SparkSQL中使用concat_ws函数报错:cannot resolve 'concat_ws(,,(hiveudaffunction...
一、报错信息
Exception in thread "main" org.apache.spark.sql.AnalysisException: cannot resolve 'concat_ws(,,(hiveudaffunction(HiveFunctionWrapper(org.apache.hadoop.hive.ql.udf.generic.GenericUDAFCollectSet,org.apache.hadoop.hive.ql.udf.generic.GenericUDAFCollectSet@1208707b),SF_ID,false,0,0),mode=Complete,isDistinct=false))' due to data type mismatch: argument 2 requires (array
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42)
二、报错原因分析
1. 分析SQL语句
select t1.ACTIVITY_ID,concat_ws(',',collect_set(t1.SF_ID)) as SF_IDS
from str_template_rel t1
group by t1.ACTIVITY_ID;使用DBVisualizer客户端连接Spark(参考博文:https://blog.csdn.net/u011817217/article/details/81673101),将SQL语句拆解初步排查问题。
1)排查是否为表数据问题
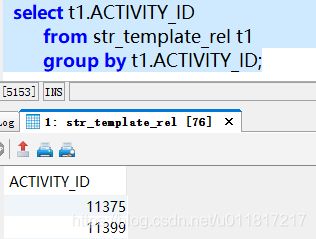
发现源表中activity_id字段数据没有问题;
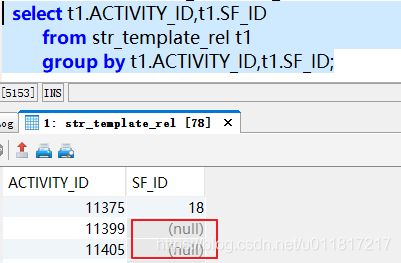
发现源表中sf_id字段中部分数据值为null,初步怀疑是不是null影响了concat_ws函数的使用;
于是对SQL语句进行改进:

还是报同样的错误。
2)排查是否为concat_ws函数使用不规范问题
collect_set中不使用表中的字段而是使用固定的值,如下:

这次从错误Message中发现了一条重要信息:due to data type mismatch, requires (array
如梦初醒,原来collect_set中填入的必须是string类型,测试下:
果不其然,把数值1加上单引号后,再次执行SQL没有报错:
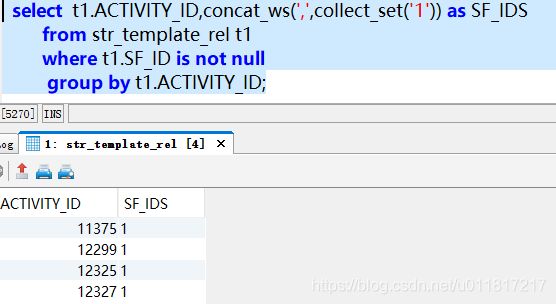
所以,问题出在t1.SF_ID字段类型上。
3)t1.SF_ID字段类型
查看str_template_rel表的结构描述,如下:
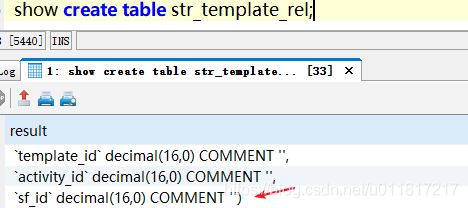
sf_id字段是数值类型。
三、解决方案
既然发现问题是出在sf_id字段的类型上,需要将数值类型转换为字符类型。
于是对SQL语句进行改造:
select t1.ACTIVITY_ID,concat_ws(',',collect_set(cast(t1.SF_ID as string))) as SF_IDS
from str_template_rel t1
where t1.SF_ID is not null
group by t1.ACTIVITY_ID;
完美解决!!!
反思:concat_ws函数中collect_set传入的值必须为string类型。