TensorFlow2.0 (6) 自构建神经网络层—— transformer 实例讲解
有些网络结构,在子类 layer 中并没有定义,这时就需要我们自己来进行编写,为了更灵活的构建自己想要的神经网络层,我们可以自己来创建网络结构类,当然,构建之前先看一眼官方 API 文档,省得白费功夫那是最好。
tensorflow2 官方 API 文档
注意:__init__() ,__build__() ,__call__() 均继承自 tf.keras.layers.Layer
一、 初始化属性、初始化输入、向前运算
不多说,先挂个最简单的官方例子
class MyDenseLayer(tf.keras.layers.Layer):
def __init__(self, num_outputs):
super(MyDenseLayer, self).__init__()
self.num_outputs = num_outputs
def build(self, input_shape):
self.kernel = self.add_weight("kernel",
shape=[int(input_shape[-1]),
self.num_outputs])
def call(self, input):
return tf.matmul(input, self.kernel)
layer = MyDenseLayer(10)其中,我们先介绍一下 init
init:
主要负责除了输入以外的所有成员变量的定义(输入的形状定义在 build 定义),这个输入以外的成员变量定义就包括了输出的定义,除了输出,init 还可以负责 层数和节点数量的定义 等等。当然,你也可以在 init 中创建输入的形状,不过你需要固定下来,而 build 可以动态的拟合。
build:
主要负责对输入的定义,在call 第一次被执行的时候会被调用一次,输入数据的形状需要在 build 中动态的获取,也就是说在你不需要动态获取输入形状的时候,可能就不需要 build 函数了。
call:
被调用时会被执行
二、 transformer 实例讲解
我们先看一下 transformer 的结构图
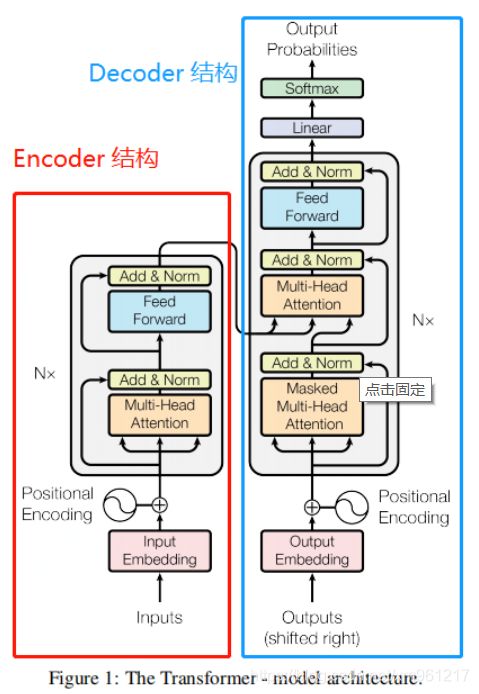
整体上来看,transformer 是一个 encoder-decoder 的结构,这里主要讲一下 encoder 作为自定义层得示例,
首先输入经过 word embedding 和 positional encoding 做直接加和,
其中 encoder 有六层,每层里面又有两层,分别为一层 self-attention 层和一个 全连接层,其中 self-attention 层并不是只有一层, multi-head-Attention 是指多个 self-attention ,也就是多头 self attention。
然后再把前面多头的输出拼起来,再做一次残差连接(residual connection)和层归一化(layer Normalization)再传入到全连接层中。之后再做一次 残差连接和LN,输入到 Decoder 部分
Decoder 部分这里就不详细介绍(https://www.jianshu.com/p/83de224873f1)
当然,我这里的代码不是标准的 MultiHeadedAttention ,做学习使用
引入的包
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
from sklearn.preprocessing import *
from tcn import TCN
from tqdm import tqdm
import keras
from keras.layers import Dense, Dropout, LSTM,Reshape, GRU,Conv1D, Conv2D,Flatten,Permute, multiply,BatchNormalization, Activation, AveragePooling1D, GlobalAveragePooling1D, Lambda, Input, Concatenate, Add, UpSampling1D, Multiply
from keras.models import Model
from keras.objectives import mean_squared_error
import keras.backend as K
from keras.utils.vis_utils import plot_model
from keras.losses import binary_crossentropy, categorical_crossentropy
from keras_layer_normalization import LayerNormalization
from keras.callbacks import ModelCheckpoint, EarlyStopping, TensorBoard, ReduceLROnPlateau,LearningRateScheduler
from keras.initializers import random_normal
from keras.optimizers import Adam, RMSprop, SGD
from keras import regularizers
from keras.callbacks import Callback
from keras_self_attention import SeqSelfAttention
import tensorflow as tf下面的代码中只有 encoder 是自定义的函数,其他都是使用的tensorflow自带函数构建,所以我们重点看一下 encoder
def transformer_model(seq_len = 300,n_layers=8,num_heads = 13,middle_units = 512,
num_channel=39,training=True):
seq_input = Input((seq_len,num_channel), name='seq_input')
sample_encoder = Encoder(n_layers, num_channel, num_heads, middle_units, seq_len, training)
sample_encoder_output = sample_encoder([seq_input])
x = sample_encoder_output
x = GlobalAveragePooling1D()(x)
x = BatchNormalization()(x)
x = Dense(512,activation='relu')(x)
x = BatchNormalization()(x)
x = Dense(128,activation='relu')(x)
x = BatchNormalization()(x)
out = Dense(1)(x)
model = Model(inputs=[seq_input], outputs=out)
return model一个输入层 + encoder + GlobalAveragePooling1D+批归一化+全连接层+批归一化+全连接层+批归一化+单节点全连接层+Model函数,我们介绍一下 Global 然后讲解一下 encoder 函数
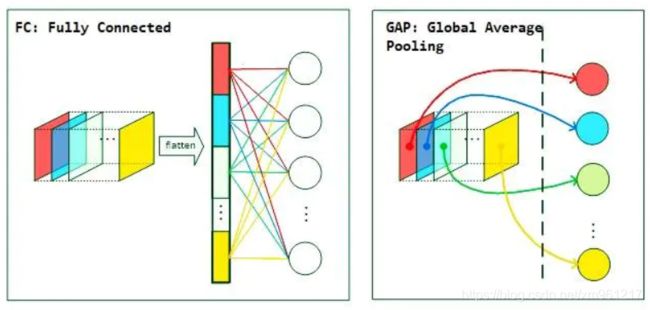
关于 GlobalAveragePooling1D ,是将 W*H*D 变成 1*1*D,就是求一个全局的平均值
我找到了一张图很好的的解释了这个操作
Encoder:
# 编码器函数
class Encoder(keras.layers.Layer):
#初始化类,将编码器属性赋值
def __init__(self, n_layers, d_model, num_heads, middle_units,
max_seq_len, epsilon=1e-6, dropout_rate=0.1, training=False, **kwargs):
# 保证父类只被执行一次
super(Encoder, self).__init__(**kwargs)
self.n_layers = n_layers
self.d_model = d_model
self.pos_embedding = PositionalEncoding(sequence_len=max_seq_len, embedding_dim=d_model)
self.encode_layer = [EncoderLayer(d_model=d_model, num_heads=num_heads,
middle_units=middle_units,
epsilon=epsilon, dropout_rate=dropout_rate,
training = training)
for _ in range(n_layers)]
def call(self, inputs, **kwargs):
emb = inputs[0]
emb = self.pos_embedding(emb)
for i in range(self.n_layers):
emb = self.encode_layer[i](emb)
return embencoder 在前面的介绍 transformer 的时候我们讲了是有多层的,所以这里的 n_layers 就是定义这个有多少层,并且输入需要先经过 positional encoding,
也就是 PositionalEncoding
PositionalEncoding (Encoder)
class PositionalEncoding(keras.layers.Layer):
def __init__(self, sequence_len=None, embedding_dim=None, **kwargs):
self.sequence_len = sequence_len
self.embedding_dim = embedding_dim
super(PositionalEncoding, self).__init__(**kwargs)
def call(self, inputs):
if self.embedding_dim == None:
self.embedding_dim = int(inputs.shape[-1])
position_embedding = np.array([
[pos / np.power(10000, 2. * i / self.embedding_dim) for i in range(self.embedding_dim)]
for pos in range(self.sequence_len)])
position_embedding[:, 0::2] = np.sin(position_embedding[:, 0::2]) # dim 2i
position_embedding[:, 1::2] = np.cos(position_embedding[:, 1::2]) # dim 2i+1
position_embedding = tf.cast(position_embedding, dtype=tf.float32)
return position_embedding + inputs
def compute_output_shape(self, input_shape):
return input_shape
Encoder layer(Encoder)
class EncoderLayer(keras.layers.Layer):
def __init__(self, d_model, num_heads, middle_units, \
epsilon=1e-6, dropout_rate=0.1, training=False, **kwargs):
super(EncoderLayer, self).__init__(**kwargs)
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, middle_units)
self.layernorm1 = LayerNormalization()
self.layernorm2 = LayerNormalization()
self.dropout1 = keras.layers.Dropout(dropout_rate)
self.dropout2 = keras.layers.Dropout(dropout_rate)
self.training = training
def call(self, inputs, **kwargs):
att_output = self.mha([inputs, inputs, inputs])
att_output = self.dropout1(att_output, training=self.training)
out1 = self.layernorm1(inputs + att_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=self.training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2MultiHeadAttention(EncoderLayer)
self-attention
class MultiHeadAttention(keras.layers.Layer):
def __init__(self, d_model, num_heads, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.d_model = d_model
assert d_model % num_heads == 0
self.depth = d_model // num_heads
self.wq = keras.layers.Dense(d_model)
self.wk = keras.layers.Dense(d_model)
self.wv = keras.layers.Dense(d_model)
self.dense = keras.layers.Dense(d_model)
self.dot_attention = scaled_dot_product_attention
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, inputs, **kwargs):
q, k, v = inputs
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k)
v = self.wv(v)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
scaled_attention = self.dot_attention(q, k, v) # (batch_size, num_heads, seq_len_q, depth)
scaled_attention = tf.transpose(scaled_attention, [0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))
output = self.dense(concat_attention)
return outputscaled_dot_product_attention(MultiHeadAttention)
# dot attention
def scaled_dot_product_attention(q, k, v):
matmul_qk = tf.matmul(q, k, transpose_b=True)
dim_k = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dim_k)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
output = tf.matmul(attention_weights, v)
return outputpoint_wise_feed_forward_network(EncoderLayer)
def point_wise_feed_forward_network(d_model, middle_units):
return keras.Sequential([
keras.layers.Dense(middle_units, activation='relu'),
keras.layers.Dense(d_model, activation='relu')])
三、 未完待续
后续自定义碰到问题再补充