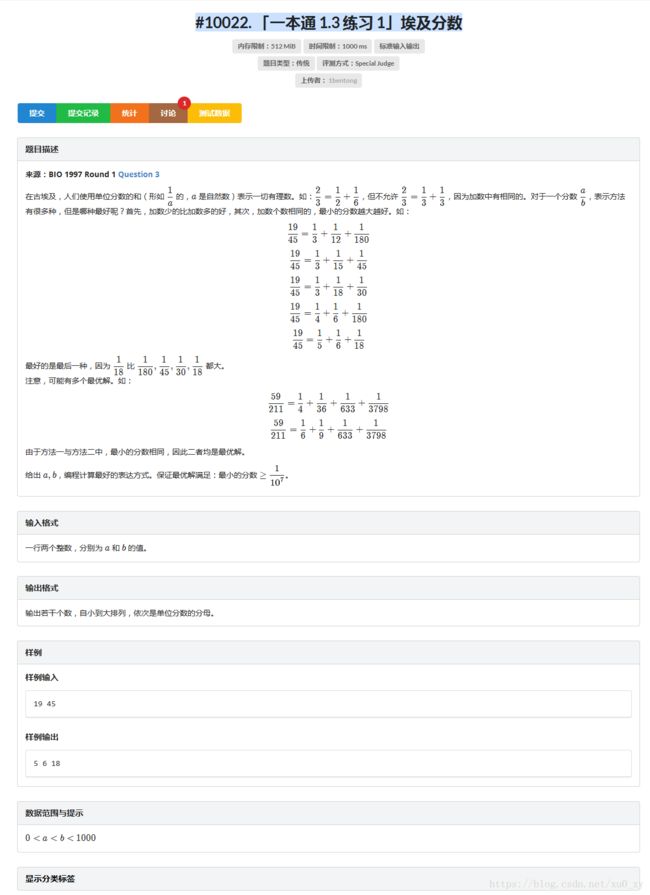
Loj #10022. 「一本通 1.3 练习 1」埃及分数
题目链接
题解
感觉用 B F S BFS BFS 会更快,但是既然在 D F S DFS DFS 类型题里做到,那么还是用DFS来解好了。
先枚举最大深度。
接着是我们搜索的时候需要携带的量:
①上一次的分母 l s t lst lst
②已经搜索到的深度 t o t tot tot
③ a b \frac{a}{b} ba 减去已选的 1 c \frac{1}{c} c1 剩下的值(为了防止精度问题,我们分成分子 x x x 和分母 y y y)
接着考虑最终状态。
当我们枚举到当前最大深度的时候就不能往下搜索了。
判断一下是否修正 a n s ans ans
中间过程枚举搜索。
直接搜索明显超时超得一塌糊涂,肯定要加剪枝。
首先我们可以从 $ i=max{lst+1,(y+x-1)/x}$(整除) 处开始枚举(这个 i i i 是满足 1 i > x y \frac{1}{i} > \frac{x}{y} i1>yx 且最小的)
证明1
然后我们还能预判至少还要选择几个。
如果 t o t + x y / 1 i tot+\frac xy/\frac{1}{i} tot+yx/i1 即 $tot+\frac {x*i}{y} > len $,那么我们接下来肯定不能找到可行解。
证明2
若写 D F S DFS DFS,假设上一次深度为 l e n len len 时没有可行解,这次深度为 l e n + 1 len+1 len+1 时我们会把上次 深度为 l e n len len 的情况重新走一遍,再搜所第 l e n + 1 len+1 len+1 次。若写 B F S BFS BFS,队列的内存有点大,这会影响效率。
代码
#include若 i i i 满足 1 i < = x y \frac{1}{i} <= \frac xy i1<=yx 且最小。必定是满足 i > = y x i >= \frac{y}{x} i>=xy。即 i = ⌈ y x ⌉ i=⌈{\frac yx}⌉ i=⌈xy⌉ ↩︎
因为我们选择的分母单调增,分子不变,所以分数单调减。若分数不变的情况下我们都至少要再选 x ∗ i y \frac{x*i}{y} yx∗i 个,记作 P 1 P1 P1,我们实际选的个数 P 2 P2 P2 肯定满足 P 2 ≥ P 1 P2\geq P1 P2≥P1,若 t o t + P 1 > l e n tot+P1 > len tot+P1>len 那么一定满足 t o t + P 2 > l e n tot+P2 > len tot+P2>len。 ↩︎