大数据基础学习-8.Hbase-1.2.0
一、HBase基础
参考:https://blog.csdn.net/jack__cj/article/details/52634518
1.HBASE概述
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为Java,是Apache软件基金会Hadoop项目的一部分,运行于HDFS文件系统之上,因此可以容错地存储海量稀疏的数据。

上图描述了Hadoop EcoSystem中的各层系统,其中HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
2.行存储vs列存储
• 行存储:优点是写入一次性完成,保持数据完整性;缺点是数据读取过程中产生冗余数据,若只有少量数据可以忽略。
• 列存储:优点是读取过程,不会产生冗余数据,适合对数据完整性要求不高的大数据领域;缺点是写入效率差,保证数据完整性方面差。
3.HBase应用场景
对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中。
时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求。
推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上。
时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中。
CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求。
消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上。
Feeds流:典型的应用就是xx朋友圈类似的应用。
NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求。
4.HBase和Hive
Hive适合用对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive不应该用来进行实时的查询,因为它需要很长时间才可以返回结果;HBase则非常适合用来进行大数据的实时查询,例如Facebook用HBase进行消息和实时的分析。简单来说HBASE对应hdfs,而hive对应的是MapReduce,二者有着本质的区别。
对于Hive和HBase的部署来说,也有一些区别,Hive一般只要有Hadoop便可以工作。而HBase则还需要Zookeeper的帮助。再而,HBase本身只提供了Java的API接口,并不直接支持SQL的语句查询,而Hive则可以直接使用HQL。如果想要在HBase上使用SQL,则需要联合使用Apache Phonenix,或者联合使用Hive和HBase。但如果集成使用Hive查询HBase的数据,则无法绕过MapReduce,那么实时性还是有一定的损失。Phoenix加HBase的组合则不经过MapReduce的框架,因此当使用Phoneix加HBase的组成,实时性上会优于Hive加HBase的组合。默认情况下Hive和HBase的存储层都是HDFS。但是HBase在一些特殊的情况下也可以直接使用本机的文件系统。例如Ambari中的AMS服务直接在本地文件系统上运行HBase。
5.RDBMS和HBase
RDBMS使用sql语句,HBase使用API;RDBMS基于行存储,HBase基于列存储且支持更好的压缩;RDBMS适用于存储结构化数据,HBase适用于存储结构化和非结构化数据;RDBMS支持事务处理,HBase不支持事务处理;RDBMS支持多表Join,HBase不支持多表Join;RDMBS更新表数据会自动更新索引文件,HBase需要手动建立索引,手动更新;RDMBS适用于业务逻辑复杂的存储环境,HBase不适合;RDMBS不适合存储超大数据量的单表,HBase适合。
二、HBase核心
1.Hbase系统架构

从HBase的架构图上可以看出,HBase中的存储包括HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等,HBase中的每张表都通过行键(rowkey)按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
2.Client
– 访问Hbase的接口,并维护Cache加速Region Server的访问。HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC。
3.HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:– 为Region server分配region
– 负责Region server的负载均衡
– 发现失效的Region server并重新分配其上的region
– HDFS上的垃圾文件回收
– 处理schema更新请求
4.HRegion Server
处理用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
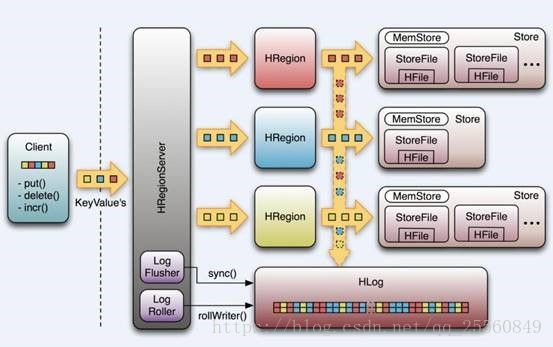
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,HRegion中由多个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。
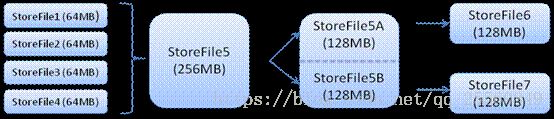
HStore存储是HBase存储的核心了,其中由两部分组成,一部分是MemStore,一部分是StoreFiles。MemStore是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。下图描述了Compaction和Split的过程:
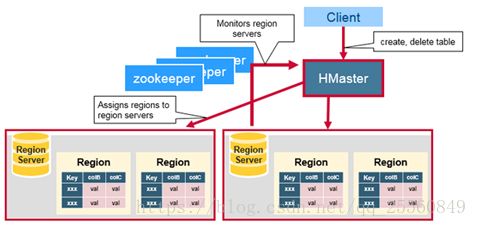
5.Zookeeper
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的单点问题。– 保证集群中只有一个Master。
– 存储所有Region的入口(ROOT)地址,其中的znode信息:
–/hbase/root-region-server ,Root region的位置
–/hbase/table/-ROOT-,根元数据信息
–/hbase/table/.META.,元数据信息
–/hbase/master,当选的Mater
– /hbase/backup-masters,备选的Master
– /hbase/rs,RegionServer的信息
–/hbase/unassigned,未分配的Region
– 实时监控Region Server的上下线信息,并通知Master。
ZooKeeper协调集群所有节点的共享信息,在HMaster和HRegionServer连接到ZooKeeper后创建Ephemeral节点,并使用Heartbeat机制维持这个节点的存活状态,如果某个Ephemeral节点实效,则HMaster会收到通知,并做相应的处理。
可以看到,client访问hbase上的数据并不需要master参与(寻址访问zookeeper和region server,数据读写访问region server),master仅仅维护table和region的元数据信息(table的元数据信息保存在zookeeper上),负载很低。
HBase内置有zookeeper,但一般我们会有其他的Zookeeper集群来监管master和regionserver,Zookeeper通过选举,保证任何时候,集群中只有一个活跃的HMaster,HMaster与HRegionServer 启动时会向ZooKeeper注册,存储所有HRegion的寻址入口,实时监控HRegionserver的上线和下线信息。并实时通知给HMaster,存储HBase的schema和table元数据,默认情况下,HBase管理ZooKeeper 实例,Zookeeper的引入使得HMaster不再是单点故障。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。如图:
6.HBase存储格式
HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,主要包括上述提出的两种文件类型:
HLog File,HBase中WAL(Write Ahead Log) 的存储格式,物理上是Hadoop的Sequence File。
在开始介绍Hfile和Hlog前,先学习HBASE的数据模型-table。
6.1table格式
1)Table & Column Family

Row Key: 行键,Table的主键,Table中的记录按照Row Key排序。与nosql数据库一样,row key是用来检索记录的主键。访问hbase table中的行,只有三种方式:
1.通过单个row key访问2.通过row key的range
3.全表扫描
Row key行键 :(Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在hbase内部,row key保存为字节数组。存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)【注意:字典序对int排序的结果是1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。要保持整形的自然序,行键必须用0作左填充。】
Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number。HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。列名都以列族作为前缀。例如courses:history,courses:math都属于courses 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因为隐私的原因不能浏览所有数据)。
Cell:由{row key, column(=
2)Table & Region
当Table随着记录数不断增加而变大后,会逐渐分裂成多份splits,成为regions,一个region由[startkey,endkey)表示,不同的region会被Master分配给相应的RegionServer进行管理。
3)两个特殊表
-ROOT- 表和.META.表是两个比较特殊的表,.META.记录了用户表的Region信息,.META.可以有多个regoin。-ROOT-记录了.META.表的Region信息,-ROOT-只有一个region,Zookeeper中记录了-ROOT-表的location。

Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过client端会做cache缓存。
【注意】
1.root region永远不会被split,保证了最多需要三次跳转,就能定位到任意region 。
2.META.表每行保存一个region的位置信息,row key 采用表名+表的最后一样编码而成。
3.为了加快访问,.META.表的全部region都保存在内存中。
假设,.META.表的一行在内存中大约占用1KB。并且每个region限制为128MB。
那么上面的三层结构可以保存的region数目为:(128MB/1KB) * (128MB/1KB) = = 2^34个region
4.client会将查询过的位置信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的region(其中三次用来发现缓存失效,另外三次用来获取位置信息)。
Hbase 0.96之后去掉了-ROOT- 表,因为:
– 三次请求才能直到用户Table真正所在的位置也是性能低下的。
– 即使去掉-ROOT- Table,也还可以支持2^17(131072)个Hregion,对于集群来说,存储空间也足够。
所以目前流程为:
– 从ZooKeeper(/hbase/meta-region-server)中获取hbase:meta的位置(HRegionServer的位置),缓存该位置信息。
– 从HRegionServer中查询用户Table对应请求的RowKey所在的HRegionServer,缓存该位置信息。
– 从查询到HRegionServer中读取Row。
6.2Hfile
下图是HFile的存储格式:

首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。正如图中所示的,Trailer中有指针指向其他数据块的起始点。File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU(Least recently used,缓存淘汰算法)的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。 每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,Magic内容就是一些随机数字,目的是防止数据损坏。HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:

开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是 RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
6.3Hlog

上图中示意了HLog文件的结构,其实HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是“写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue,可参见上文描述。
LogFlusher
前面提到,数据以KeyValue形式到达HRegionServer,将数据写入hlog之后,写入一个SequenceFile。看过去没问题,但是因为数据流在写入文件系统时,经常会缓存以提高性能。这样,有些本以为在日志文件中的数据实际在内存中。这里,我们提供了一个LogFlusher的类。它调用HLog.optionalSync(),后者根据 hbase.regionserver.optionallogflushinterval (默认是10秒),定期调用Hlog.sync()。另外,HLog.doWrite()也会根据hbase.regionserver.flushlogentries (默认100秒)定期调用Hlog.sync()。Sync() 本身调用HLog.Writer.sync(),它由SequenceFileLogWriter实现。
LogRoller
Log的切换通过$HBASE_HOME/conf/hbase-site.xml的 hbase.regionserver.logroll.period 限制,默认是一个小时。所以每60分钟,会打开一个新的log文件。久而久之,会有一大堆的文件需要维护。首先,LogRoller调用HLog.rollWriter(),定时滚动日志,之后,利用HLog.cleanOldLogs()可以清除旧的日志。它首先取得存储文件中的最大的sequence number,之后检查是否存在一个log所有的条目的“sequence number”均低于这个值,如果存在,将删除这个log。
每个region server维护一个HLog,而不是每一个region一个,这样不同region(来自不同的table)的日志会混在一起,这样做的目的是不断追加单个文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此可以提高table的写性能。带来的问题是,如果一个region server下线,为了恢复其上的region,需要讲region server上的log进行拆分,然后分发到其他region server上进行恢复。
7.HBASE容错
• Master容错:
Zookeeper重新选择一个新的Master。无Master过程中,数据读取仍照常进行,但是region切分、负载均衡等无法进行。
• Region Server容错:
定时向Zookeeper汇报心跳,如果一旦时间内未出现心跳,Master将该RegionServer上的Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer。
• Zookeeper容错:
Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例
• WAL(Write-Ahead-Log)预写日志是Hbase的RegionServer在处理数据插入和删除的过程中用来记录操作内容的一种日志,在每次Put、 Delete等一条记录时,首先将其数据写入到RegionServer对应的HLog文件的过程。
客户端往RegionServer端提交数据的时候,会写WAL日志,只有当WAL日志写成功以后,客户端才会被告诉提交数据成功,如果写WAL失败会告知客户端提交失败。数据落地的过程在一个RegionServer上的所有的Region都共享一个HLog,一次数据的提交是先写WAL,写入成功后,再写memstore。
三、HBase操作
1.安装和配置
解压安装
# tar –zxf hbase-1.2.0-cdh5.7.0 配置系统变量。
export HBASE_HOME=/usr/local/src/hbase-1.2.0-cdh5.7.0
export PATH=$PATH:$HBASE_HOME/bin配置hbase-env.sh。
export JAVA_HOME=/usr/local/src/jdk1.8.0_144
export HBASE_MANAGES_ZK=false(注:该属性让HBase使用一个已有的不被HBase托管的Zookeepr集群)配置hbase-site.xml。
hbase.rootdir
hdfs://master:9000/hbase 这里要和hadoop配置的namenode的端口对应起来
hbase.cluster.distributed
true
hbase.zookeeper.quorum
master:2181
配置regionservers。
master
slave1
slave22.启动zookeeper
# zkServer.sh start3.启动hbase
[root@master bin]# ./start-hbase.sh 查看进程会发现多了2个:hmaster和hregionserver# jps
70977 Jps
34946 NameNode
42932 QuorumPeerMain
35476 NodeManager
35045 DataNode
70423 Main
35368 ResourceManager
70875 HRegionServer
35227 SecondaryNameNode
70733 HMaster可以在浏览器,打开60010端口查看。
4.hbase shell
# hbase shell 进入shell模式1)一般操作
• 查看数据库状态(status、version)
hbase(main):001:0> status
1 active master, 0 backup masters, 1 servers, 0 dead, 3.0000 average load• 执行help查询帮助
hbase(main):001:0> help – general:普通命令组
– ddl:数据定义语言命令组
– dml:数据操作语言命令组
– tools:工具组
– replication:复制命令组
– SHELL USAGE:shell语法
2)DDL操作
• 命令create / list / describe
hbase(main):027:0> create 'student','member_id','address','info'– 表名:music_table
– 列簇1:meta_data
– 列簇2: action
hbase(main):028:0> list #列出当前创建的表hbase(main):029:0> describe 'student' #查看表的具体信息• 查看全表内容 scan
hbase(main):006:0> scan 'student'• 删除一个列族,alter,disable,enable
– 凡是要修改表的结构hbase规定,必须先禁用表->修改表->启用表,直接修改会报错
hbase(main):032:0> disable 'student'
hbase(main):030:0> alter 'student',{NAME=>'member_id',METHOD=>'delete'} 删除某个列簇
hbase(main):032:0> enable 'student'• 命令drop / exists
hbase(main):032:0> disable 'student'
hbase(main):032:0> drop 'student' #删除表,在删除前要先disable该表
hbase(main):032:0> exists 'student' #查看某个具体表是否存在• is_enabled/is_disabled
查看表格是否是disabled或者是enabled。
is_disabled 'student'3)DML操作
• 插入命令put
– 对于hbase来说insert update其实没有什么区别,都是插入原理
– 在hbase中没有数据类型概念,都是“字符类型”,至于含义在程序中体现
– 每插入一条记录都会自动建立一个时间戳,由系统自动生成。也可手动“强行指定”
hbase(main):033:0> put 'student','xll','info:age','24'
0 row(s) in 0.0480 seconds
hbase(main):034:0> put 'student','xll','info:birthday','1992.01.20'
0 row(s) in 0.0110 seconds
hbase(main):035:0> put 'student','xll','address:country','china'
0 row(s) in 0.1120 seconds
hbase(main):036:0> put 'student','xll','address:city','hanzhou'
0 row(s) in 0.0140 secondsput操作时,需要指定表名、rowkey、列簇:列名、值
• get 查看记录
hbase(main):007:0> get 'student','xll' #查看某rowkey对应的所有数据
COLUMN CELL
address:city timestamp=1527397879925, value=hanzhou
address:country timestamp=1527397866015, value=china
info:age timestamp=1527397813629, value=24
info:birthday timestamp=1527397830188, value=1992.01.20
4 row(s) in 0.0450 secondshbase(main):008:0> get 'student','xll','info' #也可以查看某列簇的数据
COLUMN CELL
info:age timestamp=1527397813629, value=24
info:birthday timestamp=1527397830188, value=1992.01.20
2 row(s) in 0.0390 secondshbase(main):009:0> get 'student','xll','info:age' #查看某列的具体数据
COLUMN CELL
info:age timestamp=1527397813629, value=24
1 row(s) in 0.0530 seconds• 更改某个数据
hbase(main):011:0> get 'student','xll','info:age','25' #再次查看时,数据已经变化• 通过timestamp来获取两个版本的数据
hbase(main):012:0> get 'student','xll',{COLUMN=>'info:age',TIMESTAMP=>1527397813629} #修改前
COLUMN CELL
info:age timestamp=1527397813629, value=24
1 row(s) in 0.0150 seconds
hbase(main):013:0> get 'student','xll',{COLUMN=>'info:age',TIMESTAMP=>1527399122064} #修改后
COLUMN CELL
info:age timestamp=1527399122064, value=25
1 row(s) in 0.0210 seconds如果不加时间戳,则获取的是最新的数据
• 修改版本存储个数:
– alter 'student',{NAME=>'info', VERSIONS=>3} #先修改,使之能够存储3个历史数据hbase(main):021:0> get 'student','xll',{COLUMN=>'info:age', VERSIONS=>3} #查看3个版本
COLUMN CELL
info:age timestamp=1527399609125, value=27
info:age timestamp=1527399516025, value=26
info:age timestamp=1527399122064, value=25
3 row(s) in 0.0130 seconds• 删除delete
– 删除指定列簇
hbase(main):026:0> delete 'student','xll','address:country'
0 row(s) in 0.0290 seconds
hbase(main):027:0> get 'student','xll'
COLUMN CELL
address:city timestamp=1527397879925, value=hanzhou
info:age timestamp=1527399618078, value=28
info:birthday timestamp=1527397830188, value=1992.01.20
3 row(s) in 0.0580 seconds – 删除整行
hbase(main):030:0> deleteall 'student','lh'
0 row(s) in 0.0110 seconds• 查看有多少条记录count
count 'student'• 给某id增加字段,并使用counter实现递增
hbase(main):034:0> incr 'student','xll','address:country' #给xll增加country字段
COUNTER VALUE = 1
0 row(s) in 0.0640 seconds• 清空表truncate
– 注意:truncate表的处理过程:由于Hadoop的HDFS文件系统不允许直接修改,所以只能先删除表,再重新创建以达到清空表的目的
hbase(main):039:0> truncate 'student'
Truncating 'student' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 4.1070 seconds四、HBASE目录结构
自0.96版本之后,hbase 源码结构上做了很大的优化,目录结构也发生了变化,做了精简和优化,这里以0.98.8为例介绍,目录如下:
/hbase/.tmp、/hbase/WALs、/hbase/archive、/hbase/corrupt、/hbase/data
/hbase/hbase.id、/hbase/hbase.version、/hbase/oldWALs
1、/hbase/.tmp
当对表做创建或者删除操作的时候,会将表move 到该 tmp 目录下,然后再去做处理操作。
2、/hbase/WALs
HBase 是支持 WAL(Write AheadLog) 的,HBase 在第一次启动之初会给每一台RegionServer 在. WALs下创建一个目录,若客户端如果开启WAL 模式,会先将数据写入一份到WALs下,当 RegionServer crash 或者目录达到一定大小,会开启 replay 模式,类似 MySQL 的 binlog。
WAL最重要的作用是灾难恢复,一旦服务器崩溃,通过重放log,我们可以恢复崩溃之前的数据。如果写入WAL失败,整个操作也将认为失败。
HLog是实现WAL的类。一个HRegionServer对应一个HLog实例。当HRegion初始化时,HLog将作为一个参数传给HRegion的构造函数。
3、/hbase/archive
HBase 在做Split或者 compact 操作完成之后,会将HFile 移到archive 目录中,然后将之前的 hfile 删除掉,该目录由 HMaster 上的一个定时任务定期去清理。
4、/hbase/corrupt
存储HBas损坏的日志文件,一般都是为空的。
5、/hbase/data
这个才是 hbase 的核心目录,0.98版本里支持 namespace 的概念模型,系统会预置两个 namespace 即:hbase和default
5.1 /hbase/data/default
这个默认的namespace即没有指定namespace的表都将会flush 到该目录下面。
5.2 /hbase/data/hbase
这个namespace 下面存储了 HBase 的 namespace、meta 和acl 三个表,这里的 meta 表跟0.94版本的.META.是一样的,自0.96之后就已经将 ROOT 表去掉了,直接从Zookeeper 中找到meta 表的位置,然后通过 meta 表定位到 region。 namespace 中存储了 HBase 中的所有 namespace 信息,包括预置的hbase 和 default。acl 则是表的用户权限控制。
如果自定义一些namespace 的话,就会再/hbase/data 目录下新建一个 namespace 文件夹,该 namespace 下的表都将 flush 到该目录下。
6、/hbase/hbase.id
它是一个文件,存储集群唯一的 cluster id 号,是一个 uuid。
7、/hbase/hbase.version
同样也是一个文件,存储集群的版本号,貌似是加密的,看不到,只能通过web-ui 才能正确显示出来。
8、/hbase/oldWALs
当.logs 文件夹中的 HLog 没用之后会 move 到.oldlogs 中,HMaster 会定期去清理。
五、Hbase深入
1.HBase的读数据流程
1)HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在的位置信息,即找到这个meta表在哪个HRegionServer上保存着。
2)接着Client通过刚才获取到的HRegionServer的IP来访问Meta表所在的HRegionServer,从而读取到Meta,进而获取到Meta表中存放的元数据。
3)Client通过元数据中存储的信息,访问对应的HRegionServer,然后扫描所在HRegionServer的Memstore和Storefile来查询数据。
4)最后HRegionServer把查询到的数据响应给Client。
2.HBase的写数据流程
1)Client也是先访问zookeeper,找到Meta表,并获取Meta表元数据。
2)确定当前将要写入的数据所对应的HRegion和HRegionServer服务器。
3)Client向该HRegionServer服务器发起写入数据请求,然后HRegionServer收到请求并响应。
4)CLient先把数据写入到HLog,以防止数据丢失。
5)然后将数据写入到Memstore
6)如果HLog和Memstore均写入成功,则这条数据写入成功
7)如果Memstore达到阈值(注意,不存在“阀值”这么一说,属于长期的误用,在此提醒),会把Memstore中的数据flush到Storefile中。
8)当Storefile越来越多,会触发Compact合并操作,把过多的Storefile合并成一个大的Storefile。
9)当Storefile越来越大,Region也会越来越大,达到阈值后,会触发Split操作,将Region一分为二。
3.三个机制
1)Flush机制
当MemStore达到阈值,将Memstore中的数据Flush进Storefile。
涉及属性:hbase.hregion.memstore.flush.size:134217728,即:128M就是Memstore的默认阈值
hbase.regionserver.global.memstore.upperLimit:0.4,即:这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。RegionServer的flush是通过将请求添加一个队列,模拟生产消费模式来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。
hbase.regionserver.global.memstore.lowerLimit:0.38,即:当MemStore使用内存总量达到hbase.regionserver. global.memstore.upperLimit指定值时,将会有多个MemStoresflush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于hbase.regionserver.global.memstore.lowerLimit。
2)Compact机制:
把小的Memstore文件合并成大的Storefile文件。
在HBase中,每当memstore的数据flush到磁盘后,就形成一个storefile,当storefile的数量越来越大时,会严重影响HBase的读性能 ,所以必须将过多的storefile文件进行合并操作。Compaction是Buffer-flush-merge的LSM-Tree模型的关键操作,主要起到如下几个作用:
(1)合并文件
(2)清除删除、过期、多余版本的数据
(3)提高读写数据的效率
hbase(main):043:0> merge_region '759a217c34ad520380b6b209','939affd9185022367a0a4a59a', true #后面跟的是region的id
hbase(main):043:0> major_compact 'student'3)Split机制
当Region达到阈值,会把过大的Region一分为二。

在Hbase中split是一个很重要的功能,Hbase是通过把数据分配到一定数量的region来达到负载均衡的。一个table会被分配到一个或多个region中,这些region会被分配到一个或者多个regionServer中。在自动split策略中,当一个region达到一定的大小就会自动split成两个region。table在region中是按照row key来排序的,并且一个row key所对应的行只会存储在一个region中,这一点保证了Hbase的强一致性 。
在一个region中有一个或多个stroe,每个stroe对应一个column families(列族)。一个store中包含一个memstore 和 0 或 多个store files。每个column family 是分开存放和分开访问的。
Pre-splitting
当一个table刚被创建的时候,Hbase默认的分配一个region给table。也就是说这个时候,所有的读写请求都会访问到同一个regionServer的同一个region中,这个时候就达不到负载均衡的效果了,集群中的其他regionServer就可能会处于比较空闲的状态。解决这个问题可以用pre-splitting,在创建table的时候就配置好,生成多个region。
在table初始化的时候如果不配置的话,Hbase是不知道如何去split region的,因为Hbase不知道哪个row key可以作为split的开始点。如果我们可以大概预测到row key的分布,我们可以使用pre-spliting来帮助我们提前split region。不过如果我们预测得不准确的话,还是可能导致某个region过热,被集中访问,不过还好我们还有auto-split。最好的办法就是首先预测split的切分点,做pre-splitting,然后后面让auto-split来处理后面的负载均衡。
Hbase自带了两种pre-split的算法,分别是HexStringSplit 和UniformSplit 。如果我们的row key是十六进制的字符串作为前缀的,就比较适合用HexStringSplit,作为pre-split的算法。例如,我们使用HexHash(prefix)作为row key的前缀,其中Hexhash为最终得到十六进制字符串的hash算法。我们也可以用我们自己的split算法。
在hbase shell 下:
hbase org.apache.hadoop.hbase.util.RegionSplitter pre_split_table HexStringSplit -c 10 -f f1【 -c 10 的意思为,最终的region数目为10个;-f f1为创建一个名称为f1的 column family。】
我们也可以自定义切分点,例如在hbase shell下使用如下命令:hbase(main):043:0> create 'student', 'f1', SPLITS=> ['a', 'b', 'c']自动splitting
当一个reion达到一定的大小,他会自动split称两个region。如果我们的Hbase版本是0.94 +,那么默认的有三种自动split的策略,ConstantSizeRegionSplitPolicy,IncreasingToUpperBoundRegionSplitPolicy还有 KeyPrefixRegionSplitPolicy。
在0.94版本之前ConstantSizeRegionSplitPolicy 是默认和唯一的split策略。当某个store(对应一个column family)的大小大于配置值 ‘hbase.hregion.max.filesize’的时候(默认10G)region就会自动分裂。
而0.94版本中,IncreasingToUpperBoundRegionSplitPolicy 是默认的split策略。这个策略中,最小的分裂大小和table的某个region server的region 个数有关,当store file的大小大于如下公式得出的值的时候就会split,公式如下。
Min (R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”) R为同一个table中在同一个region server中region的个数。例如:
hbase.hregion.memstore.flush.size 默认值 128MB。
hbase.hregion.max.filesize默认值为10GB 。
如果初始时R=1,那么Min(128MB,10GB)=128MB,也就是说在第一个flush的时候就会触发分裂操作。
当R=2的时候Min(2*2*128MB,10GB)=512MB,当某个store file大小达到512MB的时候,就会触发分裂。
如此类推,当R=9的时候,store file 达到10GB的时候就会分裂,也就是说当R>=9的时候,store file 达到10GB的时候就会分裂。
split 点都位于region中row key的中间点。KeyPrefixRegionSplitPolicy可以保证相同的前缀的row保存在同一个region中。
指定rowkey前缀位数划分region,通过读取 KeyPrefixRegionSplitPolicy.prefix_length属性【该属性为数字类型,表示前缀长度】,在进行split时,按此长度对splitPoint进行截取。此种策略比较适合固定前缀的rowkey。当table中没有设置该属性,指定此策略效果等同与使用IncreasingToUpperBoundRegionSplitPolicy。可以通过配置 hbase.regionserver.region.split.policy 来指定split策略,我们也可以写我们自己的split策略。
强制split
Hbase 允许客户端强制执行split,在hbase shell中执行以下命令:
hbase(main):042:0> split 'student','b' //其中student为要split的table , ‘b’ 为split 点region splits 执行过程
参考:https://www.cnblogs.com/niurougan/p/3976519.html
region server处理写请求的时候,会先写入memstore,当memstore 达到一定大小的时候,会写入磁盘成为一个store file。这个过程叫做 memstore flush。当store files 堆积到一定大小的时候,region server 会 执行‘compact’操作,把他们合成一个大的文件。 当每次执行完flush 或者compact操作,都会判断是否需要split。当发生split的时候,会生成两个region A 和 region B但是parent region数据file并不会发生复制等操作,而是region A 和region B 会有这些file的引用。这些引用文件会在下次发生compact操作的时候清理掉,并且当region中有引用文件的时候是不会再进行split操作的。这个地方需要注意一下,如果当region中存在引用文件的时候,而且写操作很频繁和集中,可能会出现region变得很大,但是却不split。因为写操作比较频繁和集中,但是没有均匀到每个引用文件上去,所以region一直存在引用文件,不能进行分裂,这篇文章讲到了这个情况,总结得挺好的。http://koven2049.iteye.com/blog/1199519 。
虽然split region操作是region server单独确定的,但是split过程必须和很多其他部件合作。region server 在split开始前和结束前通知master,并且需要更新.META.表,这样,客户端就能知道有新的region。在hdfs中重新排列目录结构和数据文件。split是一个复杂的操作。在split region的时候会记录当前执行的状态,当出错的时候,会根据状态进行回滚。下图表示split中,执行的过程。(红色线表示region server 或者master的操作,绿色线表示client的操作。)
1.region server决定split region,第一步,region server在zookeeper的/hbase/region-in-transition/region-name 目录下,创建一个znode,状态为SPLITTING。
2.因为master有对region-in-transition的znode做监听,所以mater得知parent region需要split。
3.region server在hdfs的parent region的目录下创建一个名为“.splits”的子目录。
4.region server关闭parent region。强制flush缓存,并且在本地数据结构中标记region为下线状态。如果这个时候客户端刚好请求到parent region,会抛出NotServingRegionException。这时客户端会进行补偿性重试。
5.region server在.split目录下分别为两个daughter region创建目录和必要的数据结构。然后创建两个引用文件指向parent regions的文件。
6.region server在HDFS中,创建真正的region目录,并且把引用文件移到对应的目录下。
7.region server送一个put的请求到.META.表中,并且在.META.表中设置parent region为下线状态,并且在parent region对应的row中两个daughter region的信息。但是这个时候在.META.表中daughter region 还不是独立的row。这个时候如果client scan .META.表,会发现parent region正在split,但是client还看不到daughter region的信息。当这个put 成功之后,parent region split会被正在的执行。如果在 RPC 成功之前 region server 就失败了,master和下次打开parent region的region server 会清除关于这次split的脏状态。但是当RPC返回结果给到parent region ,即.META.成功更新之后,region split的流程还会继续进行下去。相当于是个补偿机制,下次在打开这个parent region的时候会进行相应的清理操作。
8.region server打开两个daughter region接受写操作。
9.region server在.META.表中增加daughters A 和 B region的相关信息,在这以后,client就能发现这两个新的regions并且能发送请求到这两个新的region了。client本地具体有.META.表的缓存,当他们访问到parent region的时候,发现parent region下线了,就会重新访问.META.表获取最新的信息,并且更新本地缓存。
10.region server更新znode的状态为SPLIT。master就能知道状态更新了,master的平衡机制会判断是否需要把daughter regions 分配到其他region server 中。
11.在split之后,meta和HDFS依然会有引用指向parent region。当compact操作发生在daughter regions中,会重写数据file,这个时候引用就会被逐渐的去掉。垃圾回收任务会定时检测daughter regions是否还有引用指向parent files,如果没有引用指向parent files的话,parent region 就会被删除。
4.region分配
任何时刻,一个region只能分配给一个region server。master记录了当前有哪些可用的region server。以及当前哪些region分配给了哪些region server,哪些region还没有分配。当存在未分配的region,并且有一个region server上有可用空间时,master就给这个region server发送一个装载请求,把region分配给这个region server。region server得到请求后,就开始对此region提供服务。
5.region server上线
master使用zookeeper来跟踪region server状态。当某个region server启动时,会首先在zookeeper上的server目录下建立代表自己的文件,并获得该文件的独占锁。由于master订阅了server目录上的变更消息,当server目录下的文件出现新增或删除操作时,master可以得到来自zookeeper的实时通知。因此一旦region server上线,master能马上得到消息。6.region server下线
当region server下线时,它和zookeeper的会话断开,zookeeper而自动释放代表这台server的文件上的独占锁。而master不断轮询server目录下文件的锁状态。如果master发现某个region server丢失了它自己的独占锁,(或者master连续几次和region server通信都无法成功),master就是尝试去获取代表这个region server的读写锁,一旦获取成功,就可以确定:1)region server和zookeeper之间的网络断开了。
2)region server挂了。
的其中一种情况发生了,无论哪种情况,region server都无法继续为它的region提供服务了,此时master会删除server目录下代表这台region server的文件,并将这台region server的region分配给其它还活着的regionserver。
如果网络短暂出现问题导致region server丢失了它的锁,那么region server重新连接到zookeeper之后,只要代表它的文件还在,它就会不断尝试获取这个文件上的锁,一旦获取到了,就可以继续提供服务。
7.master上线
master启动进行以下步骤:1)从zookeeper上获取唯一一个代码master的锁,用来阻止其它master成为master。
2)扫描zookeeper上的server目录,获得当前可用的region server列表。
3)和2中的每个region server通信,获得当前已分配的region和region server的对应关系。
4)扫描.META.region的集合,计算得到当前还未分配的region,将他们放入待分配region列表。
8.master下线
由于master只维护表和region的元数据,而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结(无法创建删除表,无法修改表的schema,无法进行region的负载均衡,无法处理region上下线,无法进行region的合并,唯一例外的是region的split可以正常进行,因为只有region server参与),表的数据读写还可以正常进行。因此master下线短时间内对整个hbase集群没有影响。从上线过程可以看到,master保存的信息全是可以冗余信息(都可以从系统其它地方收集到或者计算出来),因此,一般hbase集群中总是有一个master在提供服务,还有一个以上的master在等待时机抢占它的位置。六、Hbase的Python操作
1.安装Thrift:
– ]# wget http://archive.apache.org/dist/thrift/0.8.0/thrift-0.8.0.tar.gz
– ]# tar xzf thrift-0.8.0.tar.gz
– ]# yum install automake libtool flex bison pkgconfig gcc-c++ boost-devel libeventdevel zlib-devel python-devel ruby-devel openssl-devel
– ]# yum install boost-devel.x86_64
– ]# yum install libevent-devel.x86_64进入thrift目录。
– ]# ./configure --with-cpp=no --with-ruby=no
– ]# make
– ]# make install• 产生针对Python的Hbase的API:
–下载hbase源码:
– ]# wget http://mirrors.hust.edu.cn/apache/hbase/0.98.24/hbase-0.98.24-src.tar.gz– [root@master hbase-0.98.24]# find . -name Hbase.thrift
./hbase-thrift/src/main/resources/org/apache/hadoop/hbase/thrift/Hbase.thrift
– [root@master hbase-0.98.24]# cd hbase-thrift/src/main/resources/org/apache/hadoop/hbase/thrift
– ]# thrift -gen py Hbase.thrift
– ]# cp -raf gen-py/hbase/ /home/hbase_test #拷贝出来2.启动Thrift服务
– ]# hbase-daemon.sh start thrift3.Python操作
1)创建表
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
from hbase import Hbase
from hbase.ttypes import *
transport = TSocket.TSocket('masteractive', 9090)
transport = TTransport.TBufferedTransport(transport)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = Hbase.Client(protocol)
transport.open()
#==============================
base_info_contents = ColumnDescriptor(name='meta-data:', maxVersions=1)
other_info_contents = ColumnDescriptor(name='flags:', maxVersions=1)
client.createTable('new_music_table', [base_info_contents, other_info_contents])
print client.getTableNames()2)插入数据
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
from hbase import Hbase
from hbase.ttypes import *
transport = TSocket.TSocket('masteractive', 9090)
transport = TTransport.TBufferedTransport(transport)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = Hbase.Client(protocol)
transport.open()
tableName = 'new_music_table'
rowKey = '1100'
mutations = [Mutation(column="meta-data:name", value="wangqingshui"), \
Mutation(column="meta-data:tag", value="pop"), \
Mutation(column="flags:is_valid", value="TRUE")]
client.mutateRow(tableName, rowKey, mutations, None)3)读取
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
from hbase import Hbase
from hbase.ttypes import *
transport = TSocket.TSocket('masteractive', 9090)
transport = TTransport.TBufferedTransport(transport)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = Hbase.Client(protocol)
transport.open()
tableName = 'new_music_table'
rowKey = '1100'
result = client.getRow(tableName, rowKey, None)
for r in result:
print 'the row is ' , r.row
print 'the name is ' , r.columns.get('meta-data:name').value
print 'the flag is ' , r.columns.get('flags:is_valid').value