Paragraph Vector学习文章特征及其在Gensim和Tensorflow上的编写以及应用
原文
Paragraph2vec 是一种非监督学习方式,输入为文本,输出则是文本对应的向量表示。
连续分布式向量表示。文本可以是可变的长度(对应于 sentence 及 documents)。
向量表示可以用来预测文章中的 word。可以连接 paragraph vector和 word vector,预测给定的 context 下将要出现的 word。 word 向量和 para 向量都是通过 GD 和 BP 计算出来的。para 向量唯一对应于相应的文章,而 word 向量则是全局共享的。在 predict 时,固定 word 向量,并训练新的 para 向量直到收敛获得 para 向量的预测。
word 向量一般是通过对 context 下得 word 向量进行连接或者平均获得。结果向量用来预测在这个 context 下的其他 word。例如在NNLM(Bengio 06)中,使用前面出现的 word 向量的连接作为神经网络的输入,目的是预测下面的 word。在 model 训练完成,word 向量被映射到一个向量空间,使得语义相似的 word 拥有相似的向量表示。(如“strong” 靠近 “powerful”)
在此基础上,出现了 phrase 和 sentence 层的表示。使用文档中出现的 word 的平均权重来表示一个 document。更复杂的是使用 sentence 的分析树,使用矩阵向量操作。这两种方式都有弱点,因为他们都忽略了 word 在 document 中出现的顺序。第二种由于依赖于分析(parsing)则只能处理 sentence。
para 向量可以用来构造可变长度的输入序列的表示。不同于前面的一些方法,para 向量是通用的并可以用在任意长度的文本上。例如,在情感分析人物中,我们获得新的结果,比那些复杂的方法还要好。在文本分类的工作中,我们的方法相较于bag-of-words方法有超过30%的提升。
算法
学习 word 的向量表示
每个 word 都被映射到一个唯一的向量,也就对应于矩阵 M 中得一个列。列则是有词在词汇表中的位置索引。那么这些 word 向量的连接和求和就可以作为这个句子中下一个 word 预测的前提。
给定
word 向量模型的目标就是优化下面的平均 log 概率
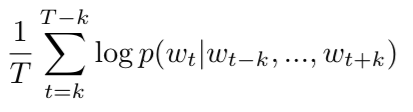
这个预测的任务使用了多类分类器完成,例如 softmax。我们有:
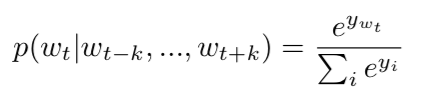
每个 y_i 是对应于每个输出 word i 的一个未正规化的 log 概率,计算公式如下:
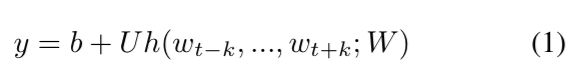
其中 U,b 是 softmax 参数。h由 word 向量的连接或者平均获得。
层次化 softmax 通过一个二叉 Huffman 树完成,短的编码对应于出现频繁的 word。这样常用词可以很快的查到。
基于 word 向量的神经网络通常使用 SGD 训练,其中gradient 通过 BP 获得。这是比较常见的 NNLM。
paragraph 向量:分布式记忆模型
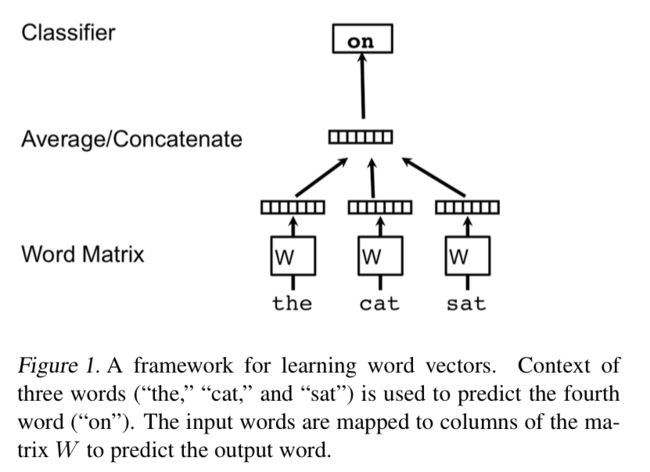
每篇文档映射在一个唯一的向量上,由矩阵D中的一列表示,每个 word 则类似地被映射到向量上,这个向量由矩阵 M 的列表示。同样是使用连接或者平均的方式获得新 word 的预测。在实验中,使用的连接的方式进行。
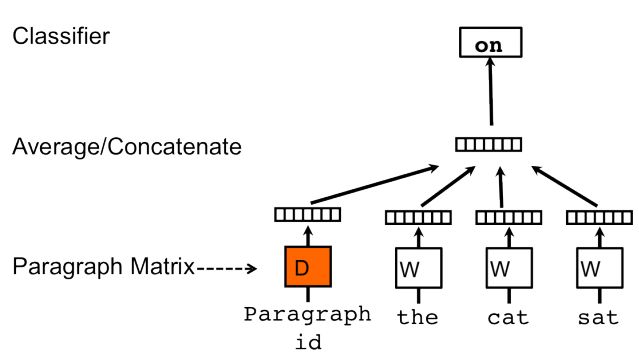
也就是说,唯一与 word2vec 不同的地方就是公式(1):h 由 W 和 D 共同构造。
算法本身两个关键步骤:
- 训练获得word向量
W,softmax权值U,b和在已经见过的para 向量D上; - 推断步骤:获得新 paragraph 的 para 向量
D和在固定W,U,b时的D上的下降的 gradient。我们使用D并借助通常的分类器做出预测特定的标签。
para 向量的优点:从未标记数据学得,因此可以应用在没有太多标签得数据上。还有 para 向量解决了 bag-of-words 的没有 word 顺序的问题。并且极大地降低了表示的维度。
转载自:http://www.jianshu.com/p/d34d61188ab5
****************************************************************************************************************************************************目前,Mikolov以及Bengio的最新论文Ensemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews里就引入了该模型作为用户对影视作品的评论分析方法。与此同时,网络上很多地方也指出该模型效果并没有其前期模型Word2Vec的效果好。这里,我们先不讨论其效果是好是坏,单就如何搭建该模型来展开讨论。首先,我将介绍该模型的Gensim编写方法,之后,在Gensim模型的思维下,我们将尝试运用Tensorflow来编写这个模型。在我们开始码代码前,对于这个模型,还是有必要做一点稍许介绍的。
模型背景:
该模型起始于Word2Vec中的CBOW以及Skip-Gram模型。从模型的框架来看,其结构基本等同于CBOW或者Skip-Gram模型,但最大区别在于加入了一个新的于单词维度相等的维度作为句子维度,段落维度或者文章维度。 维度的意义为需要运用该模型的人他们所需要代表的意义,即句子分类,段落分类还是文章分类。这个新的维度存在于不同于单词维度的空间,所以大家注意不要混淆单词维度和这个新维度的概念。模型的训练方式等同于Word2Vec。模型的目的在于为单词加入一些更长的序列意义外同时为句子,段落或者文章的非监督分类得到类似于Word2Vec的效果。详细的说明大家可以阅读如下链接(即上文)。
模型代码:
1. Gensim代码:
首先,让我们来看看Gensim代码是如何表达的:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
from
gensim.models
import
doc2vec
from
collections
import
namedtuple
import
csv
import
re
import
string
# 选择wikipedia作为输入,录入一部分wikipedia的csv文档
reader
=
csv.reader(
open
(
"wikipedia.csv"
))
count
=
0
data
=
''
for
row
in
reader:
count
=
count
+
1
if
count >
301
:
break
else
:
data
+
=
row[
1
]
# 分句。我们以句号,问号以及感叹号作为分句依据。
# 值得注意的是,该依据并非十分严谨,例如英文中的
# Mr.Wang就会被划分为两句,但是由于该代码是作为
# 示范,我们对严谨的分句并不感兴趣,大家有空可以
# 做更好的处理
sentenceEnders
=
re.
compile
(
'[.?!]'
)
data_list
=
sentenceEnders.split(data)
# 建设一个namedtuple框架来装载输入
LabelDoc
=
namedtuple(
'LabelDoc'
,
'words tags'
)
exclude
=
set
(string.punctuation)
all_docs
=
[]
count
=
0
for
sen
in
data_list:
word_list
=
sen.split()
# 当一句话小于三个词儿时,我们认为其意义并不
# 完整,所以去除该类话以净化我们的输入。
if
len
(word_list) <
3
:
continue
tag
=
[
'SEN_'
+
str
(count)]
count
+
=
1
sen
=
''.join(ch
for
ch
in
sen
if
ch
not
in
exclude)
all_docs.append(LabelDoc(sen.split(), tag))
# 打印例子来看看all_docs的形状
print
all_docs[
0
:
10
]
# 在Gensim的官方文件中,作者指出最好的效果要么来自于随意排列输入句子,要么
# 来自于在训练迭代的过程中减少learning rate alpha,故这里我们运用了后者。
model
=
doc2vec.Doc2Vec(alpha
=
0.025
, min_alpha
=
0.025
)
# use fixed learning rate
model.build_vocab(all_docs)
for
epoch
in
range
(
10
):
model.train(all_docs)
model.alpha
-
=
0.002
# decrease the learning rate
model.min_alpha
=
model.alpha
# fix the learning rate, no decay
# 保存该模型
model.save(
'my_model.doc2vec'
)
|
不难看出,在整理好输入后,除了需要设计减少learning rate alpha外,其余的训练方法非常浅显易懂。在测试该模型的效果时,运行以下代码即可:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import
random
import
numpy as np
import
string
# 选取一个任意的句子id
doc_id
=
np.random.randint(model.docvecs.count)
print
doc_id
# 通过docvecs.most_similar函数计算相近的句子id,并依次打印出前8个
sims
=
model.docvecs.most_similar(doc_id, topn
=
model.docvecs.count)
print
(
'TARGET'
, all_docs[doc_id].words)
count
=
0
for
i
in
sims:
if
count >
8
:
break
pid
=
int
(string.replace(i[
0
],
"SEN_"
, ""))
print
(i[
0
],
": "
, all_docs[pid].words)
count
+
=
1
|
运行结果如下:

显而易见,当我们的目标句子是关于Maldonado时,我们的最接近句子也是关于他的。同时,我们的句子是关羽notable victories(明显的胜利)时,第二接近的句子也是关于这个主题。由此可见,系统的确学习到了一些关联性。但是我们终究只是运用了一个黑盒子,这个黑盒子到底是怎么工作的呢?下面我们将试图用Tensorflow还原这个逻辑。
2. Tensorflow代码:
在我5月19日的博客上已经介绍了关于Word2Vec里CBOW模型在Tensorflow上的编写,详细信息请点击链接查询。基于这个模型,我们将来推演如何更改以获得PV-DM模型,即Paragraph Vector版本的CBOW模型。
首先,我们需要整理输入。方法相同于之前Gensim的代码,这里将不予重复。但是值得注意的是,原来的wikipedia.csv文档被我们预处理为一个装有单词list以及其对应句子id的一个namedtuple struct。那么,在接受这个struct的同时,我们需要更改build_data函数来正确的组建dictionary以及我们需要的data输入。这里,我们的目标是保持原来的count, dictionary以及reverse dictionary, 但是对于输入data,我们希望直接更改我们的输入,把namedtuple中,单词list里的单词换成他们在dictionary中的index。如下代码将做到这个功能:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
def
build_dataset(input_data, min_cut_freq):
# 这里将input_data重新收集为CBOW模型中的words list以方便
# counter函数的使用。
words
=
[]
for
i
in
input_data:
for
j
in
i.words:
words.append(j)
count_org
=
[[
'UNK'
,
-
1
]]
count_org.extend(collections.Counter(words).most_common())
count
=
[[
'UNK'
,
-
1
]]
for
word, c
in
count_org:
word_tuple
=
[word, c]
if
word
=
=
'UNK'
:
count[
0
][
1
]
=
c
continue
if
c > min_cut_freq:
count.append(word_tuple)
dictionary
=
dict
()
for
word, _
in
count:
dictionary[word]
=
len
(dictionary)
data
=
[]
unk_count
=
0
for
tup
in
input_data:
word_data
=
[]
for
word
in
tup.words:
if
word
in
dictionary:
index
=
dictionary[word]
else
:
index
=
0
unk_count
+
=
1
word_data.append(index)
data.append(LabelDoc(word_data, tup.tags))
count[
0
][
1
]
=
unk_count
reverse_dictionary
=
dict
(
zip
(dictionary.values(), dictionary.keys()))
return
data, count, dictionary, reverse_dictionary
|
由以上代码,我们将会得到我们需要的输入。那么,如何建立我们的模型呢?在建立模型前,我们需要跟改generate_batch函数以求保持原来的batch和label输出外,增加一个对应每个label的一个paragraph label。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
def
generate_DM_batch(batch_size, num_skips, skip_window):
global
word_index
global
sentence_index
assert
batch_size
%
num_skips
=
=
0
assert
num_skips <
=
2
*
skip_window
batch
=
np.ndarray(shape
=
(batch_size, num_skips), dtype
=
np.int32)
labels
=
np.ndarray(shape
=
(batch_size,
1
), dtype
=
np.int32)
para_labels
=
np.ndarray(shape
=
(batch_size,
1
), dtype
=
np.int32)
# Paragraph Labels
span
=
2
*
skip_window
+
1
# [ skip_window target skip_window ]
buffer
=
collections.deque(maxlen
=
span)
for
_
in
range
(span):
buffer
.append(data[sentence_index].words[word_index])
sen_len
=
len
(data[sentence_index].words)
if
sen_len
-
1
=
=
word_index:
# reaching the end of a sentence
word_index
=
0
sentence_index
=
(sentence_index
+
1
)
%
len
(data)
else
:
# increase the word_index by 1
word_index
+
=
1
for
i
in
range
(batch_size):
target
=
skip_window
# target label at the center of the buffer
targets_to_avoid
=
[ skip_window ]
batch_temp
=
np.ndarray(shape
=
(num_skips), dtype
=
np.int32)
for
j
in
range
(num_skips):
while
target
in
targets_to_avoid:
target
=
random.randint(
0
, span
-
1
)
targets_to_avoid.append(target)
batch_temp[j]
=
buffer
[target]
batch[i]
=
batch_temp
labels[i,
0
]
=
buffer
[skip_window]
para_labels[i,
0
]
=
sentence_index
buffer
.append(data[sentence_index].words[word_index])
sen_len
=
len
(data[sentence_index].words)
if
sen_len
-
1
=
=
word_index:
# reaching the end of a sentence
word_index
=
0
sentence_index
=
(sentence_index
+
1
)
%
len
(data)
else
:
# increase the word_index by 1
word_index
+
=
1
return
batch, labels, para_labels
|
这里,我们保持了两个global的变量,即word_index和sentence_index。前者标记了在一句中前一个batch读到了哪个单词,后者标记了前一个batch读到了哪个句子。他们的初始值都是0。如果我们发现目前所读入的单词在句子中是最后一个词,即sen_len - 1 == word_index, 我们将会重置word_index,并移动sentence_index去向下一句。这样,我们保持了原有的batch和labels外针对每一个input window定义了它自身所应对的一个para_label。 好了,材料齐备了,那么我们如何运用这些材料构建paragraph vector呢?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
with graph.as_default():
# Input data.
train_inputs
=
tf.placeholder(tf.int32,shape
=
[batch_size, skip_window
*
2
])
train_labels
=
tf.placeholder(tf.int32, shape
=
[batch_size,
1
])
#paragraph vector place holder
train_para_labels
=
tf.placeholder(tf.int32,shape
=
[batch_size,
1
])
# Ops and variables pinned to the CPU because of missing GPU implementation
with tf.device(
'/cpu:0'
):
# Look up embeddings for inputs.
embeddings
=
tf.Variable(tf.random_uniform([vocabulary_size, embedding_size],
-
1.0
,
1.0
))
embed_word
=
tf.nn.embedding_lookup(embeddings, train_inputs)
# Look up embeddings for paragraph inputs
para_embeddings
=
tf.Variable(tf.random_uniform([paragraph_size, embedding_size],
-
1.0
,
1.0
))
embed_para
=
tf.nn.embedding_lookup(para_embeddings, train_para_labels)
# Concat them and average them
embed
=
tf.concat(
1
, [embed_word, embed_para])
reduced_embed
=
tf.div(tf.reduce_sum(embed,
1
), skip_window
*
2
+
1
)
# Construct the variables for the NCE loss
nce_weights
=
tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size],
stddev
=
1.0
/
math.sqrt(embedding_size)))
nce_biases
=
tf.Variable(tf.zeros([vocabulary_size]))
# Compute the average NCE loss for the batch.
# tf.nce_loss automatically draws a new sample of the negative labels each
# time we evaluate the loss.
loss
=
tf.reduce_mean( tf.nn.nce_loss(nce_weights, nce_biases, reduced_embed, train_labels,
num_sampled, vocabulary_size))
|
这里,我们首先保留了原来的word embedding的graph,在此基础上,我们加入了paragraph_labels的placeholder,并且定义了paragraph vector的embedding。在把他们合并并且加权平均了后,我们通过nce loss的方式训练该模型。最后
|
1
2
3
4
5
6
7
8
9
10
|
with tf.Session(graph
=
graph) as session:
# We must initialize all variables before we use them.
init.run()
print
(
"Initialized"
)
average_loss
=
0
for
step
in
xrange
(num_steps):
batch_inputs, batch_labels, batch_para_labels
=
generate_DM_batch(
batch_size, num_skips, skip_window)
feed_dict
=
{train_inputs : batch_inputs, train_labels : batch_labels, train_para_labels: batch_para_labels}
|
在session里,我们呼叫我们的generatge_DM_batch函数并将batch, label和paragraph_label喂给我们的模型。该模型在运行的过程中效果并不很好,由于时间紧张,我没有对模型进行优化。之后我将会gensim里关于shuffle输入语句或者减少learning rate alpha的提议进行尝试。如果你发现我的代码有误,请务必指出,感谢你的热情参与!谢谢!代码可以在这里找到.
转载自:http://www.cnblogs.com/edwardbi/p/5540898.html