Hash Table哈希表和Hash List哈希链表的知识汇总
本文分为三个部分:
一 Hash Table 概论
二 Linux源代码中的Hash List
三 Linux源代码中的Hash Table
一 Hash Table概论
字符串的算法一般大公司都会考到,我们首先要想到高效的hash。如百度查找一组字符串是否出现在某个文本中,这个不是考什么kmp,他们想听到的是hash。趋势科技考的是从某个文本中删除一组字符串,我想也是要hash吧。
1 概述
链表查找的时间效率为O(N),二分法为log2N,B+ Tree为log2N,但Hash链表查找的时间效率为O(1)。
设计高效算法往往需要使用Hash链表,常数级的查找速度是任何别的算法无法比拟的,Hash链表的构造和冲突的不同实现方法对效率当然有一定的影响,然 而Hash函数是Hash链表最核心的部分,本文尝试分析一些经典软件中使用到的字符串Hash函数在执行效率、离散性、空间利用率等方面的性能问题。
2 经典字符串Hash函数介绍
先提一个简单的问题,如果有一个庞大的字符串数组,然后给你一个单独的字符串,让你从这个数组中查找是否有这个字符串并找到它,你会怎么做?有一个方法最简单,老老实实从头查到尾,一个一个比较,直到找到为止,我想只要学过程序设计的人都能把这样一个程序作出来,但要是有程序员把这样的程序交给用户,我只能用无语来评价,或许它真的能工作,但...也只能如此了。最合适的算法自然是使用HashTable(哈希表),先介绍介绍其中的基本知识,所谓Hash,一般是一个整数,通过某种算法,可以把一个字符串"压缩" 成一个整数,这个数称为Hash.
HDOJ-1800题目分析
除去马甲,本题的本质是——求相同级别(level)的人最多是几个。
如果level的范围不大的话(64位整数可以表示)——本题很简单,简单贪心
本题的难点:level的范围较大,需用大数或者字符串比较(去首0)
效率较高、编程简单的方法:Hash!
此外,字典树也是不错的选择
#include "stdio.h"
#include "memory.h"
#define MAXN 10000
inline int ELFhash(char *key)
{
unsigned long h = 0;
unsigned long g;
while( *key )
{
h =( h<< 4) + *key++;
g = h & 0xf0000000L;
if( g ) h ^= g >> 24;
h &= ~g;
}
return h;
}
int hash[MAXN],count[MAXN];
int maxit,n;
inline void hashit(char *str)
{
int k,t;
while( *str == '0' ) str++;
k = ELFhash(str);
t = k % MAXN;
while( hash[t] != k && hash[t] != -1 )
t = ( t + 5 ) % MAXN;
if( hash[t] == -1 )
count[t] = 1,hash[t] = k;
else if( ++count[t] > maxit )
maxit = count[t];
}
int main()
{
char str[100];
while(scanf("%d",&n)!=EOF)
{
memset(hash,-1,sizeof(hash));
for(maxit=1,gets(str);n>0;n--) // 此处的gets是吸收掉之前输入个数后的回车
{
gets(str);
hashit(str);
}
printf("%d\n",maxit);
}
}
一 Hash Table 概论
二 Linux源代码中的Hash List
三 Linux源代码中的Hash Table
一 Hash Table概论
字符串的算法一般大公司都会考到,我们首先要想到高效的hash。如百度查找一组字符串是否出现在某个文本中,这个不是考什么kmp,他们想听到的是hash。趋势科技考的是从某个文本中删除一组字符串,我想也是要hash吧。
1 概述
链表查找的时间效率为O(N),二分法为log2N,B+ Tree为log2N,但Hash链表查找的时间效率为O(1)。
设计高效算法往往需要使用Hash链表,常数级的查找速度是任何别的算法无法比拟的,Hash链表的构造和冲突的不同实现方法对效率当然有一定的影响,然 而Hash函数是Hash链表最核心的部分,本文尝试分析一些经典软件中使用到的字符串Hash函数在执行效率、离散性、空间利用率等方面的性能问题。
2 经典字符串Hash函数介绍
先提一个简单的问题,如果有一个庞大的字符串数组,然后给你一个单独的字符串,让你从这个数组中查找是否有这个字符串并找到它,你会怎么做?有一个方法最简单,老老实实从头查到尾,一个一个比较,直到找到为止,我想只要学过程序设计的人都能把这样一个程序作出来,但要是有程序员把这样的程序交给用户,我只能用无语来评价,或许它真的能工作,但...也只能如此了。最合适的算法自然是使用HashTable(哈希表),先介绍介绍其中的基本知识,所谓Hash,一般是一个整数,通过某种算法,可以把一个字符串"压缩" 成一个整数,这个数称为Hash.
HDOJ-1800题目分析
除去马甲,本题的本质是——求相同级别(level)的人最多是几个。
如果level的范围不大的话(64位整数可以表示)——本题很简单,简单贪心
本题的难点:level的范围较大,需用大数或者字符串比较(去首0)
效率较高、编程简单的方法:Hash!
此外,字典树也是不错的选择
#include "stdio.h"
#include "memory.h"
#define MAXN 10000
inline int ELFhash(char *key)
{
unsigned long h = 0;
unsigned long g;
while( *key )
{
h =( h<< 4) + *key++;
g = h & 0xf0000000L;
if( g ) h ^= g >> 24;
h &= ~g;
}
return h;
}
int hash[MAXN],count[MAXN];
int maxit,n;
inline void hashit(char *str)
{
int k,t;
while( *str == '0' ) str++;
k = ELFhash(str);
t = k % MAXN;
while( hash[t] != k && hash[t] != -1 )
t = ( t + 5 ) % MAXN;
if( hash[t] == -1 )
count[t] = 1,hash[t] = k;
else if( ++count[t] > maxit )
maxit = count[t];
}
int main()
{
char str[100];
while(scanf("%d",&n)!=EOF)
{
memset(hash,-1,sizeof(hash));
for(maxit=1,gets(str);n>0;n--) // 此处的gets是吸收掉之前输入个数后的回车
{
gets(str);
hashit(str);
}
printf("%d\n",maxit);
}
}
延伸:
在C语言中,接受输入单个字符的函数如scanf、getchar()等都有一个毛病,就是程序接受完用户输入的字符后并没有清空键盘输入缓冲区(或者说标准输入流),,因此当用户输完字符和回车后,回车字符还留在标准输入流中,而gets函数又恰好从缓冲区的当前字符开始接收输入,这样,它接收的到第一个字符就是上次输入遗留下来的回车符号,于是程序又会把它作为结束输入的标志,不再接受用户的键盘输入。 而C++的输入流就改正了这个毛病,接受完后自动清空输入流。
==================================================
#用的是开放定址法处理冲突,线性探测再散列确定增量
#include
#include
#include
#include
#include
#include
#include
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define SUCCESS 1
#define UNSUCCESS 0
#define DUPLICATE -1
#define NULLKEY 0 // 0为无记录标志
#define N 10 // 数据元素个数
#define EQ(a,b) ((a)==(b))
#define LT(a,b) ((a)<(b))
#define LQ(a,b) ((a)<=(b))
typedef int Status; // Status是函数的类型,其值是函数结果状态代码,如OK等
typedef int Boolean; // Boolean是布尔类型,其值是TRUE或FALSE
typedef int KeyType; // 设关键字域为整型
#include
#include
#include
#include
#include
#include
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define SUCCESS 1
#define UNSUCCESS 0
#define DUPLICATE -1
#define NULLKEY 0 // 0为无记录标志
#define N 10 // 数据元素个数
#define EQ(a,b) ((a)==(b))
#define LT(a,b) ((a)<(b))
#define LQ(a,b) ((a)<=(b))
typedef int Status; // Status是函数的类型,其值是函数结果状态代码,如OK等
typedef int Boolean; // Boolean是布尔类型,其值是TRUE或FALSE
typedef int KeyType; // 设关键字域为整型
struct ElemType // 数据元素类型
{
KeyType key;
int ord;
};
{
KeyType key;
int ord;
};
int hashsize[]={11,19,29,37}; // 哈希表容量递增表,一个合适的素数序列
int m=0; // 哈希表表长,全局变量
struct HashTable
{
ElemType *elem; // 数据元素存储基址,动态分配数组
int count; // 当前数据元素个数
int sizeindex; // hashsize[sizeindex]为当前容量
};
int m=0; // 哈希表表长,全局变量
struct HashTable
{
ElemType *elem; // 数据元素存储基址,动态分配数组
int count; // 当前数据元素个数
int sizeindex; // hashsize[sizeindex]为当前容量
};
Status InitHashTable(HashTable &H)// 操作结果: 构造一个空的哈希表
{ int i;
H.count=0; // 当前元素个数为0
H.sizeindex=0; // 初始存储容量为hashsize[0]
m=hashsize[0];
H.elem=(ElemType*)malloc(m*sizeof(ElemType));
if(!H.elem)
exit(OVERFLOW); // 存储分配失败
for(i=0;i H.elem[i].key=NULLKEY; // 未填记录的标志
return OK;
}
{ int i;
H.count=0; // 当前元素个数为0
H.sizeindex=0; // 初始存储容量为hashsize[0]
m=hashsize[0];
H.elem=(ElemType*)malloc(m*sizeof(ElemType));
if(!H.elem)
exit(OVERFLOW); // 存储分配失败
for(i=0;i
return OK;
}
void DestroyHashTable(HashTable &H)// 初始条件: 哈希表H存在。操作结果: 销毁哈希表H
{ free(H.elem);
H.elem=NULL;
H.count=0;
H.sizeindex=0;
}
{ free(H.elem);
H.elem=NULL;
H.count=0;
H.sizeindex=0;
}
unsigned Hash(KeyType K)// 一个简单的哈希函数(m为表长,全局变量)
{ return K%m;
}
{ return K%m;
}
void collision(int &p,int d) // 线性探测再散列
{
p=(p+d)%m;// 开放定址法处理冲突
}
{
p=(p+d)%m;// 开放定址法处理冲突
}
Status SearchHash(HashTable H,KeyType K,int &p,int &c)// 在开放定址哈希表H中查找关键码为K的元素,若查找成功,以p指示待查数据
{ p=Hash(K); // 求得哈希地址
while(H.elem[p].key!=NULLKEY&&!EQ(K,H.elem[p].key))
{ // 该位置中填有记录.并且关键字不相等
c++;
if(c collision(p,c); // 求得下一探查地址p
else
break;
}
if EQ(K,H.elem[p].key)
return SUCCESS; // 查找成功,p返回待查数据元素位置
else
return UNSUCCESS; // 查找不成功(H.elem[p].key==NULLKEY),p返回的是插入位置
}
{ p=Hash(K); // 求得哈希地址
while(H.elem[p].key!=NULLKEY&&!EQ(K,H.elem[p].key))
{ // 该位置中填有记录.并且关键字不相等
c++;
if(c
else
break;
}
if EQ(K,H.elem[p].key)
return SUCCESS; // 查找成功,p返回待查数据元素位置
else
return UNSUCCESS; // 查找不成功(H.elem[p].key==NULLKEY),p返回的是插入位置
}
Status InsertHash(HashTable &,ElemType); // 对函数的声明
void RecreateHashTable(HashTable &H) // 重建哈希表
{ int i,count=H.count;
ElemType *p,*elem=(ElemType*)malloc(count*sizeof(ElemType));
p=elem;
printf("重建哈希表\n");
for(i=0;i if((H.elem+i)->key!=NULL
void RecreateHashTable(HashTable &H) // 重建哈希表
{ int i,count=H.count;
ElemType *p,*elem=(ElemType*)malloc(count*sizeof(ElemType));
p=elem;
printf("重建哈希表\n");
for(i=0;i
本文来自CSDN博客,转载请标明出处: http://blog.csdn.net/hell2pradise/archive/2009/08/12/4437041.aspx
二: Linux内核中Hash List的使用
其代码位于include/linux/list.h中,3.0内核中将其数据结构定义放在了include/linux/types.h中
哈希表的数据结构定义 如图:
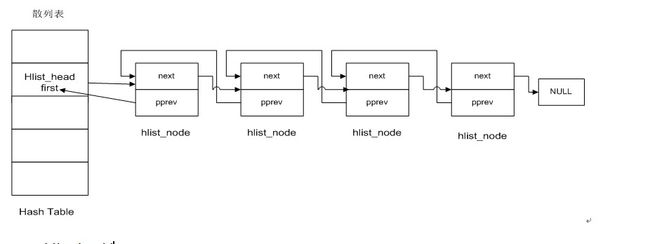
点击(此处)折叠或打开
- struct hlist_head{
- struct hlist_node *first;
- }
- struct hlist_node {
- struct hlist_node *next,**pprev;
- }
1> 头节点和其他节点结构不一致。
hlist_head表示哈希表的头结点。哈希表中每一个entry(list_entry)所对应的都是一个链表。
hlist_head结构体只有一个域,即first。First指针指向该hlist链表的第一个结点。
思考: 为什么采用单向链表,即头结点中没有prev变量?
散列表的目的是为了方便快速的查找,所以散列表通常是一个比较大的数组,否则“冲突”的概率会非常大,这样就失去了散列表的意义。如何来做到既能维护一张大表,又能不占用过多的内存呢?此时只能对于哈希表的每个entry(表头结点)它的结构体中只能存放一个指针。【简言之,节省空间】
2> hlist_node结构体有两个域,next和pprev。
(1)next指向下个hlist_node结点,倘若改结点是链表的最后一个节点,next则指向NULL
(2)pprev是一个二级指针,它指向前一个节点的next指针。
思考:*****为什么要采用pprev,而不采用一级指针?********
由于hlist不是一个完整的循环链表,在list中,表头和结点是同一个数据结构,直接用prev是ok的。在hlist中,表头中没有prev,只有一个first。
1>为了能统一地修改表头的first指针,即表头的first指针必须修改指向新插入的结点,hlist就设计了pprev。list结点的pprev不再是指向前一个结点的指针,而是指向前一个节点(可能是表头)中的next(对于表头则是first)指针,从而在表头插入的操作中可以通过一致的node->pprev访问和修改前结点的next(或first)指针。
2>还解决了数据结构不一致,hlist_node巧妙的将pprev指向上一个节点的next指针的地址,由于hlist_head和hlist_node指向的下一个节点的指针类型相同,就解决了通用性。
参考:http://blog.csdn.net/tigerjibo/article/details/8450995
三 Linux源代码中的Hash Table
这一部分是由 第二部分引出来的,以内核代码2.6.26为例
在文件error.c (net\9p)中有一个定义
static struct hlist_head hash_errmap[ERRHASHSZ];
点击(此处)折叠或打开
- int p9_error_init(void)
- {
- struct errormap *c;
- int bucket;
-
- /* initialize hash table */
- for (bucket = 0; bucket < ERRHASHSZ; bucket++)
- INIT_HLIST_HEAD(&hash_errmap[bucket]);
-
- /* load initial error map into hash table */
- for (c = errmap; c->name != NULL; c++) {
- c->namelen = strlen(c->name);
- /*Hash function 是由自己来确定的*/
- bucket = jhash(c->name, c->namelen, 0) % ERRHASHSZ;
- INIT_HLIST_NODE(&c->list);
- hlist_add_head(&c->list, &hash_errmap[bucket]);
- }
-
- return 1;
- }
http://fanrenhao.blog.51cto.com/3961213/1033529
构建一个文件hlist-module.c,
点击(此处)折叠或打开
- #include <linux/init.h>
- #include <linux/module.h>
- #include <linux/list.h>
-
- struct q_coef
- {
- u8 coef;
- u8 index;
- struct hlist_node hash;
- };
-
- #define HASH_NUMBER 15
- u8 coef[HASH_NUMBER] = {
- 0x01, 0x02, 0x04, 0x08,0x10, 0x20, 0x40, 0x80, 0x1d, 0x3a, 0x74, 0xe8, 0xcd, 0x87, 0x13,
- };
- struct q_coef q_coef_list[HASH_NUMBER];
-
- struct hlist_head hashtbl[HASH_NUMBER];
-
- static inline int hash_func(u8 k)
- {
- int a, b, p, m;
- a = 104;
- b = 52;
- p = 233;
- m = HASH_NUMBER;
- return ((a * k + b) % p) % m;
- }
-
- static void hash_init(void)
- {
- int i, j;
- for (i = 0 ; i < HASH_NUMBER ; i++) {
- INIT_HLIST_HEAD(&hashtbl[i]);
- INIT_HLIST_NODE(&q_coef_list[i].hash);
- q_coef_list[i].coef = coef[i];
- q_coef_list[i].index = i + 1;
- }
- for (i = 0 ; i < HASH_NUMBER ; i++) {
- j = hash_func(q_coef_list[i].coef);
- hlist_add_head(&q_coef_list[i].hash, &hashtbl[j]);
- }
- }
-
- static void hash_test(void)
- {
- int i, j;
- struct q_coef *q;
- struct hlist_node *hn;
- for (i = 0 ; i < HASH_NUMBER ; i++) {
- j = hash_func(coef[i]);
- hlist_for_each_entry(q, hn, &hashtbl[j], hash)
- if (q->coef == coef[i])
- printk("found: coef=0x%02x index=%d\n", q->coef, q->index);
- }
- }
- static int htest_init (void)
- {
- hash_init();
- hash_test();
- return -1;
- }
-
- static void htest_exit (void)
- {
- }
-
- module_init(htest_init);
- module_exit(htest_exit);
-
- MODULE_LICENSE("Dual BSD/GPL");
点击(此处)折叠或打开
- # Makefile2.6
- obj-m += hlist-module.o # ??hellomod ???????
- CURRENT_PATH := $(shell pwd) #?????????
- LINUX_KERNEL := $(shell uname -r) #Linux??????????
- LINUX_KERNEL_PATH := /usr/src/linux-headers-$(LINUX_KERNEL) #Linux??????????
- all:
- make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules #?????
- clean:
- make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean #??
然后make, 先把dmesg清空一下
$sudo dmesg --clear
然后
$ sudo insmod hlist_module.ko
这个一直显示有错误,不过不影响你看结果
ubuntu12:~/program/example/module2$ sudo insmod hlist_module.ko
insmod: error inserting 'hlist_module.ko': -1 Operation not permitted
看结果
$dmesg
yyyy@mren-ubuntu12:~/program/example/module2$ dmesg
[1318688.795697] found: coef=0x01 index=1
[1318688.795701] found: coef=0x02 index=2
[1318688.795703] found: coef=0x04 index=3
[1318688.795705] found: coef=0x08 index=4
[1318688.795707] found: coef=0x10 index=5
[1318688.795709] found: coef=0x20 index=6
[1318688.795711] found: coef=0x40 index=7
[1318688.795713] found: coef=0x80 index=8
[1318688.795715] found: coef=0x1d index=9
[1318688.795717] found: coef=0x3a index=10
[1318688.795719] found: coef=0x74 index=11
[1318688.795721] found: coef=0xe8 index=12
[1318688.795723] found: coef=0xcd index=13
[1318688.795725] found: coef=0x87 index=14
[1318688.795727] found: coef=0x13 index=15