Keras学习简单实例入门(1)
引用参考自该文章
关于Keras
Keras是当前构建神经网络最为容易的框架,就是因为相比于Theano和TensorFlow,你会发现使用Keras,你所需要自行编写的代码是最少的。
Keras是一个模型级的库,通常上来就 import kears 为开发深度学习模型提供了高层次的构建模块;
它依赖于一个专门的、高度优化的张量(tensor)库来完成这些运算,这个张量库就是Keras的后端引擎(backend engine),此案例采用的还是广为熟知的Tensorflow后端。
总的来说,使用Keras构建神经网络的基本工作流程主要可以分为4个部分。而且这个用法和思路我个人感觉,很像是在使用Scikit-learn中的机器学习方法
毕竟深度学习属于机器学习的一个子集,使用Keras开发的主要思路分四个步骤:
构建模型→ 配置损失函数和优化器 → 训练数据 → 评估和预测
(Model definition → Model compilation → Training → Evaluation and Prediction)
实例分析
先放上完整可运行的代码,推荐用Jupyter Notebook运行,详情配置Keras+Tensorflow可参考win10上配置GPU版
# 模拟简单数据
# 思路:Model definition → Model compilation → Training → Evaluation and Prediction
import os
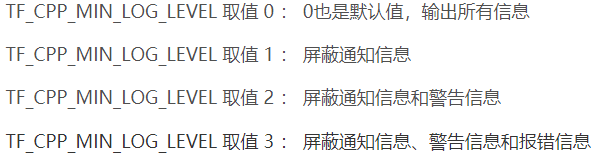
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 屏蔽通知消息和警告消息
os.environ['KERAS_BACKEND']='tensorflow'
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential# 引入两个重要的类,Sequential和Dense
from keras.layers import Dense
x = np.linspace(-2, 6, 200)
#人为地造一组由 y = 0.5x + 2 加上一些噪声而生成的数据
np.random.shuffle(x)
y = 0.5 * x + 2 + 0.15 * np.random.randn(200,)
#plot the data
plt.scatter(x, y)
plt.show()
# 开始构建模型
model = Sequential()
model.add(Dense(units=1, input_dim=1))# 构建全连接层,此案例全连接层只有一层,而且输入的节点数和输出的节点数都为1
model.compile(loss='mse', optimizer='sgd')# 默认优化器 'sgd'表示随机梯度下降
# train the first 160 data
x_train, y_train = x[0:160], y[0:160] # 前160个作为训练集
# start training
# model.fit(x_train, y_train, epochs=100, batch_size=64)
for step in range(0, 500):
cost = model.train_on_batch(x_train, y_train)
if step % 20 == 0:
print('cost is %f' % cost)
# test on the rest 40 data
x_test, y_test = x[160:], y[160:] # 后40个作为测试集
# start evaluation
cost_eval = model.evaluate(x_test, y_test, batch_size=40)
print('evaluation lost %f' % cost_eval)
model.summary()
w, b = model.layers[0].get_weights()
print('weight %f , bias %f' % (w, b))
# start prediction
y_prediction = model.predict(x_test)
plt.scatter(x_test, y_test)
plt.plot(x_test, y_prediction)
plt.show()
逐个分析:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 屏蔽通知消息和警告消息
os.environ['KERAS_BACKEND']='tensorflow'
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential# 引入两个重要的类,Sequential和Dense
from keras.layers import Dense
此部分为库的调用声明,os.environ用于屏蔽一些冗杂的消息显示。
构建数据:
x = np.linspace(-2, 6, 200)
#人为地造一组由 y = 0.5x + 2 加上一些噪声而生成的数据
np.random.shuffle(x)
y = 0.5 * x + 2 + 0.15 * np.random.randn(200,)
#plot the data
plt.scatter(x, y)
plt.show()
首先,我们人为地造一组由 y = 0.5x + 2 加上一些噪声而生成的数据,数据量一共有200个,其中前160作为train set(训练集),后40作为test set(测试集)。
训练集 - 用于训练模型的子集。
测试集 - 用于测试训练后模型的子集。
# 开始构建模型
model = Sequential()
model.add(Dense(units=1, input_dim=1))
# 构建全连接层,此案例全连接层只有一层,而且输入的节点数和输出的节点数都为1
model.compile(loss='mse', optimizer='sgd')# 默认优化器 'sgd'表示随机梯度下降
# train the first 160 data
x_train, y_train = x[0:160], y[0:160] # 前160个作为训练集
# start training
# model.fit(x_train, y_train, epochs=100, batch_size=64)
for step in range(0, 500):
cost = model.train_on_batch(x_train, y_train)
if step % 20 == 0:
print('cost is %f' % cost)
# test on the rest 40 data
x_test, y_test = x[160:], y[160:] # 后40个作为测试集
其中 model.compile(loss=‘mse’, optimizer=‘sgd’) 中的loss指损失函数
损失函数(目标函数)——在训练过程中需要将其最小化。它能够衡量当前任务是否已经完成。
optimizer指优化器——决定如何基于损失函数对网络进行更新。
在本例中把训练部分写成下面这种形式,其中每20步,我们会输出一次cost(损失)。

选择正确的目标函数十分重要。网络的目的是使损失尽可能最小化,因此,如果目标函数与成功完成当前任务完全不相关,那么网络最终得到的结果可能会不符合预期。这里举一个Keras之父在《Python深度学习》中讲到的例子:
利用SGD(随机梯度下降)训练一个愚蠢而又无所不能的人工智能(人工智障),给他一个蹩脚的目标函数:“将所有活着的人的平均幸福感最大化”。为了简化自己的工作,这个AI可能会选择杀死绝大多数人类,只保留几个人并专注于这几个人的幸福。。
梯度下降——简单来说,梯度下降就是从山顶找一条最短的路走到山脚最低的地方。
随机梯度下降法SGD(stochastic gradient descent)
每个数据都计算算一下损失函数,然后求梯度更新参数。
优点:计算速度快
缺点:收敛性能不好
SGD可以看作是MBGD的一个特例,及batch_size=1的情况。
在深度学习及机器学习中,基本上都是使用的MBGD算法。
开始评估和预测:
# start evaluation
cost_eval = model.evaluate(x_test, y_test, batch_size=40)
print('evaluation lost %f' % cost_eval)
model.summary()
w, b = model.layers[0].get_weights()
print('weight %f , bias %f' % (w, b))
# start prediction
y_prediction = model.predict(x_test)
plt.scatter(x_test, y_test)
plt.plot(x_test, y_prediction)
plt.show()
输出结果:
