CNN基础模型总结
所有内容仅供参考,只是为了复习方便,代码都是用于分类的代码,可能与论文中的模型有所差异。也放了一些阅读论文时候的连接
目录
一、LeNet-5
二、AlexNet
三、VGG
四、GoogleNet
五、ResNet
六、ResNeXt
七、DenseNet
八、ShuffleNet V1 与ShuffleNet V2
九、Pre-activation ResNet
十、EfficientNet
一、LeNet-5
0、资料
LeNet-5模型是Yann LeCun教授于1998年在论文《Gradient-based learning applied to document recognition》中提出。它是第一个成功应用于手写数字识别问题并产生实际商业(邮政行业)价值的卷积神经网络。论文下载
LeNet5的论文及理解
CNN只要有三大特色,分别是局部感知、权重共享和多卷积核。如何理解这三个特征呢?
(1)局部感知:局部感知就是我们上面说的感受野,实际上就是卷积核和图像卷积的时候,每次卷积核所覆盖的像素只是一小部分,是局部特征,所以说是局部感知。CNN是一个从局部到整体的过程(局部到整体的实现是在全连通层),而传统的神经网络是整体的过程。
(2)权重共享:不同的图像或者同一张图像共用一个卷积核,减少重复的卷积核。同一张图像当中可能会出现相同的特征,共享卷积核能够进一步减少权值参数。
(3)多卷积核:一种卷积核代表的是一种特征,为获得更多不同的特征集合,卷积层会有多个卷积核,生成不同的特征,这也是为什么卷积后的图片的高,每一个图片代表不同的特征。
1、模型图

其实简单来说,就是2个卷积层,每个卷积通过池化进行下采样,之后3个全连接层。

模型和下面代码是对应的,为了下面表述方便,把ReLU激活函数和池化层都画出出来了,虽然画了七层,但是其中的两个池化层是没有参数的,有参数的是卷积层(两个)和全连接层(三个),所以是LeNet-5网络结构图。使用池化层达到下采样的目的。
2、模型代码
# -*-coding:utf-8-*-
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self,num_classes=0):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(3,6,5)
self.conv2 = nn.Conv2d(6,16,5)
self.fc_1 = nn.Linear(16*5*5,120)
self.fc_2 = nn.Linear(120,84)
self.fc_3 = nn.Linear(84,num_classes)
def forward(self,x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out,2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out,2)
out = out.view(out.size(0),-1)
out = F.relu(self.fc_1(out))
out = F.relu(self.fc_2(out))
out = self.fc_3(out)
return out
from torchsummary import summary
# #d打印网络结构及参数和输出形状
net = LeNet(10)
summary(net, input_size=(3, 32, 32)) #summary(net,(3,250,250))3、分析LeNet-5的参数

输入层:图片大小为3×32×32,其中 3表示为彩色图像,3个 channel。
卷积层:filter 大小 5×5,filter 深度(个数)为 6,padding 为 0, 卷积步长 s=1,输出矩阵大小为6× 28×28,其中 6 表示 filter 的个数。参数个数:输入通道x输出通道x卷积核大小+偏置 = 3x6x5x5+6 = 456
池化层:average pooling,filter 大小 2×2(即 f=2),步长 s=2,no padding,输出矩阵大小为 16×14×14。
卷积层:filter 大小 5×5,filter 个数为 16,padding 为 0, 卷积步长 s=1s=1,输出矩阵大小为 16×10×10,其中 16 表示 filter 的个数。
池化层:average pooling,filter 大小 2×2(即 f=2),步长 s=2,no padding,输出矩阵大小为 16×5×5。注意,在该层结束,需要将 16×5×5 的矩阵flatten 成一个 400 维的向量。
全连接层(Fully Connected layer,FC):神经元的个数为 120。
全连接层(Fully Connected layer,FC):神经元的个数为 84。
全连接层(Fully Connected layer,FC):神经元的个数为10,也就是类别数。
二、AlexNet
0、资料
论文:《ImageNet Classification with Deep Convolutional Neural Networks》
参考资料:深入理解AlexNet网络
论文中提到:
(1)ReLU Nonlinearity(Rectified Linear Unit):ReLU激活函数要比tanh激活函数收敛要快。
(2)Local Response Normalization((局部响应归一化)):ReLU激活函数得到的值域没有一个区间,所以要对ReLU得到的结果进行归一化
(3)Overlapping Pooling(覆盖的池化操作):如果 stride < pool_size, 那么就会产生覆盖的池化操作,这种有点类似于convolutional化的操作,这样可以得到更准确的结果。论文中说,在训练模型过程中,覆盖的池化层更不容易过拟合。
(4)f防止过拟合的方法:数据增强和Dropout
1、模型结构

其实简单来说,就是5层Conv,三层的全连接层。

这个图对应下面的代码,之所有只有一个全连接层,是因为分类类别较少。
2、模型代码
# -*-coding:utf-8-*-
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.fc = nn.Linear(256, num_classes)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
from torchsummary import summary
# #d打印网络结构及参数和输出形状
net = AlexNet(10)
summary(net, input_size=(3, 32, 32)) #summary(net,(3,250,250))3、模型参数

三、VGG
0、资料
论文:《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》
参考资料:深度学习VGG模型核心拆解
(1)与AlexNet的不同:增加网络的深度,然后VGG全部采用卷积核的尺寸打下为3*3,2个3*3的卷积层连接,就达到了5*5的效果,相当于可以减少参数。这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
1、模型结构

2、模型代码
import torch
import torch.nn as nn
import torchvision
def Conv3x3BNReLU(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
class VGGNet(nn.Module):
def __init__(self, block_nums,num_classes=1000):
super(VGGNet, self).__init__()
self.stage1 = self._make_layers(in_channels=3, out_channels=64, block_num=block_nums[0])
self.stage2 = self._make_layers(in_channels=64, out_channels=128, block_num=block_nums[1])
self.stage3 = self._make_layers(in_channels=128, out_channels=256, block_num=block_nums[2])
self.stage4 = self._make_layers(in_channels=256, out_channels=512, block_num=block_nums[3])
self.stage5 = self._make_layers(in_channels=512, out_channels=512, block_num=block_nums[4])
self.classifier = nn.Sequential(
nn.Linear(in_features=512*7*7,out_features=4096),
nn.ReLU6(inplace=True),
nn.Dropout(p=0.2),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU6(inplace=True),
nn.Dropout(p=0.2),
nn.Linear(in_features=4096, out_features=num_classes)
)
def _make_layers(self, in_channels, out_channels, block_num):
layers = []
layers.append(Conv3x3BNReLU(in_channels,out_channels))
for i in range(1,block_num):
layers.append(Conv3x3BNReLU(out_channels,out_channels))
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.stage5(x)
x = x.view(x.size(0),-1)
out = self.classifier(x)
return out
def VGG16():
block_nums = [2, 2, 3, 3, 3]
model = VGGNet(block_nums)
return model
def VGG19():
block_nums = [2, 2, 4, 4, 4]
model = VGGNet(block_nums)
return model
from torchsummary import summary
# #d打印网络结构及参数和输出形状
net = VGG16()
summary(net, input_size=(3, 244, 244)) #summary(net,(3,250,250))
四、GoogleNet
0、资料
googlenet和vgg是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper。跟vgg不同的是,googlenet做了更大胆的网络上的尝试而不是像vgg继承了lenet以及alexnet的一些框架,该模型虽然 有22层,但大小却比alexnet和vgg都小很多,性能优越。
论文:《Going deeper with convolutions》
论文:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
论文:《Rethinking the Inception Architecture for Computer Vision》
论文:《Rethinking the Inception Architecture for Computer Vision》
参考资料:GoogLeNet论文笔记 深度学习经典卷积神经网络之GoogLeNet(Google Inception Net)
深入浅出——网络模型中Inception的作用与结构全解析 大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进)
GoogLeNet和Inception v1、v2、v3、v4网络介绍
(1)宽度:增加了多种核 1x1,3x3,5x5,还有直接max pooling的,但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。
(2)深度:层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,googlenet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
1、模型结构
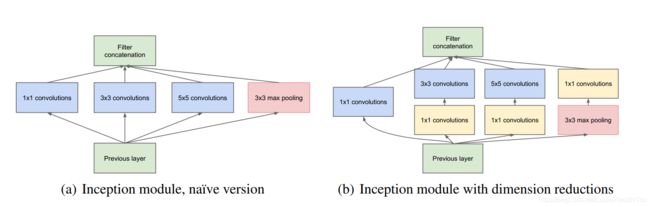
2、模型代码
'''GoogLeNet with PyTorch.'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class Inception(nn.Module):
def __init__(self, in_planes, n1x1, n3x3red, n3x3, n5x5red, n5x5, pool_planes):
super(Inception, self).__init__()
# 1x1 conv branch
self.b1 = nn.Sequential(
nn.Conv2d(in_planes, n1x1, kernel_size=1),
nn.BatchNorm2d(n1x1),
nn.ReLU(True),
)
#Inception(192, 64, 96, 128, 16, 32, 32)
# 1x1 conv -> 3x3 conv branch
self.b2 = nn.Sequential(
nn.Conv2d(in_planes, n3x3red, kernel_size=1),
nn.BatchNorm2d(n3x3red),
nn.ReLU(True),
nn.Conv2d(n3x3red, n3x3, kernel_size=3, padding=1),
nn.BatchNorm2d(n3x3),
nn.ReLU(True),
)
# 1x1 conv -> 5x5 conv branch
self.b3 = nn.Sequential(
nn.Conv2d(in_planes, n5x5red, kernel_size=1),
nn.BatchNorm2d(n5x5red),
nn.ReLU(True),
nn.Conv2d(n5x5red, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5),
nn.ReLU(True),
nn.Conv2d(n5x5, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5),
nn.ReLU(True),
)
# 3x3 pool -> 1x1 conv branch
self.b4 = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
nn.Conv2d(in_planes, pool_planes, kernel_size=1),
nn.BatchNorm2d(pool_planes),
nn.ReLU(True),
)
def forward(self, x):
y1 = self.b1(x)
y2 = self.b2(x)
y3 = self.b3(x)
y4 = self.b4(x)
return torch.cat([y1,y2,y3,y4], 1)
class GoogLeNet(nn.Module):
def __init__(self):
super(GoogLeNet, self).__init__()
self.pre_layers = nn.Sequential(
nn.Conv2d(3, 192, kernel_size=3, padding=1),
nn.BatchNorm2d(192),
nn.ReLU(True),
)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AvgPool2d(8, stride=1)
self.linear = nn.Linear(1024, 10)
def forward(self, x):
out = self.pre_layers(x)
out = self.a3(out)
out = self.b3(out)
out = self.maxpool(out)
out = self.a4(out)
out = self.b4(out)
out = self.c4(out)
out = self.d4(out)
out = self.e4(out)
out = self.maxpool(out)
out = self.a5(out)
out = self.b5(out)
out = self.avgpool(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
from torchsummary import summary
# #d打印网络结构及参数和输出形状
net = GoogLeNet()
summary(net, input_size=(3, 32, 32)) #summary(net,(3,250,250))
3、模型参数

五、ResNet
0、资料
论文:《Deep Residual Learning for Image Recognition》
资料:深度残差网络—ResNet总结
1、网络结构



2、模型代码
'''ResNet in PyTorch.'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2,2,2,2])
def ResNet34():
return ResNet(BasicBlock, [3,4,6,3])
def ResNet50():
return ResNet(Bottleneck, [3,4,6,3])
def ResNet101():
return ResNet(Bottleneck, [3,4,23,3])
def ResNet152():
return ResNet(Bottleneck, [3,8,36,3])
def test():
net = ResNet18()
print(net)
#y = net(torch.randn(1,3,32,32))
#print(y.size())
test()3、模型参数
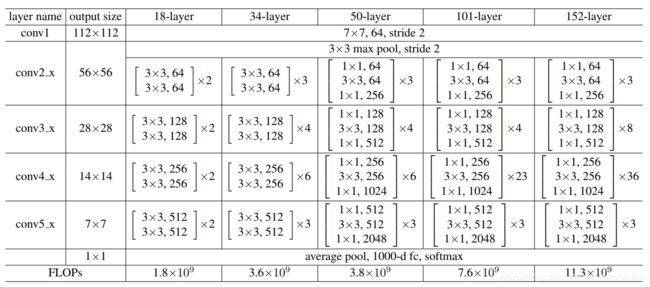
六、ResNeXt
0、资料
论文:《Aggregated Residual Transformations for Deep Neural Networks》
参考:经典分类CNN模型系列其八:ResNeXt
1、模型结构



2、模型代码
'''ResNeXt in PyTorch.
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class Block(nn.Module):
'''Grouped convolution block.'''
expansion = 2
def __init__(self, in_planes, cardinality=32, bottleneck_width=4, stride=1):
super(Block, self).__init__()
group_width = cardinality * bottleneck_width
self.conv1 = nn.Conv2d(in_planes, group_width, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(group_width)
self.conv2 = nn.Conv2d(group_width, group_width, kernel_size=3, stride=stride, padding=1, groups=cardinality, bias=False)
self.bn2 = nn.BatchNorm2d(group_width)
self.conv3 = nn.Conv2d(group_width, self.expansion*group_width, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*group_width)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*group_width:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*group_width, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*group_width)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNeXt(nn.Module):
def __init__(self, num_blocks, cardinality, bottleneck_width, num_classes=10):
super(ResNeXt, self).__init__()
self.cardinality = cardinality
self.bottleneck_width = bottleneck_width
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(num_blocks[0], 1)
self.layer2 = self._make_layer(num_blocks[1], 2)
self.layer3 = self._make_layer(num_blocks[2], 2)
# self.layer4 = self._make_layer(num_blocks[3], 2)
self.linear = nn.Linear(cardinality*bottleneck_width*8, num_classes)
def _make_layer(self, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(Block(self.in_planes, self.cardinality, self.bottleneck_width, stride))
self.in_planes = Block.expansion * self.cardinality * self.bottleneck_width
# Increase bottleneck_width by 2 after each stage.
self.bottleneck_width *= 2
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
# out = self.layer4(out)
out = F.avg_pool2d(out, 8)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNeXt29_2x64d():
return ResNeXt(num_blocks=[3,3,3], cardinality=2, bottleneck_width=64)
def ResNeXt29_4x64d():
return ResNeXt(num_blocks=[3,3,3], cardinality=4, bottleneck_width=64)
def ResNeXt29_8x64d():
return ResNeXt(num_blocks=[3,3,3], cardinality=8, bottleneck_width=64)
def ResNeXt29_32x4d():
return ResNeXt(num_blocks=[3,3,3], cardinality=32, bottleneck_width=4)
def test_resnext():
net = ResNeXt29_2x64d()
x = torch.randn(1,3,32,32)
y = net(x)
print(y.size())
# test_resnext()
3、模型参数
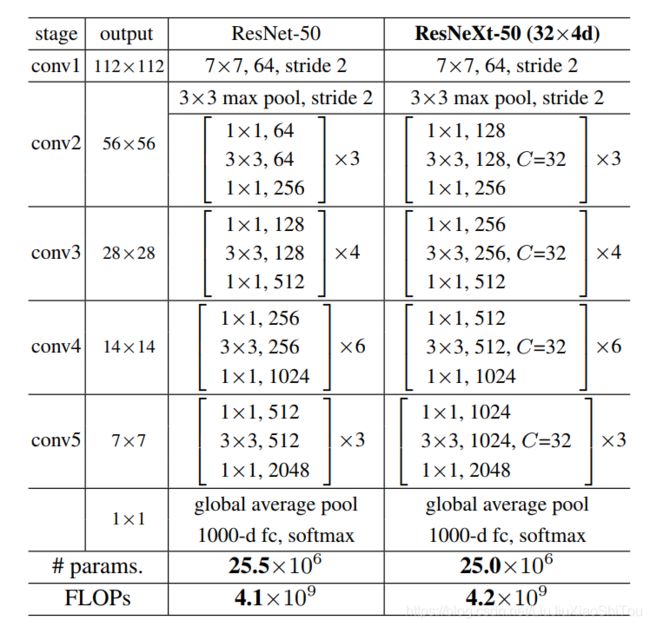
七、DenseNet
0、资料
论文:《Densely Connected Convolutional Networks》
参考:DenseNet:密集连接卷积网络
1、模型结构


2、模型代码
'''DenseNet in PyTorch.'''
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class Bottleneck(nn.Module):
def __init__(self, in_planes, growth_rate):
super(Bottleneck, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv1 = nn.Conv2d(in_planes, 4*growth_rate, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(4*growth_rate)
self.conv2 = nn.Conv2d(4*growth_rate, growth_rate, kernel_size=3, padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = torch.cat([out,x], 1)
return out
class Transition(nn.Module):
def __init__(self, in_planes, out_planes):
super(Transition, self).__init__()
self.bn = nn.BatchNorm2d(in_planes)
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=1, bias=False)
def forward(self, x):
out = self.conv(F.relu(self.bn(x)))
out = F.avg_pool2d(out, 2)
return out
class DenseNet(nn.Module):
def __init__(self, block, nblocks, growth_rate=12, reduction=0.5, num_classes=10):
super(DenseNet, self).__init__()
self.growth_rate = growth_rate
num_planes = 2*growth_rate
self.conv1 = nn.Conv2d(3, num_planes, kernel_size=3, padding=1, bias=False)
self.dense1 = self._make_dense_layers(block, num_planes, nblocks[0])
num_planes += nblocks[0]*growth_rate
out_planes = int(math.floor(num_planes*reduction))
self.trans1 = Transition(num_planes, out_planes)
num_planes = out_planes
self.dense2 = self._make_dense_layers(block, num_planes, nblocks[1])
num_planes += nblocks[1]*growth_rate
out_planes = int(math.floor(num_planes*reduction))
self.trans2 = Transition(num_planes, out_planes)
num_planes = out_planes
self.dense3 = self._make_dense_layers(block, num_planes, nblocks[2])
num_planes += nblocks[2]*growth_rate
out_planes = int(math.floor(num_planes*reduction))
self.trans3 = Transition(num_planes, out_planes)
num_planes = out_planes
self.dense4 = self._make_dense_layers(block, num_planes, nblocks[3])
num_planes += nblocks[3]*growth_rate
self.bn = nn.BatchNorm2d(num_planes)
self.linear = nn.Linear(num_planes, num_classes)
def _make_dense_layers(self, block, in_planes, nblock):
layers = []
for i in range(nblock):
layers.append(block(in_planes, self.growth_rate))
in_planes += self.growth_rate
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.trans1(self.dense1(out))
out = self.trans2(self.dense2(out))
out = self.trans3(self.dense3(out))
out = self.dense4(out)
out = F.avg_pool2d(F.relu(self.bn(out)), 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def DenseNet121():
return DenseNet(Bottleneck, [6,12,24,16], growth_rate=32)
def DenseNet169():
return DenseNet(Bottleneck, [6,12,32,32], growth_rate=32)
def DenseNet201():
return DenseNet(Bottleneck, [6,12,48,32], growth_rate=32)
def DenseNet161():
return DenseNet(Bottleneck, [6,12,36,24], growth_rate=48)
def densenet_cifar():
return DenseNet(Bottleneck, [6,12,24,16], growth_rate=12)
from torchsummary import summary
# #d打印网络结构及参数和输出形状
net = DenseNet121()
summary(net, input_size=(3, 32, 32)) #summary(net,(3,250,250))八、ShuffleNet V1 与ShuffleNet V2
0、资料
论文:《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices》
论文:《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design》
参考:『高性能模型』轻量级网络ShuffleNet_v1及v2
1、模型结构

2、shuffleNet v2 模型代码
'''ShuffleNetV2 in PyTorch.
See the paper "ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design" for more details.
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class ShuffleBlock(nn.Module):
def __init__(self, groups=2):
super(ShuffleBlock, self).__init__()
self.groups = groups
def forward(self, x):
'''Channel shuffle: [N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,w] -> [N,C,H,W]'''
N, C, H, W = x.size()
g = self.groups
return x.view(N, g, C//g, H, W).permute(0, 2, 1, 3, 4).reshape(N, C, H, W)
class SplitBlock(nn.Module):
def __init__(self, ratio):
super(SplitBlock, self).__init__()
self.ratio = ratio
def forward(self, x):
c = int(x.size(1) * self.ratio)
return x[:, :c, :, :], x[:, c:, :, :]
class BasicBlock(nn.Module):
def __init__(self, in_channels, split_ratio=0.5):
super(BasicBlock, self).__init__()
self.split = SplitBlock(split_ratio)
in_channels = int(in_channels * split_ratio)
self.conv1 = nn.Conv2d(in_channels, in_channels,
kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv2 = nn.Conv2d(in_channels, in_channels,
kernel_size=3, stride=1, padding=1, groups=in_channels, bias=False)
self.bn2 = nn.BatchNorm2d(in_channels)
self.conv3 = nn.Conv2d(in_channels, in_channels,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(in_channels)
self.shuffle = ShuffleBlock()
def forward(self, x):
x1, x2 = self.split(x)
out = F.relu(self.bn1(self.conv1(x2)))
out = self.bn2(self.conv2(out))
out = F.relu(self.bn3(self.conv3(out)))
out = torch.cat([x1, out], 1)
out = self.shuffle(out)
return out
class DownBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(DownBlock, self).__init__()
mid_channels = out_channels // 2
# left
self.conv1 = nn.Conv2d(in_channels, in_channels,
kernel_size=3, stride=2, padding=1, groups=in_channels, bias=False)
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv2 = nn.Conv2d(in_channels, mid_channels,
kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(mid_channels)
# right
self.conv3 = nn.Conv2d(in_channels, mid_channels,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(mid_channels)
self.conv4 = nn.Conv2d(mid_channels, mid_channels,
kernel_size=3, stride=2, padding=1, groups=mid_channels, bias=False)
self.bn4 = nn.BatchNorm2d(mid_channels)
self.conv5 = nn.Conv2d(mid_channels, mid_channels,
kernel_size=1, bias=False)
self.bn5 = nn.BatchNorm2d(mid_channels)
self.shuffle = ShuffleBlock()
def forward(self, x):
# left
out1 = self.bn1(self.conv1(x))
out1 = F.relu(self.bn2(self.conv2(out1)))
# right
out2 = F.relu(self.bn3(self.conv3(x)))
out2 = self.bn4(self.conv4(out2))
out2 = F.relu(self.bn5(self.conv5(out2)))
# concat
out = torch.cat([out1, out2], 1)
out = self.shuffle(out)
return out
class ShuffleNetV2(nn.Module):
def __init__(self, net_size):
super(ShuffleNetV2, self).__init__()
out_channels = configs[net_size]['out_channels']
num_blocks = configs[net_size]['num_blocks']
self.conv1 = nn.Conv2d(3, 24, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(24)
self.in_channels = 24
self.layer1 = self._make_layer(out_channels[0], num_blocks[0])
self.layer2 = self._make_layer(out_channels[1], num_blocks[1])
self.layer3 = self._make_layer(out_channels[2], num_blocks[2])
self.conv2 = nn.Conv2d(out_channels[2], out_channels[3],
kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels[3])
self.linear = nn.Linear(out_channels[3], 10)
def _make_layer(self, out_channels, num_blocks):
layers = [DownBlock(self.in_channels, out_channels)]
for i in range(num_blocks):
layers.append(BasicBlock(out_channels))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
# out = F.max_pool2d(out, 3, stride=2, padding=1)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.relu(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
configs = {
0.5: {
'out_channels': (48, 96, 192, 1024),
'num_blocks': (3, 7, 3)
},
1: {
'out_channels': (116, 232, 464, 1024),
'num_blocks': (3, 7, 3)
},
1.5: {
'out_channels': (176, 352, 704, 1024),
'num_blocks': (3, 7, 3)
},
2: {
'out_channels': (224, 488, 976, 2048),
'num_blocks': (3, 7, 3)
}
}
def test():
net = ShuffleNetV2(net_size=0.5)
x = torch.randn(3, 3, 32, 32)
y = net(x)
print(y.shape)
# test()九、Pre-activation ResNet
0、资料
论文:《Identity Mappings in Deep Residual Networks》
参考:解密ResNet:Identity Mappings in Deep Residual Networks论文笔记
1、模型结构



2、模型代码
'''Pre-activation ResNet in PyTorch.
Reference:
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
Identity Mappings in Deep Residual Networks. arXiv:1603.05027
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class PreActBlock(nn.Module):
'''Pre-activation version of the BasicBlock.'''
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(PreActBlock, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False)
)
def forward(self, x):
out = F.relu(self.bn1(x))
shortcut = self.shortcut(out) if hasattr(self, 'shortcut') else x
out = self.conv1(out)
out = self.conv2(F.relu(self.bn2(out)))
out += shortcut
return out
class PreActBottleneck(nn.Module):
'''Pre-activation version of the original Bottleneck module.'''
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(PreActBottleneck, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False)
)
def forward(self, x):
out = F.relu(self.bn1(x))
shortcut = self.shortcut(out) if hasattr(self, 'shortcut') else x
out = self.conv1(out)
out = self.conv2(F.relu(self.bn2(out)))
out = self.conv3(F.relu(self.bn3(out)))
out += shortcut
return out
class PreActResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(PreActResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def PreActResNet18():
return PreActResNet(PreActBlock, [2,2,2,2])
def PreActResNet34():
return PreActResNet(PreActBlock, [3,4,6,3])
def PreActResNet50():
return PreActResNet(PreActBottleneck, [3,4,6,3])
def PreActResNet101():
return PreActResNet(PreActBottleneck, [3,4,23,3])
def PreActResNet152():
return PreActResNet(PreActBottleneck, [3,8,36,3])
def test():
net = PreActResNet18()
y = net((torch.randn(1,3,32,32)))
print(y.size())
# test()
十、EfficientNet
0、资料
论文:《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》
参考:EfficientNet论文解读
1、模型结构
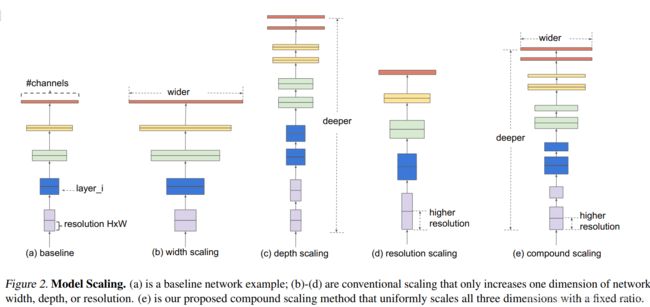
2、模型代码
'''EfficientNet in PyTorch.
Paper: "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks".
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class Block(nn.Module):
'''expand + depthwise + pointwise + squeeze-excitation'''
def __init__(self, in_planes, out_planes, expansion, stride):
super(Block, self).__init__()
self.stride = stride
planes = expansion * in_planes
self.conv1 = nn.Conv2d(
in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=stride, padding=1, groups=planes, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(
planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
self.shortcut = nn.Sequential()
if stride == 1 and in_planes != out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_planes),
)
# SE layers
self.fc1 = nn.Conv2d(out_planes, out_planes//16, kernel_size=1)
self.fc2 = nn.Conv2d(out_planes//16, out_planes, kernel_size=1)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
shortcut = self.shortcut(x) if self.stride == 1 else out
# Squeeze-Excitation
w = F.avg_pool2d(out, out.size(2))
w = F.relu(self.fc1(w))
w = self.fc2(w).sigmoid()
out = out * w + shortcut
return out
class EfficientNet(nn.Module):
def __init__(self, cfg, num_classes=10):
super(EfficientNet, self).__init__()
self.cfg = cfg
self.conv1 = nn.Conv2d(3, 32, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(cfg[-1][1], num_classes)
def _make_layers(self, in_planes):
layers = []
for expansion, out_planes, num_blocks, stride in self.cfg:
strides = [stride] + [1]*(num_blocks-1)
for stride in strides:
layers.append(Block(in_planes, out_planes, expansion, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def EfficientNetB0():
# (expansion, out_planes, num_blocks, stride)
cfg = [(1, 16, 1, 2),
(6, 24, 2, 1),
(6, 40, 2, 2),
(6, 80, 3, 2),
(6, 112, 3, 1),
(6, 192, 4, 2),
(6, 320, 1, 2)]
return EfficientNet(cfg)
def test():
net = EfficientNetB0()
x = torch.randn(2, 3, 32, 32)
y = net(x)
print(y.shape)
# test()