array = param_var(x)
beta_k = beta_array.shape[0]
coef = [intercept] + list(coef)
std_err = []
t_Stat = []
P_value = []
t_intv = []
coefLower = []
coefupper = []
for i in range(beta_k):
se_belta = np.sqrt(Se**2 * beta_array[i]) # 回归系数的抽样标准误差
t = coef[i] / se_belta # 用于检验回归系数的t统计量, 即检验统计量t
p_value = scipy.stats.t.sf(np.abs(t), n-k-1)*2 # 用于检验回归系数的P值(P_value)
t_score = scipy.stats.t.isf(alpha/2, df = n-k-1) # t临界值
coef_lower = coef[i] - t_score * se_belta # 回归系数(斜率)的置信区间下限
coef_upper = coef[i] + t_score * se_belta # 回归系数(斜率)的置信区间上限
std_err.append(round(se_belta, 3))
t_Stat.append(round(t,3))
P_value.append(round(p_value,3))
t_intv.append(round(t_score,3))
coefLower.append(round(coef_lower,3))
coefupper.append(round(coef_upper,3))
dict_ = {"coefficients":list(map(lambda x:round(x, 4), coef)),
'std_err':std_err,
't_Stat':t_Stat,
'P_value':P_value,
't临界值':t_intv,
'Lower_95%':coefLower,
'Upper_95%':coefupper}
index = ["intercept"] + list(x.columns)
stat = pd.DataFrame(dict_, index=index)
return stat# 自定义函数(计算输出各回归分析统计量)
def get_lr_stats(x, y_true, y_pred, coef, intercept, alpha=0.05):
n = len(x)
k = len(x.columns)
ssr = sum((y_pred - np.mean(y_true))**2)[0] # 回归平方和 SSR
sse = sum((y_true - y_pred)**2)[0] # 残差平方和 SSE
sst = ssr + sse # 总平方和 SST
msr = ssr / k # 均方回归 MSR
mse = sse / (n-k-1) # 均方残差 MSE
R_square = ssr / sst # 判定系数R^2
Adjusted_R_square = 1-(1-R_square)*((n-1) / (n-k-1)) # 调整的判定系数
Multiple_R = np.sqrt(R_square) # 复相关系数
Se = np.sqrt(sse/(n - k - 1)) # 估计标准误差
loglike = log_like(y_true, y_pred)[0]
AIC = 2*(k+1) - 2 * loglike # (k+1) 代表k个回归参数或系数和1个截距参数
BIC = -2*loglike + (k+1)*np.log(n)
# 线性关系的显著性检验
F = (ssr / k) / (sse / ( n - k - 1 )) # 检验统计量F (线性关系的检验)
pf = scipy.stats.f.sf(F, k, n-k-1) # 用于检验的显著性F,即Significance F
Fa = scipy.stats.f.isf(alpha, dfn=k, dfd=n-k-1) # F临界值
# 回归系数的显著性检验
stat = param_test_stat(x, Se, intercept, coef, alpha=alpha)
# 输出各回归分析统计量
print('='*80)
print('df_Model:{} df_Residuals:{}'.format(k, n-k-1), '\n')
print('loglike:{} AIC:{} BIC:{}'.format(round(loglike,3), round(AIC,1), round(BIC,1)), '\n')
print('SST:{} SSR:{} SSE:{} MSR:{} MSE:{} Se:{}'.format(round(sst,4),
round(ssr,4),
round(sse,4),
round(msr,4),
round(mse,4),
round(Se,4)), '\n')
print('Multiple_R:{} R_square:{} Adjusted_R_square:{}'.format(round(Multiple_R,4),
round(R_square,4),
round(Adjusted_R_square,4)), '\n')
print('F:{} pf:{} Fa:{}'.format(round(F,4), pf, round(Fa,4)))
print('='*80)
print(stat)
print('='*80)
return 0输出结果如下:

对比statsmodels下ols结果:

参考资料:
【1】https://www.zhihu.com/question/328568463
【2】https://blog.csdn.net/qq_38998213/article/details/83480147