2018十篇精选AI论文摘要
https://mp.weixin.qq.com/s/4vD67EpxFTSLtUmiSmBNvw
NO TIME TO READ AI RESEARCH? WE SUMMARIZED TOP 2018 PAPERS FOR YOU
Posted by Mariya Yao | Nov 27, 2018
Trying to keep up with AI research papers can feel like an exercise in futility given how quickly the industry moves. If you’re buried in papers to read that you haven’t quite gotten around to, you’re in luck.
To help you catch up, we’ve summarized 10 important AI research papers from 2018 to give you a broad overview of machine learning advancements this year. There are many more breakthrough papers worth reading as well, but we think this is a good list for you to start with.
We’ve done our best to summarize these papers correctly, but if we’ve made any mistakes, please contact us to request a fix.
If these summaries of scientific AI research papers are useful for you, you can subscribe to our AI Research mailing list at the bottom of this article to be alerted when we release new summaries. We’re planning to release summaries of important papers in natural language processing (NLP) and computer vision in a few weeks.
If you’d like to skip around, here are the papers we featured:
-
Universal Language Model Fine-tuning for Text Classification
-
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
-
Deep Contextualized Word Representations
-
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
-
Delayed Impact of Fair Machine Learning
-
World Models
-
Taskonomy: Disentangling Task Transfer Learning
-
Know What You Don’t Know: Unanswerable Questions for SQuAD
-
Large Scale GAN Training for High Fidelity Natural Image Synthesis
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
10 IMPORTANT AI RESEARCH PAPERS OF 2018
1. UNIVERSAL LANGUAGE MODEL FINE-TUNING FOR TEXT CLASSIFICATION, BY JEREMY HOWARD AND SEBASTIAN RUDER (2018)
ORIGINAL ABSTRACT
Inductive transfer learning has greatly impacted computer vision, but existing approaches in NLP still require task-specific modifications and training from scratch. We propose Universal Language Model Fine-tuning (ULMFiT), an effective transfer learning method that can be applied to any task in NLP, and introduce techniques that are key for fine-tuning a language model. Our method significantly outperforms the state-of-the-art on six text classification tasks, reducing the error by 18-24% on the majority of datasets. Furthermore, with only 100 labeled examples, it matches the performance of training from scratch on 100x more data. We open source our pretrained models and code.
OUR SUMMARY
Howard and Ruder suggest using pre-trained models for solving a wide range of NLP problems. With this approach, you don’t need to train your model from scratch, but only fine-tune the original model. Their method, called Universal Language Model Fine-Tuning (ULMFiT) outperforms state-of-the-art results, reducing the error by 18-24%. Even more, with only 100 labeled examples, ULMFiT matches the performance of models trained from scratch on 10K labeled examples.
WHAT’S THE CORE IDEA OF THIS PAPER?
-
To address the lack of labeled data and to make NLP classification easier and less time-consuming, the researchers suggest applying transfer learning to NLP problems. Thus, instead of training the model from scratch, you can use another model that has been trained to solve a similar problem as the basis, and then fine-tune the original model to solve your specific problem.
-
However, to be successful, this fine-tuning should take into account several important considerations:
-
Different layers should be fine-tuned to different extents as they capture different kinds of information.
-
Adapting model’s parameters to task-specific features will be more efficient if the learning rate is firstly linearly increased and then linearly decayed.
-
Fine-tuning all layers at once is likely to result in catastrophic forgetting; thus, it would be better to gradually unfreeze the model starting from the last layer.
-
WHAT’S THE KEY ACHIEVEMENT?
-
Significantly outperforming state-of-the-art: reducing the error by 18-24%.
-
Much less labeled data needed: with only 100 labeled examples and 50K unlabeled, ULMFiT matches the performance of learning from scratch on 100x more data.
WHAT DOES THE AI COMMUNITY THINK?
-
Availability of pre-trained ImageNet models has transformed the field of computer vision. ULMFiT can be of the same importance for NLP problems.
-
This method can be applied to any NLP task in any language. The reports are coming from all over the world about significant improvements over state-of-the-art for multiple languages, including German, Polish, Hindi, Indonesian, Chinese, and Malay.
WHAT ARE FUTURE RESEARCH AREAS?
-
Improving language model pretraining and fine-tuning.
-
Applying this new method to novel tasks and models (e.g., sequence labeling, natural language generation, entailment or question answering).
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
-
ULMFiT can more efficiently solve a wide-range of NLP problems, including:
-
identifying spam, bots, offensive comments;
-
grouping articles by a specific feature;
-
classifying positive and negative reviews;
-
finding relevant documents etc.
-
-
Potentially, this method can also help with sequence-tagging and natural language generation.
2. OBFUSCATED GRADIENTS GIVE A FALSE SENSE OF SECURITY: CIRCUMVENTING DEFENSES TO ADVERSARIAL EXAMPLES, BY ANISH ATHALYE, NICHOLAS CARLINI, DAVID WAGNER (2018)
ORIGINAL ABSTRACT
We identify obfuscated gradients, a kind of gradient masking, as a phenomenon that leads to a false sense of security in defenses against adversarial examples. While defenses that cause obfuscated gradients appear to defeat iterative optimization-based attacks, we find defenses relying on this effect can be circumvented. We describe characteristic behaviors of defenses exhibiting the effect, and for each of the three types of obfuscated gradients we discover, we develop attack techniques to overcome it. In a case study, examining non-certified white-box-secure defenses at ICLR 2018, we find obfuscated gradients are a common occurrence, with 7 of 9 defenses relying on obfuscated gradients. Our new attacks successfully circumvent 6 completely, and 1 partially, in the original threat model each paper considers.
OUR SUMMARY
The researchers found that defenses against adversarial examples commonly use obfuscated gradients, which create a false sense of security because they can be easily circumvented. The study describes three ways in which defenses obfuscate gradients and shows which techniques can circumvent the defenses. The findings can help organizations that use defenses relying on obfuscated gradients to fortify their current methods.
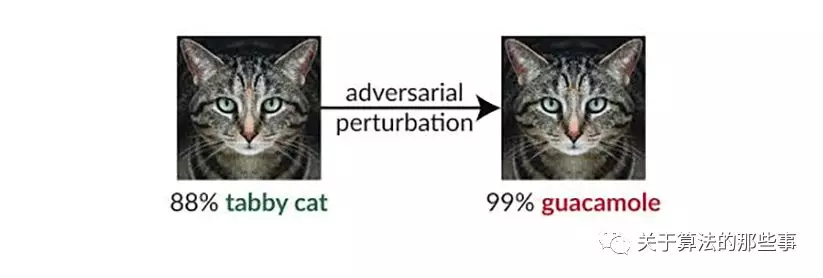
WHAT’S THE CORE IDEA OF THIS PAPER?
-
There are three common ways in which defenses obfuscate gradients:
-
shattered gradients are nonexistent or incorrect gradients caused by the defense either intentionally (through non-differentiable operations) or unintentionally (through numerical instability);
-
stochastic gradients are caused by randomized defenses;
-
vanishing/exploding gradients are caused by extremely deep neural network evaluation.
-
-
There are number of clues that something is wrong with the gradient including:
-
one-step attacks performing better than iterative attacks;
-
black-box attacks working better than white-box attacks;
-
unbounded attacks not reaching 100% success;
-
random sampling finding adversarial examples;
-
increasing distortion bound not leading to increased success.
-
WHAT’S THE KEY ACHIEVEMENT?
-
Demonstrating that most of the defense techniques used these days are vulnerable to attacks, namely:
-
7 out of 9 defense techniques accepted at ICLR 2018 cause obfuscated gradients;
-
new attack techniques developed by researchers were able to successfully circumvent 6 defenses completely and 1 partially.
-
WHAT DOES THE AI COMMUNITY THINK?
-
The paper won the Best Paper Award at ICML 2018, one of the key machine learning conferences.
-
The paper highlights the strengths and weaknesses of current technology.
WHAT ARE FUTURE RESEARCH AREAS?
-
To construct defenses with careful and thorough evaluation so that they can defend against not only existing attacks but also future attacks that may be developed.
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
-
By using the guidance provided in the research paper, organizations can identify if their defenses rely on obfuscated gradients and switch to more robust methods.
3. DEEP CONTEXTUALIZED WORD REPRESENTATIONS, BY MATTHEW E. PETERS, MARK NEUMANN, MOHIT IYYER, MATT GARDNER, CHRISTOPHER CLARK, KENTON LEE, LUKE ZETTLEMOYER (2018)
ORIGINAL ABSTRACT
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
OUR SUMMARY
The team from Allen Institute for Artificial Intelligence introduces a new type of deep contextualized word representation – Embeddings from Language Models (ELMo). In ELMO-enhanced models, each word is vectorized on the basis of the entire context in which it is used. Adding ELMo to the existing NLP systems results in 1) relative error reduction ranging from 6-20%, 2) a significantly lower number of epochs required to train the models and 3) a significantly reduced amount of training data needed to reach baseline performance.
WHAT’S THE CORE IDEA OF THIS PAPER?
-
To generate word embeddings as a weighted sum of the internal states of a deep bidirectional language model (biLM), pre-trained on a large text corpus.
-
To include representations from all layers of a biLM as different layers represent different types of information.
-
To base ELMo representations on characters so that the network can use morphological clues to “understand” out-of-vocabulary tokens unseen in training.
WHAT’S THE KEY ACHIEVEMENT?
-
Adding ELMo to the model leads to the new state-of-the-art results, with relative error reductions ranging from 6 – 20% across such NLP tasks as question answering, textual entailment, semantic role labeling, coreference resolution, named entity extraction, and sentiment analysis.
-
Enhancing the model with ELMo results in a significantly lower number of updates required to reach state-of-the-art performance. Thus, the Semantic Role Labeling (SRL) model with ELMo needs only 10 epochs to exceed the baseline maximum reached after 486 epochs of training.
-
Introducing ELMo to the model also significantly reduces the amount of training data needed to achieve the same level of performance. For example, for the SRL task, the ELMo-enhanced model needs only 1% of the training set to achieve the same performance as the baseline model with 10% of the training data.
WHAT DOES THE AI COMMUNITY THINK?
-
The paper was awarded as an Outstanding paper at NAACL, one of the most influential NLP conferences in the world.
-
The ELMo method introduced in the paper is considered as one of the greatest breakthroughs of 2018 and a staple in NLP for years to come.
WHAT ARE FUTURE RESEARCH AREAS?
-
Incorporating this method into specific tasks by concatenating ELMos with context-independent word embeddings.
-
Experimenting with concatenating ELMos with the output as well.
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
-
ELMo significantly improves the performance of existing NLP systems and thus enhances:
-
performance of chatbots that will be better at understanding humans and answering questions;
-
classifying positive and negative reviews of the customers;
-
finding relevant information and documents etc.
-
4. AN EMPIRICAL EVALUATION OF GENERIC CONVOLUTIONAL AND RECURRENT NETWORKS FOR SEQUENCE MODELING, BY SHAOJIE BAI, J. ZICO KOLTER, VLADLEN KOLTUN (2018)
ORIGINAL ABSTRACT
For most deep learning practitioners, sequence modeling is synonymous with recurrent networks. Yet recent results indicate that convolutional architectures can outperform recurrent networks on tasks such as audio synthesis and machine translation. Given a new sequence modeling task or dataset, which architecture should one use? We conduct a systematic evaluation of generic convolutional and recurrent architectures for sequence modeling. The models are evaluated across a broad range of standard tasks that are commonly used to benchmark recurrent networks. Our results indicate that a simple convolutional architecture outperforms canonical recurrent networks such as LSTMs across a diverse range of tasks and datasets, while demonstrating longer effective memory. We conclude that the common association between sequence modeling and recurrent networks should be reconsidered, and convolutional networks should be regarded as a natural starting point for sequence modeling tasks. To assist related work, we have made code available at http://github.com/locuslab/TCN.
OUR SUMMARY
The authors of this paper question the common assumption that recurrent architectures should be a default starting point for sequence modeling tasks. Their results suggest that generic temporal convolutional networks (TCNs) convincingly outperform canonical recurrent architectures such as long short-term memory networks (LSTMs) and gated recurrent unit networks (GRUs) across a broad range of sequence modeling tasks.
WHAT’S THE CORE IDEA OF THIS PAPER?
-
Temporal convolutional networks (TCNs) designed using the recently introduced best practices such as dilated convolutions and residual connections, significantly outperform generic recurrent architectures across a comprehensive suite of sequence modeling tasks.
-
TCNs exhibit substantially longer memory that recurrent architectures, and are thus more suitable for tasks where a long history is required.
WHAT’S THE KEY ACHIEVEMENT?
-
Providing an extensive systematic comparison of convolutional and recurrent architectures on sequence modeling tasks.
-
Designing a convolutional architecture that can serve as a convenient and still powerful starting point for sequence modeling tasks.
WHAT DOES THE AI COMMUNITY THINK?
-
“Always start with a CNN before reaching for an RNN. You’ll be surprised with how far you can get.” – Andrej Karpathy, Director of AI at Tesla.
WHAT ARE FUTURE RESEARCH AREAS?
-
Further architectural and algorithmic elaborations are needed to advance TCN’s performance across different sequence modeling tasks.
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
-
Introduction of TCNs can improve performance of AI systems relying on recurrent architectures for sequence modeling. This includes, among others, such tasks as:
-
machine translation;
-
speech recognition;
-
music and voice generation.
-
5. DELAYED IMPACT OF FAIR MACHINE LEARNING, BY LYDIA T. LIU, SARAH DEAN, ESTHER ROLF, MAX SIMCHOWITZ, MORITZ HARDT (2018)
ORIGINAL ABSTRACT
Fairness in machine learning has predominantly been studied in static classification settings without concern for how decisions change the underlying population over time. Conventional wisdom suggests that fairness criteria promote the long-term well-being of those groups they aim to protect.
We study how static fairness criteria interact with temporal indicators of well-being, such as long-term improvement, stagnation, and decline in a variable of interest. We demonstrate that even in a one-step feedback model, common fairness criteria in general do not promote improvement over time, and may in fact cause harm in cases where an unconstrained objective would not. We completely characterize the delayed impact of three standard criteria, contrasting the regimes in which these exhibit qualitatively different behavior. In addition, we find that a natural form of measurement error broadens the regime in which fairness criteria perform favorably.
Our results highlight the importance of measurement and temporal modeling in the evaluation of fairness criteria, suggesting a range of new challenges and trade-offs.
OUR SUMMARY
The goal is to ensure fair treatment across different demographic groups when using a score-based machine learning algorithm to decide who gets an opportunity (e.g., loan, scholarship, job) and who does not. Researchers from Berkeley’s Artificial Intelligence Research lab show that using common fairness criteria may in fact harm underrepresented or disadvantaged groups due to certain delayed outcomes. Thus, they encourage looking at the long-term outcomes when designing a “fair” machine-learning system.
WHAT’S THE CORE IDEA OF THIS PAPER?
-
Considering delayed outcomes of imposing fairness criteria reveals that these criteria may have an adverse impact on the long-term well-being of those groups they aim to protect (e.g., worsening the credit score of the borrower, who was not able to repay the loan that wouldn’t be granted in the unconstrained setting).
-
Since fairness criteria may actively harm disadvantaged groups, the solution can be to use a decision rule which involves the explicit maximization of the outcomes, or an outcome model.
WHAT’S THE KEY ACHIEVEMENT?
-
Showing that such fairness criteria as demographic parity and equal opportunity fairness can lead to any possible outcomes for the disadvantaged group, including improvement, stagnation, and decline, while following the institution’s optimal unconstrained selection policy (e.g., profit maximization) will never lead to decline (active harm) for the disadvantaged group.
-
Supporting theoretical predictions with experiments on FICO credit score data.
-
Considering alternatives to hard fairness constraints.
WHAT DOES THE AI COMMUNITY THINK?
-
The paper won the Best Paper Award at ICML 2018, one of the key machine learning conferences.
-
The study reveals that positive discrimination can sometimes backfire.
WHAT ARE FUTURE RESEARCH AREAS?
-
Considering the other characteristics of impact beyond the change in population mean (e.g., variance, individual-level outcomes).
-
Researching the robustness of outcome optimization to modeling and measurement errors.
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
-
By switching from constraints imposed by fairness criteria to outcome modeling, companies might develop ML systems for lending or recruiting that will be more profitable and yet “fairer”.
6. WORLD MODELS, BY DAVID HA AND JURGEN SCHMIDHUBER (2018)
ORIGINAL ABSTRACT
We explore building generative neural network models of popular reinforcement learning environments. Our world model can be trained quickly in an unsupervised manner to learn a compressed spatial and temporal representation of the environment. By using features extracted from the world model as inputs to an agent, we can train a very compact and simple policy that can solve the required task. We can even train our agent entirely inside of its own hallucinated dream generated by its world model, and transfer this policy back into the actual environment.
An interactive version of this paper is available at https://worldmodels.github.io.
OUR SUMMARY
Ha and Schmidhuber develop a world model that can be quickly trained in an unsupervised manner to learn spatial and temporal representations of the environment. The agent succeeded in navigating the race track in the Car Racing task and avoiding the fireballs shot by monsters in the VizDom experiment. These tasks were too challenging for previous methods.
WHAT’S THE CORE IDEA OF THIS PAPER?
-
The solution consists of three distinct parts:
-
A variational autoencoder (VAE) responsible for capturing visual information. It condenses an RGB input image into a 32-dimensional latent vector that follows a Gaussian distribution. Thus, the agent can work with a much smaller representation of the environment and therefore can be more efficient in its learning.
-
A recurrent neural network (RNN) responsible for forward thinking. This is a memory component that tries to predict what the next picture captured by the visual component might look like considering the previous picture and the previous action.
-
A controller responsible for choosing an action. This is a simple neural network that concatenates the output from VAE and the hidden state of the RNN and selects good action.
-
WHAT’S THE KEY ACHIEVEMENT?
-
This is the first known agent to solve the popular ‘Car Racing’ reinforcement learning environment.
-
The study demonstrates the possibility of training an agent to perform tasks entirely inside of its simulated latent space dream world.
WHAT DOES THE AI COMMUNITY THINK?
-
The paper was widely discussed in the AI community as a beautiful work on using neural networks in reinforcement learning and training agents in their own “hallucinated” worlds.
WHAT ARE FUTURE RESEARCH AREAS?
-
Enabling the agent to explore more complicated worlds by replacing the small RNN with higher capacity models or incorporating an external memory module.
-
Experimenting with more general approaches which allow for hierarchical planning instead of “time step by time step” approach presented here.
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
-
When running computationally intensive game engines, it is now possible to train the agent as many times as needed inside its simulated environment instead of wasting heavy compute resources training an agent in the actual environment.
7. TASKONOMY: DISENTANGLING TASK TRANSFER LEARNING, BY AMIR R. ZAMIR, ALEXANDER SAX, WILLIAM SHEN, LEONIDAS J. GUIBAS, JITENDRA MALIK, AND SILVIO SAVARESE (2018)
ORIGINAL ABSTRACT
Do visual tasks have a relationship, or are they unrelated? For instance, could having surface normals simplify estimating the depth of an image? Intuition answers these questions positively, implying existence of a structure among visual tasks. Knowing this structure has notable values; it is the concept underlying transfer learning and provides a principled way for identifying redundancies across tasks, e.g., to seamlessly reuse supervision among related tasks or solve many tasks in one system without piling up the complexity.
We propose a fully computational approach for modeling the structure of space of visual tasks. This is done via finding (first and higher-order) transfer learning dependencies across a dictionary of twenty six 2D, 2.5D, 3D, and semantic tasks in a latent space. The product is a computational taxonomic map for task transfer learning. We study the consequences of this structure, e.g. nontrivial emerged relationships, and exploit them to reduce the demand for labeled data. For example, we show that the total number of labeled datapoints needed for solving a set of 10 tasks can be reduced by roughly 2/3 (compared to training independently) while keeping the performance nearly the same. We provide a set of tools for computing and probing this taxonomical structure including a solver that users can employ to devise efficient supervision policies for their use cases.
OUR SUMMARY
Assertions of existence of a structure among visual tasks have been made by many researchers since the early years of modern computer science. And now Amir Zamir and his team make an attempt to actually find this structure. They model it using a fully computational approach and discover lots of useful relationships between different visual tasks, including nontrivial ones. They also show that by taking advantage of these interdependencies, it is possible to achieve the same model performance with the labeled data requirements reduced by roughly ⅔.
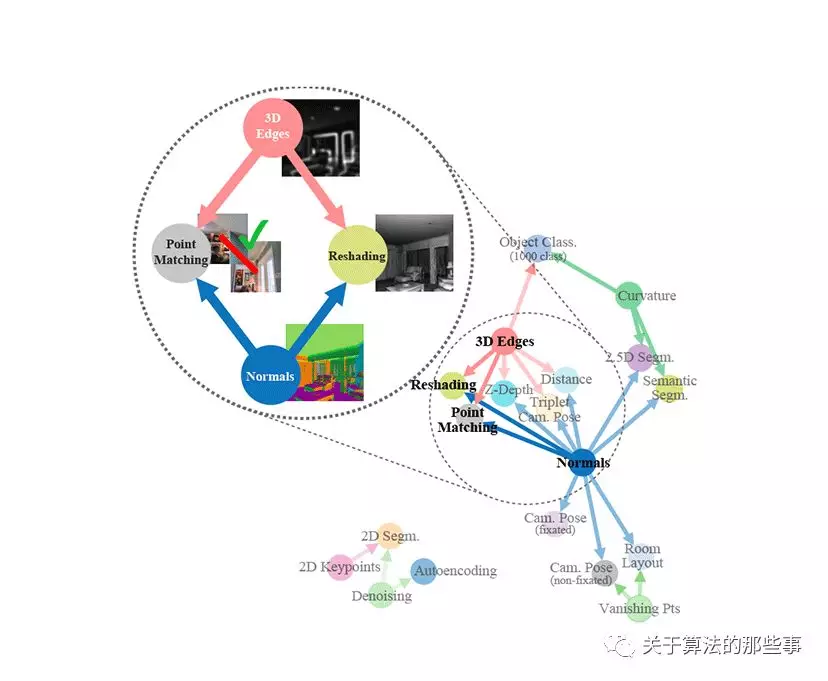
WHAT’S THE CORE IDEA OF THIS PAPER?
-
A model aware of the relationships among different visual tasks demands less supervision, uses less computation, and behaves in more predictable ways.
-
A fully computational approach to discovering the relationships between visual tasks is preferable because it avoids imposing prior, and possibly incorrect, assumptions: the priors are derived from either human intuition or analytical knowledge, while neural networks might operate on different principles.
WHAT’S THE KEY ACHIEVEMENT?
-
Identifying relationships between 26 common visual tasks, such as object recognition, depth estimation, edge detection, and pose estimation.
-
Showing how this structure helps in discovering types of transfer learning that will be most effective for each visual task.
WHAT DOES THE AI COMMUNITY THINK?
-
The paper won the Best Paper Award at CVPR 2018, the key conference on computer vision and pattern recognition.
-
The results are very important since for most real-world tasks large-scale labeled datasets are not available.
WHAT ARE FUTURE RESEARCH AREAS?
-
To move from a model where common visual tasks are entirely defined by humans and try an approach where human-defined visual tasks are viewed as observed samples which are composed of computationally found latent subtasks.
-
Exploring the possibility to transfer the findings to not entirely visual tasks, e.g. robotic manipulation.
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
-
Relationships discovered in this paper can be used to build more effective visual systems that will require less labeled data and lower computational costs.
8. KNOW WHAT YOU DON’T KNOW: UNANSWERABLE QUESTIONS FOR SQUAD, BY PRANAV RAJPURKAR, ROBIN JIA, AND PERCY LIANG (2018)
ORIGINAL ABSTRACT
Extractive reading comprehension systems can often locate the correct answer to a question in a context document, but they also tend to make unreliable guesses on questions for which the correct answer is not stated in the context. Existing datasets either focus exclusively on answerable questions, or use automatically generated unanswerable questions that are easy to identify. To address these weaknesses, we present SQuAD 2.0, the latest version of the Stanford Question Answering Dataset (SQuAD). SQuAD 2.0 combines existing SQuAD data with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD 2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering. SQuAD 2.0 is a challenging natural language understanding task for existing models: a strong neural system that gets 86% F1 on SQuAD 1.1 achieves only 66% F1 on SQuAD 2.0.
OUR SUMMARY
A Stanford University research group extends the famous Stanford Question Answering Dataset (SQuAD) with over 50,000 unanswerable questions. The answers to these questions cannot be found in the supporting paragraphs, yet the questions look very similar to the answerable questions. Even more, the supporting paragraphs contain plausible (but incorrect) answers to these questions. This makes the new SQuAD 2.0 extremely challenging for existing state-of-the-art models: a strong neural system that achieves an accuracy of 86% on the previous version of SQuAD gets only 66% after the unanswerable questions are introduced.
WHAT’S THE CORE IDEA OF THIS PAPER?
-
Current Natural Language Understanding (NLU) systems are far from true language understanding, and one of the root causes for this is that existing Q&A datasets focus on questions for which a correct answer is guaranteed to exist in the context document.
-
To be really challenging, unanswerable questions should be created so that:
-
they are relevant to the supporting paragraph;
-
the paragraph contains a plausible answer which contains information of the same type as what the question asks for, but is incorrect.
-
WHAT’S THE KEY ACHIEVEMENT?
-
Extending SQuAD with 53,777 new, unanswerable questions, and thus building a challenging, large-scale dataset that forces the NLU systems to understand when a question cannot be answered given the context.
-
Creating a new challenge for NLU systems by showing that existing models (with 66% of accuracy) are closer to a baseline that always abstains (48.9%) than to human accuracy (89.5%).
-
Showing that plausible answers do indeed act as effective distractors for NLU systems.
WHAT DOES THE AI COMMUNITY THINK?
-
The paper was announced as the Best Short Paper by the Association for Computational Linguistics (ACL) 2018.
-
The new dataset adds complexity to the NLU field and can actually contribute to a huge performance training boost in this research area.
WHAT ARE FUTURE RESEARCH AREAS?
-
Development of new models that “know what they don’t know,” and thus get a better understanding of natural language.
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
-
Training reading comprehension models on this new dataset should improve their performance in the real-world scenarios where the answers are often not directly available.
9. LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS, BY ANDREW BROCK, JEFF DONAHUE, AND KAREN SIMONYAN (2018)
ORIGINAL ABSTRACT
Despite recent progress in generative image modeling, successfully generating high-resolution, diverse samples from complex datasets such as ImageNet remains an elusive goal. To this end, we train Generative Adversarial Networks at the largest scale yet attempted, and study the instabilities specific to such scale. We find that applying orthogonal regularization to the generator renders it amenable to a simple “truncation trick”, allowing fine control over the trade-off between sample fidelity and variety by truncating the latent space. Our modifications lead to models which set the new state of the art in class-conditional image synthesis. When trained on ImageNet at 128×128 resolution, our models (BigGANs) achieve an Inception Score (IS) of 166.3 and Frechet Inception Distance (FID) of 9.6, improving over the previous best IS of 52.52 and FID of 18.65.
OUR SUMMARY
A DeepMind team finds that current techniques are sufficient for synthesizing high-resolution, diverse images from available datasets such as ImageNet and JFT-300M. In particular, they show that Generative Adversarial Networks (GANs) can generate images that look very realistic if they are trained at a very large scale, i.e. using two to four times as many parameters and eight times the batch size compared to prior experiments. These large-scale GANs, or BigGANs, are the new state-of-the-art in class-conditional image synthesis.

WHAT’S THE CORE IDEA OF THIS PAPER?
-
GANs perform much better with increased batch size and number of parameters.
-
Applying orthogonal regularization to the generator makes the model responsive to a specific technique (“truncation trick”), which provides control over the trade-off between sample fidelity and variety.
WHAT’S THE KEY ACHIEVEMENT?
-
Demonstrating that GANs can benefit significantly from scaling.
-
Building models that allow explicit, fine-grained control of the trade-off between sample variety and fidelity.
-
Discovering instabilities of large-scale GANs and characterizing them empirically.
-
BigGANs trained on ImageNet at 128×128 resolutions achieve:
-
an Inception Score (IS) of 166.3 with the previous best IS of 52.52;
-
Frechet Inception Distance (FID) of 9.6 with the previous best FID of 18.65.
-
WHAT DOES THE AI COMMUNITY THINK?
-
The paper is under review for the next ICLR 2019.
-
After BigGAN generators became available on TF Hub, AI researchers from all over the world are playing with BigGANs to generate dogs, watches, bikini images, Mona Lisa, seashores and many more subjects.
WHAT ARE FUTURE RESEARCH AREAS?
-
Moving to larger datasets to mitigate GAN stability issues.
-
Exploring the possibilities to reduce the amount of weird samples generated by GANs.
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
-
Replacing expensive manual media creation for advertising and e-commerce purposes
10. BERT: PRE-TRAINING OF DEEP BIDIRECTIONAL TRANSFORMERS FOR LANGUAGE UNDERSTANDING, BY JACOB DEVLIN, MING-WEI CHANG, KENTON LEE, AND KRISTINA TOUTANOVA (2018)
ORIGINAL ABSTRACT
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE benchmark to 80.4% (7.6% absolute improvement), MultiNLI accuracy to 86.7 (5.6% absolute improvement) and the SQuAD v1.1 question answering Test F1 to 93.2 (1.5% absolute improvement), outperforming human performance by 2.0%.
OUR SUMMARY
Google AI team presents a new cutting-edge model for Natural Language Processing (NLP) – BERT, or Bidirectional Encoder Representations from Transformers. Its design allows the model to consider the context from both left and right sides of each word. While being conceptually simple, BERT obtains new state-of-the-art results on eleven NLP tasks, including question answering, named entity recognition and other tasks related to general language understanding.
WHAT’S THE CORE IDEA OF THIS PAPER?
-
Training a deep bidirectional model by randomly masking a percentage of input tokens – thus, avoiding cycles where words can indirectly “see themselves”.
-
Also pre-training a sentence relationship model by building a simple binary classification task to predict whether sentence B immediately follows sentence A, thus allowing BERT to better understand relationships between sentences.
-
Training a very big model (24 Transformer blocks, 1024-hidden, 340M parameters) with lots of data (3.3 billion word corpus).
WHAT’S THE KEY ACHIEVEMENT?
-
Advancing the state-of-the-art for 11 NLP tasks, including:
-
getting a GLUE score of 80.4%, which is 7.6% of absolute improvement from the previous best result;
-
achieving 93.2% accuracy on SQuAD 1.1 and outperforming human performance by 2%.
-
-
Suggesting a pre-trained model, which doesn’t require any substantial architecture modifications to be applied to specific NLP tasks.
WHAT DOES THE AI COMMUNITY THINK?
-
BERT model marks a new era of NLP.
-
In a nutshell, two unsupervised tasks together (“fill in the blank” and “does sentence B comes after sentence A?”) provide great results for many NLP tasks.
-
Pre-training of language models becomes a new standard.
WHAT ARE FUTURE RESEARCH AREAS?
-
Testing the method on a wider range of tasks.
-
Investigating the linguistic phenomena that may or may not be captured by BERT.
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
-
BERT may assist businesses with a wide range of NLP problems, including:
-
chatbots for better customer experience;
-
analysis of customer reviews;
-
search of relevant information etc.
-