Flink源码解读--FlinkKafkaProducer09
1、简介
之前介绍过FlinkKafkaConsumer09,这次来看FlinkKafkaProducer09.
最近工作中遇到,所以在这里算是做个简单的记录,内容很简单,没什么深入的东西。
2、FlinkKafkaProducer09
Flink提供了6种kafka producer方法:
FlinkKafkaProducer09(brokerList,topicId,SerializationSchema)
FlinkKafkaProducer09(topicId,SerializationSchema,producerConfig)
FlinkKafkaProducer09(topicId,SerializationSchema,producerConfig,KafkaPartitioner)
FlinkKafkaProducer09(brokerList,topicId,KeyedSerializationSchema)
FlinkKafkaProducer09(topicId,KeyedSerializationSchema,producerConfig)
FlinkKafkaProducer09(topicId,KeyedSerializationSchema,producerConfig,KafkaPartitioner)其中,前3种的SerializationSchema都通过KeyedSerializationSchemaWrapper类转换为了KeyedSerializationSchema。
@Override
public byte[] serializeKey(T element) {
return null;
}
@Override
public byte[] serializeValue(T element) {
return serializationSchema.serialize(element);
}
@Override
public String getTargetTopic(T element) {
return null; // we are never overriding the topic
}而如果指定KeyedSerializationSchema,则需要覆写如何序列化key及value。
producerConfig的配置,官方建议只设置bootstrap.servers。当然如果设置了key.serializer和value.serializer也是可以的。在处理producerConfig时,Flink也是先判断producerConfig中是否设置了这两项,如果没有设置,则默认为:ByteArraySerializer。
// set the producer configuration properties.
if (!producerConfig.contains(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG)) {
this.producerConfig.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getCanonicalName());
} else {
LOG.warn("Overwriting the '{}' is not recommended", ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
}
if (!producerConfig.contains(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG)) {
this.producerConfig.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getCanonicalName());
} else {
LOG.warn("Overwriting the '{}' is not recommended", ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
}KEY_SERIALIZER_CLASS_CONFIG对应key.serializer;
VALUE_SERIALIZER_CLASS_CONFIG对应value.serializer
如果没有指定KafkaPartitioner,则会通过FixedPartitioner来给出默认的partitioner方法:
@Override
public void open(int parallelInstanceId, int parallelInstances, int[] partitions) {
if (parallelInstanceId < 0 || parallelInstances <= 0 || partitions.length == 0) {
throw new IllegalArgumentException();
}
this.targetPartition = partitions[parallelInstanceId % partitions.length];
}
@Override
public int partition(T next, byte[] serializedKey, byte[] serializedValue, int numPartitions) {
if (targetPartition >= 0) {
return targetPartition;
} else {
throw new RuntimeException("The partitioner has not been initialized properly");
}
}下面重点说说这个默认的partitioner方法。
parallelInstanceId代表着Flink producer程序的并行度ID,假如FlinkKafkaProducer09的并行度是4,那么这4个线程的ID分别是1,2,3,4.
parallelInstances代表着总的并行度,即4.
partitions是一个kafka partition的数组,例如发送到kafka的topic的partition是12。
那么Flink到底是根据什么把数据发送到不同的partition的呢?Flink中也有个partitions的概念,说白了就是并行度,而其partition的规则,就是Flink的并行度ID除以kafka partition length取余。
继续上边的例子,当线程号为1时,1 % 12 = 1,即凡是Flink中线程号为1的发送的数据都到了kafka中编号为1的partition中;
当线程号为2时,2 % 12 = 2,即凡是Flink中线程号为2的发送的数据都到了kafka中编号为2的partition中;
当线程号为3时,3 % 12 = 3,即凡是Flink中线程号为3的发送的数据都到了kafka中编号为3的partition中。。。。。
由此我们总结出:
如果Flink的并行度小于要发送kafka topic的partition数量,则Flink线程对应kafka partition的关系如下:

如果Flink的并行度大于要发送kafka topic的partition数量,则Flink线程对应kafka partition的关系如下:
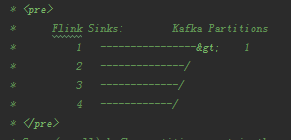
由此可见,默认的partition策略是按照Flink的并行度ID与kafka中partition的数量取余的方法分配的,而与数据本身没有关系。
如果你的partition策略不想按照Flink并行度划分,那么也可以覆写自己的customPartitioner。
最后的执行,是在FlinkKafkaProducerBase类中,检验输入的4个参数是否为空,获取key.serializer以及value.serializer。最后获取kafka中topic的partition数量,执行partition策略,调用kafka producer接口,发送数据。
public FlinkKafkaProducerBase(String defaultTopicId, KeyedSerializationSchema<IN> serializationSchema, Properties producerConfig, KafkaPartitioner<IN> customPartitioner)3、验证
我用上边producer的第5种方式,即:
FlinkKafkaProducer09(topicId,KeyedSerializationSchema,producerConfig)测试了FlinkKafkaProducer09不同的并行度时,发送到kafka中partition的情况。
先来看第一种(并行度是1,kafka中TX_TEST3的partition数为4):
txStream.addSink(new FlinkKafkaProducer09[TX]("TX_TEST3", new TransactionKeyedSerializationSchema("TX_TEST3"),props)).setParallelism(1)发送前的信息:
 。
。
发送后的信息:
 。
。
这次producer,只发送到了1个partition。
再来看第二种测试(并行度是4,kafka中TX_TEST2的partition数为4):
txStream.addSink(new FlinkKafkaProducer09[TX]("TX_TEST2", new TransactionKeyedSerializationSchema("TX_TEST2"),props)).setParallelism(4)发送前的信息:

发送后的信息:

这次producer,发送到了4个partition。
这可以看出,默认的FixedPartitioner其实是按照并行度来发送到partition的。
4、总结
Flink在向kafka produce数据时,其并行度最好大于等于要发送topic的partition数量,这样可以保证每个partition都有数据,最大化吞吐量。除非自定义partitioner。