Flink如何实现动态表与静态表的Join操作
问题介绍
动态表(以下简称流表)是Flink Table API & SQL 模块中的一个核心概念,

Dynamic tables are the core concept of Flink’s Table API and SQL support for streaming data. In contrast to the static tables that represent batch data, dynamic table are changing over time.
当前Flink版本(1.5),Table API与SQL都只支持流表与流表之间的Join操作,
Table left = tableEnv.fromDataStream(ds1, "a, b, c");
Table right = tableEnv.fromDataStream(ds2, "d, e, f");
Table result = left.join(right).where("a = d").select("a, b, e");
然而很多业务场景都需要流表与静态表之间的Join,这里的静态表可以看作是数据仓库中的维度表。
UDTF实现
对于不支持流表与静态表Join这个问题,有人在Flink邮件组里提问过,社区给出的解决方案是通过UDTF来实现。
// The generic type "Tuple2" determines the schema of the returned table as (String, Integer).
public class Split extends TableFunction<Tuple2<String, Integer>> {
private String separator = " ";
public Split(String separator) {
this.separator = separator;
}
public void eval(String str) {
for (String s : str.split(separator)) {
// use collect(...) to emit a row
collect(new Tuple2<String, Integer>(s, s.length()));
}
}
}
BatchTableEnvironment tableEnv = TableEnvironment.getTableEnvironment(env);
Table myTable = ... // table schema: [a: String]
// Register the function.
tableEnv.registerFunction("split", new Split("#"));
// Use the table function in the Java Table API. "as" specifies the field names of the table.
myTable.join("split(a) as (word, length)").select("a, word, length");
myTable.leftOuterJoin("split(a) as (word, length)").select("a, word, length");
// Use the table function in SQL with LATERAL and TABLE keywords.
// CROSS JOIN a table function (equivalent to "join" in Table API).
tableEnv.sqlQuery("SELECT a, word, length FROM MyTable, LATERAL TABLE(split(a)) as T(word, length)");
// LEFT JOIN a table function (equivalent to "leftOuterJoin" in Table API).
tableEnv.sqlQuery("SELECT a, word, length FROM MyTable LEFT JOIN LATERAL TABLE(split(a)) as T(word, length) ON TRUE");
这种方案最大的问题就是缺少灵活性。对于不同的Join字段,不同的过滤条件,不同的查询字段都需要实现不同的eval方法,对我们来说是不可取的。因此我们决定通过修改Flink Table/SQL 模块来支持流表与静态表的Join。要知道怎么来增加这个特性,首先我们需要先了解Table/SQL的执行流程。
Flink Table/SQL 执行流程简介
Calcite逻辑计划
Flink 的 Table API & SQL 的使用分别如下:
val table: Table = orderA.unionAll(orderB)
.select('user, 'product, 'amount)
.where('amount > 2)
table.toAppendStream[Order].print()
val table: Table = tEnv.sqlQuery(
"SELECT * FROM OrderA WHERE amount > 2 " +
"UNION ALL SELECT * FROM OrderB WHERE amount < 2")
table.toAppendStream[Order].print()
可以看出来,两种方式最终都需要将Table转换成DataStream来执行。
通过查看toAppendStream方法可以知道,不管是哪种方式,都需要拿到Table对应的RelNode。RelNode是Calcite的数据结构,
A RelNode is a relational expression.
而 Table API 与 SQL 只是在获取RelNode时使用了不同的方式:
- Table API 通过使用
RelBuilder来拿到RelNode(LogicalNode与Expression分别转换成RelNode与RexNode),具体实现这里就不展开了; - SQL 则是通过使用
Planner。首先通过parse方法将用户使用的SQL文本转换成由SqlNode表示的parse tree。接着通过validate方法,使用元信息来resolve字段,确定类型,验证有效性等等。最后通过rel方法将SqlNode转换成RelNode;
通过Table拿到的RelNode是Calcite生成的逻辑计划。对于上面使用SQL的例子,下面就是生成的RelNode,
LogicalUnion(all=[true])
LogicalProject(user=[$0], product=[$1], amount=[$2])
LogicalFilter(condition=[>($2, 2)])
LogicalTableScan(table=[[OrderA]])
LogicalProject(user=[$0], product=[$1], amount=[$2])
LogicalFilter(condition=[<($2, 2)])
LogicalTableScan(table=[[OrderB]])
Flink逻辑计划与物理计划
Calcite框架允许我们使用规则来优化逻辑计划,Flink所使用的优化规则在FlinkRuleSets#LOGICAL_OPT_RULES,其中包括过滤下推,聚合下推等等。
优化后的逻辑计划是FlinkLogicalRel,上面SQL例子的Flink逻辑计划如下,
FlinkLogicalUnion(all=[true])
FlinkLogicalCalc(expr#0..2=[{inputs}], expr#3=[2], expr#4=[>($t2, $t3)], proj#0..2=[{exprs}], $condition=[$t4])
FlinkLogicalNativeTableScan(table=[[OrderA]])
FlinkLogicalCalc(expr#0..2=[{inputs}], expr#3=[2], expr#4=[<($t2, $t3)], proj#0..2=[{exprs}], $condition=[$t4])
FlinkLogicalNativeTableScan(table=[[OrderB]])
接下来需要将逻辑计划再转换成物理计划,例如Join算子,最后到底是使用哈希Join还是排序Join可以由这一步来决定的,这一步还可以做一些基于代价的优化(Cost Based Optimization)。另外,批处理与流处理的物理计划也不相同。这一步的实现依旧是通过Calcite的规则来完成,批处理的物理计划规则在FlinkRuleSets#DATASET_OPT_RULES,而流处理的在FlinkRuleSets#DATASTREAM_OPT_RULES。
/**
* RuleSet to optimize plans for stream / DataStream execution
*/
val DATASTREAM_OPT_RULES: RuleSet = RuleSets.ofList(
// translate to DataStream nodes
DataStreamSortRule.INSTANCE,
DataStreamGroupAggregateRule.INSTANCE,
DataStreamOverAggregateRule.INSTANCE,
DataStreamGroupWindowAggregateRule.INSTANCE,
DataStreamCalcRule.INSTANCE,
DataStreamScanRule.INSTANCE,
DataStreamUnionRule.INSTANCE,
DataStreamValuesRule.INSTANCE,
DataStreamCorrelateRule.INSTANCE,
DataStreamWindowJoinRule.INSTANCE,
DataStreamJoinRule.INSTANCE,
StreamTableSourceScanRule.INSTANCE
)
其中非时间窗口的Join算子(Time-windowed Join)的转换是通过DataStreamJoinRule来完成。通过代码可以看到最终是将逻辑计划FlinkLogicalJoin转换成了物理计划DataStreamJoin。
转换后的流处理与批处理的物理计划分别是DataStreamRel与DataSetRel。
RelNode,FlinkRelNode,FlinkLogicalRel,DataStreamRel及DataSetRel关系如下,
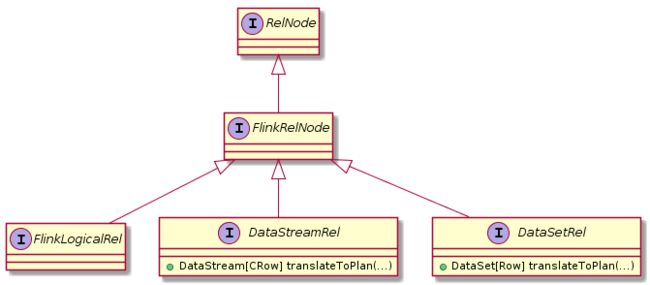
上面SQL例子的Flink物理计划如下,
DataStreamUnion(union all=[user, product, amount])
DataStreamCalc(select=[user, product, amount], where=[>(amount, 2)])
DataStreamScan(table=[[OrderA]])
DataStreamCalc(select=[user, product, amount], where=[<(amount, 2)])
DataStreamScan(table=[[OrderB]])
DataStream/DataSet API
最后需要将物理计划转换成Flink程序。通过DataStreamRel#translateToPlan与DataSetRel#translateToPlan将物理计划转换成相应的DataStream及DataSet API调用。
总结一下,Table/SQL 的执行流程大致如下图所示(官网博客的一张图,其实还不够细致):
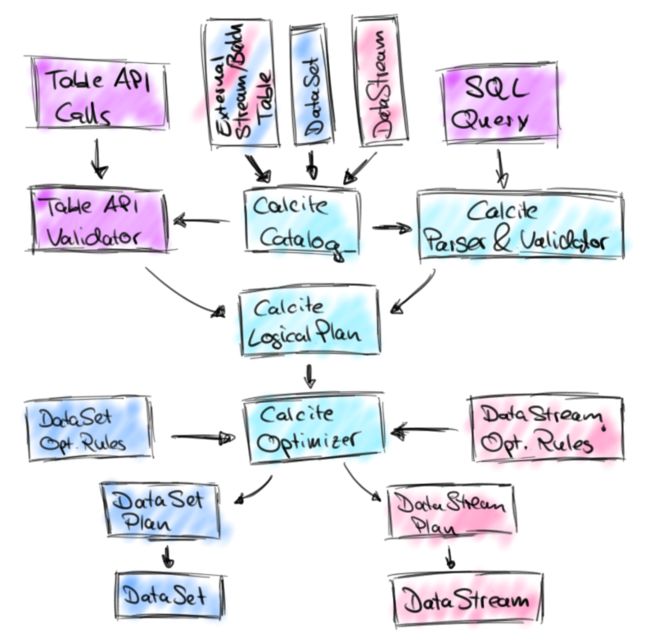
- 通过Table API或者SQL得到Calcite逻辑计划,由
RelNode表示; - 通过Calcite的规则机制优化逻辑计划,得到Flink逻辑计划,由
FlinkLogicalRel表示; - 通过Calcite的规则机制得到Flink物理计划,流处理物理计划由
DataStreamRel表示,批处理物理计划由DataSetRel表示; - 最后将物理计划转换成底层对应的DataStream/DataSet API调用;
DataStreamJoin改造
了解完Table/SQL的执行流程后,回到我们的问题上,流表与静态表的Join。上面我们已经看到流表与流表的Join最终的物理计划是DataStreamJoin,那么这里我们可以有一种实现思路,就是将我们要的静态表伪装成流表,然后在DataStreamJoin里面识别出伪装后的静态表,然后转换成相应的DataStream API调用。这里就有两个问题了,如何伪装及识别静态表?应该转换成什么样的DataStream API调用来正确的实现Join语义?
静态表伪装及识别
首先能想到的就是通过表元信息来进行伪装及识别。Calcite元信息(Schema)保存了表信息(Table),我们可以利用在TableEnvironment进行表注册的时候带上静态表信息,这样在后续的逻辑计划及物理计划都能识别到静态表的信息。
DataStream API 转换
原先流表与流表的Join,是通过DataStream#connect连接两个DataStream,然后再使用CoProcessFunction来实现Join逻辑。流表与静态表的Join,不需要进行connect,直接使用ProcessFunction,调用DataStream#process实现Join逻辑即可。
需要注意的是,如果有对静态表额外的过滤及查询(物理计划对应了DataStreamCalc节点),是需要将相关的过滤下推到ProcessFunction当中去的,否则Join的结果就是错误的。
优化
上述的实现方式,需要注意一个问题,就是性能问题。使用ProcessFunction实现Join逻辑,每收到一条流表数据就要去查找一次静态表数据,这在数据流量大的场景下是需要注意的。这里有3个优化点:
- 静态表查询异步化;
- 静态表数据缓存;
- 流表数据分区;
下面来一一说明。
异步化
异步I/O算子是Flink 1.2版本引入的一个特性,
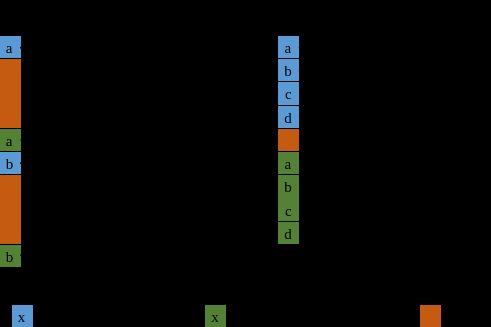
如上图所示,我们可以将算子内的I/O操作由同步改为异步,减少I/O等待时间,提升性能。这样的特性正好适用于我们对静态表的查询操作。我们所要做的就是用AsyncFunction来替代ProcessFunction。
另外,当前异步I/O算子没有提供超时处理机制,如果一个异步I/O请求超时将导致Job失败并重启,这个问题记录在FLINK-7789。某些业务场景下,这个做法是不合适的,因此我这边提交了一个PR修复了这个问题。
缓存与分区
静态表查询异步化后,还能做的一个优化便是缓存静态表数据,缓存策略根据业务需要来选择,这里就不展开了。
当使用了缓存之后,有一个优化点也需要考虑进去,就是提升缓存命中率。由于静态表是用来与流表进行Join的,也就是说静态表数据是与流表数据相关联的,通过Join所使用的字段。因此我们可以通过对流表进行按Join字段分区(通过DataStream#keyBy实现),这样在每个分区内是可以大大提高缓存命中率的。
静态表抽象
最后还需要考虑一个问题,静态表的多样性。我们可以使用MySQL或者HBase等等来充当静态表,对于静态表的查询(包括缓存优化)需要根据不同类型的表来实现。因此我们需要对静态表做一层抽象。
具体做法可以是,在通过TableEnvironment注册静态表时,指定静态表的类型,例如是MySQL表。然后在真正执行查询的AsyncFunction中根据不同的静态表类型执行不同的查询逻辑。通过JDK的ServiceLoader API可以很容易来实现。
另外,这种方式也很方便用户实现自定义的静态表类型。
这块实现的代码暂时还没开放出来,有兴趣的同学欢迎交流。
UPDATE:代码已经放到Github上面了,戳这里。
alright,今天就先到这了,have fun ^_^