Redis系列(三):缓存过期该如何剔除?RDB和AOF又是什么?

作者:z小赵
★一枚用心坚持写原创的“无趣”程序猿,在自身受益的同时也让朋友们在技术上有所提升。
前言
相信很多朋友和我一样,平时工作中经常用到 Redis 的过期特性,还有通过 RDB 和 AOF 文件恢复数据,但是它们是如何工作的,本文就来介绍一下;通过了解底层实现原理,从而更好的整体把控系统的正常运行。
目录
Redis 的缓存过期策略
RDB 的实现原理
AOF 的实现原理
Redis 的缓存过期策略
常见的缓存过期策略大概有如下几种:
定时剔除策略
定期剔除策略
惰性剔除策略
定时剔除策略
定时剔除是指在 Redis 后台启动一些定时任务,每隔一段时间会触发定时任务,然后由定时任务去扫描设置了过期时间的 key,一旦发现过期就会立即从内存中剔除。其执行流程大概如下所示:
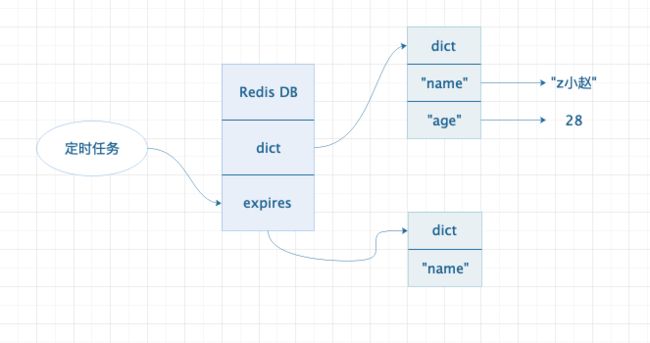 定时剔除流程图
定时剔除流程图
dict:用于存储 Redis 数据库中所有的 key,所以可以理解成 Redis 是由一个大字典组成的。
expires:用于存储所有设置了过期时间的 key。
从图中可以看出,每次定时任务执行的时候,都会遍历 expires 中的所有 key 并判断 key 是否已经过期,若过期则将其从 expires 中剔除,同时将其从 dict 中的 key-value 也删除。
从流程图中可以看出,如果在同一时间过期的 key 特别多时,此时 CPU 一直忙于清理过期的 key,从而造成 Redis 服务的卡顿;但是使用此种清除策略可以做到尽早的过期的 key 从内存中剔除,而不会造成过期 key 遗留在内存。
定期剔除策略
定期剔除与定时剔除不同的是,每隔一段时间会执行一次检查操作,而每次检查时间最长为 25ms(假设每次执行周期为 25ms),在 25ms 内,每次采用贪心算法随机从 expires 中挑选一些 key 查看是否已经过期,如果已过期则从 Redis 中删除。
此种策略的好处是不会长时间占用 CPU,但是一些过期的 key 不会立马被删除,但随着时间点的推移,所有设置了过期时间的 key 都会被遍历一遍,最终还是可以被剔除掉。
惰性剔除策略
惰性剔除是指 key 到了过期时间,但还是"赖在"缓存中不被剔除,只有 key 发生读写操作的时候,才会检查当前 key 是否已经过期,如果过期了则将 key 从缓存中剔除,反之则对 key 进行正常的读写操作。基本操作流程如下:
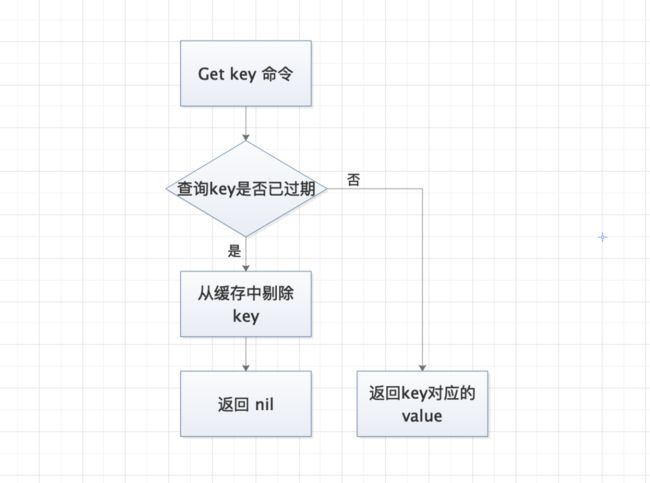 惰性剔除流程图
惰性剔除流程图
关于惰性剔除策略的几点思考
从流程图可以看出,key 过期后并不会立即被剔除,而只有 key 被使用时才会检测是否应该被剔除,此种方式剔除的好处是降低了 CPU 的压力。
惰性剔除既然是只有 key 在被使用时才会剔除,那么如果某些 key 一直不被用到的话,那么就会在内存中常驻,从而在一定程度上浪费了内存。
对了了以上三种过期 key 的清理策略后,最终 Redis 采用了定期剔除和惰性剔除两种策略相结合的方式对过期的 key 进行剔除操作。一方面可以避免 CPU 的长时间占用导致卡顿的问题,另外一方面可以防止过期 key 长时间无法剔除的问题。
RDB 的实现原理
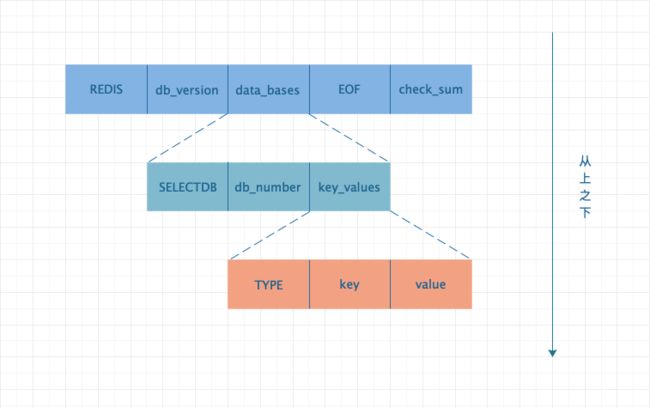 RDB文件构成图
RDB文件构成图
各部分组成说明
REDIS:常量,表示 RDB 文件的开头。
db_version:表示 RDB 文件的版本号。
EOF:表示 RDB 文件解析结束的位置表示。
check_num:校验和,通过前四部分计算得出的一个数值,当 RDB 文件被解析完成后得到的值与此值相比较,以此来判断解析 RDB 文件是否正常。
data_bases:表示数据库,用于存储实际数据的,data_bases 实际是由多个数据库组成,比如 0 号库和 2 号库里面都有数据,那么它表示两个库的数据。
TYPE:表示 value 的类型,比如字符串类型,List 类型,Set 类型等等。
key:表示 key 的内容,其一直是字符串类型。
value:表示值的内容,通过 Type 指定的类型,选择相应的解析方式来解析 value 中的值。
SELECTDB:表示开始选择数据库的标识。
db_number:表示当前数据要被恢复到那个数据库中,比如 db_number 为 2 时,则执行 select 命令,将库切到 2 号库中,然后将后续的数据写入到 2 号中。
key_values:表示存储的键值对
通过上述简要分析后可以大概了解到 RDB 文件是怎么构成的,通过相应的标识判断接下来的部分内容应该使用何种解析方式来解析。接下来我们来看看常见的几种类型的 value 组成结构长什么样子。
String 在 RDB 文件中的结构
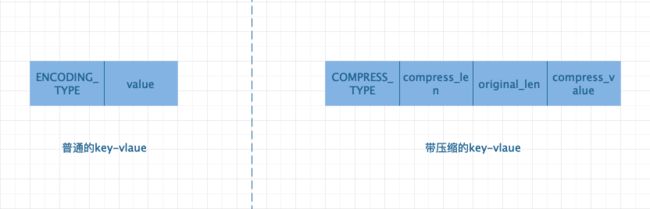
左侧为普通的不带压缩的 value 在 RDB 文件中的展现形式,右侧为带压缩的 value 在 RDB 文件中的展现形式。
List 在 RDB 文件中的结构

list_length:表示 list 中的元素个数。
value_length:表示接下来的 value 的长度是多少。
value:表示实际存储的 value 的内容是什么。
关于 SET、ZSET 和 HASH 等在 RDB 文件中的存储结构和 List 基本上大同小异,所以在这里就不在展开了,感兴趣的朋友自行百度研究下。
AOF 的实现原理
AOF(Append Only File)是以写命令追加写入文件的方式来记录 Redis 中存储的数据,当 Redis 重启时,通过解析 AOF 文件即可将数据重新写入内存中。
AOF 文件写入流程
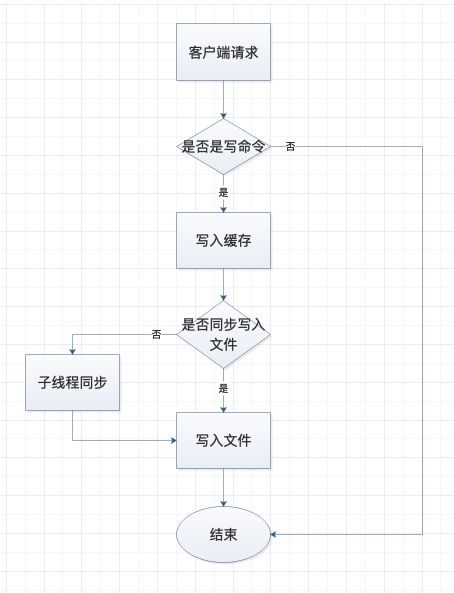 AOF写入流程图
AOF写入流程图
关于流程图的几点说明
只有写命令才会被追加到 AOF 文件中。
写命令是否同步追加到 AOF 文件中是由 appendfync 参数决定的,而 appendfync 可以配置三种情况,分别如下:
appendfync=always:表示每条写命令在被写入缓存 buffer 后,同时由该线程将命令追加写入到 AOF 文件中,此种做法最多只会有一条命令丢失的风险,但是由于由同一条线程进行操作,会导致该线程工作内容过多,从而使得处理写操作 QPS 相对比较低。
appendfync=everysce:表示写操作只需要将写命令写入缓存中,该工作线程的任务就算完成了,然后子线程会每隔一秒将缓存中的命令追加到 AOF 文件中,此种做法在一定程度上提高了写入的 QPS,但同时可能会丢失 1 秒内的写命令。
appendfync=no:表示写操作线程只需要将写命令写入缓存中,至于缓存中的写命令是什么时候被追加到 AOF 文件中,完全取决于操作系统,这种做法会使得写命令丢失的概率大大增加。
写命令不断的被追加到 AOF 文件中,当写入速度增加时,势必会导致 AOF 快速变大,有可能会导致磁盘空间被大大占用,同时也增加了 AOF 文件恢复数据的时间,Redis 官方通过使用子进程的方式重写 AOF 文件,使得 AOF 文件减小。具体流程如下: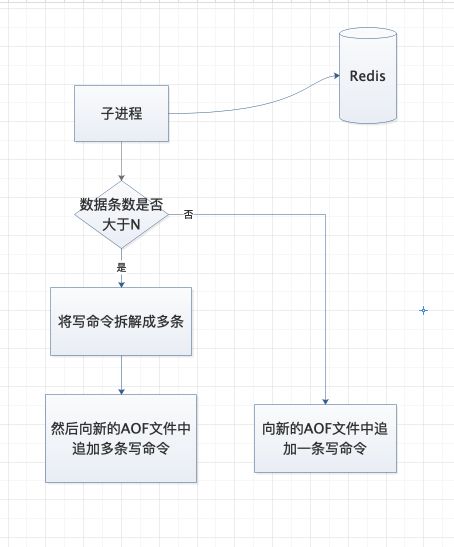
重写数据不一致的问题
如果子进程正在重写 AOF 文件的时候,有新的写命令进来的时候,则势必会造成通过 AOF 文件恢复的数据与当前 Redis 数据库中的数据不一致的问题。举个例子。
子进程从数据库中读取 'key1' 对应的值为 'value1'。
在子进程准备将 set 'key1' 'value1' 命令追加到 AOF 文件中时,此时来了一条写命令 set 'key1' 'value2',将 'key1'对应的值修改成了 'vlaue2',但 AOF 文件中实际追加的命令对应的值为 'value1'。这就造成了数据不一致的问题。
那么该怎么解决呢?看下图: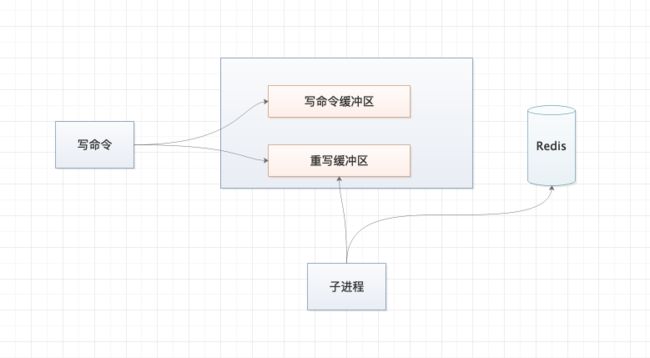
在数据写入的时候,同时将写命令在重写缓冲区中写人一份,然后在重写 AOF 文件的时候,将 Redis 中读取的数据和重写缓冲区的数据进行合并之后,然后在写入到重写的 AOF 文件中。
总结
本篇文章讲解了 Redis 过期 key 的剔除策略,其采用了定期剔除和惰性剔除两种相结合的方式剔除过期 key;然后讲解了 RDB 文件内容的存储格式,通过了解数据的存储方式,可以更加清晰地理解 RDB 文件的数据恢复方式;最后讲解了 AOF 文件的实现原理,从而更加清晰地理解通过 AOF 文件如何进行数据恢复操作。
下篇文章我们来讲讲生产环境中集群是怎么工作的,敬请期待。

系统研发工程师、z小赵
高并发设计 | 大数据 | 架构设计
往期推荐
Kafka系列10:面试题是否有必要深入了解其背后的原理?我觉得应该刨根究底(下)
Kafka系列9:面试题是否有必要深入了解其背后的原理?我觉得应该刨根究底(上)
Kafka:你必须要知道集群内部工作原理的一些事!
消息是如何在服务端存储与读取的,你真的知道吗?
一文读懂消费者背后的那点"猫腻"
感谢您的【在看】和【转发】支持