TextBoxes++论文阅读笔记
TextBoxes++论文阅读笔记
文章目录
- TextBoxes++论文阅读笔记
- 摘要
- 主要贡献
- 相关工作
- 网络
- 网络结构
- 多偏置的default boxes
- 各种框表示方法的转换方式
- 卷积层的改变
- 训练中的特殊处理
- 1.如何表示ground truth
- 2.loss functon
- 3.On-line hard negative mining(在线难力挖掘):
- 4.Data Augmentation数据增强
- 5.Multi-scale training
- 6.Testing with efficient cascaded non-maximum suppression
- 7.文字识别和文字定位的结合
- 8.实验
- 9.评估方法
- 10.实施细节
摘要
Different from general object detection, the main challenges of scene text detection lie on arbitrary orientations, small sizes, and significantly variant aspect ratios of text in natural images.提出了一种端到端的text detection方法,又快又准。除了nms没有其他后处理过程。
主要贡献
- 1.用四边形或者矩形表示文本框 ;
- 2 :为defaut boxes设置上下偏置,方便预测临近的文本;
- 3 :修改卷积核, we adapt(修改) the convolution kernels to better handle text lines which are usually long objects as compared to general object detection;将卷积核大小由3X3修改到3X5。
- 4 :文本定位之后添加一个文字识别(用的CRNN网络)的过程,根据文本识别的效果,反馈给detection网络,帮助更好的detection。比如确定不是文字的部分,可以从结果中删除。
- 5:More comparative experiments have been conducted to further demonstrate the efficiency of TextBoxes++ in detecting arbitrary-oriented text in natural images;在很多数据集上测试过。
- 6:TextBoxes++ detects oriented text at 6 different scales in 6 stages. 在6个尺度上做检测,对检测结果做做nms。
相关工作
detection方法主要分为RCNN和yolo流派
text detection:
Textboxes++的
网络结构
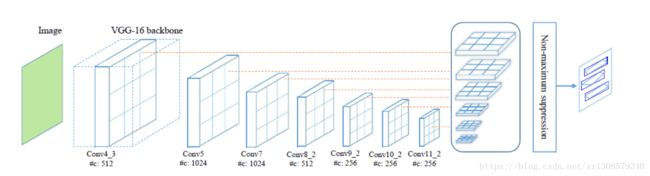
网络
网络结构
如上图所示,采用最基本的VGG16,保留了conv1_1到conv5_3,将最后两层由全连接层替换成了卷积层,另外加了8个卷积层。某些层通过textboxes layers之后预测输出,然后nms处理,所以textboxes++只包含卷积层和pooling层,因此可以使用不同尺度的输入。
多偏置的default boxes
ext-layer是网络的核心,default boxes是矩形的,输出四边形预测框{q}或者{r},以及最小的外接矩形框{b}。预测的是框相对于default boxes的offsets。预测过程如下图所示:
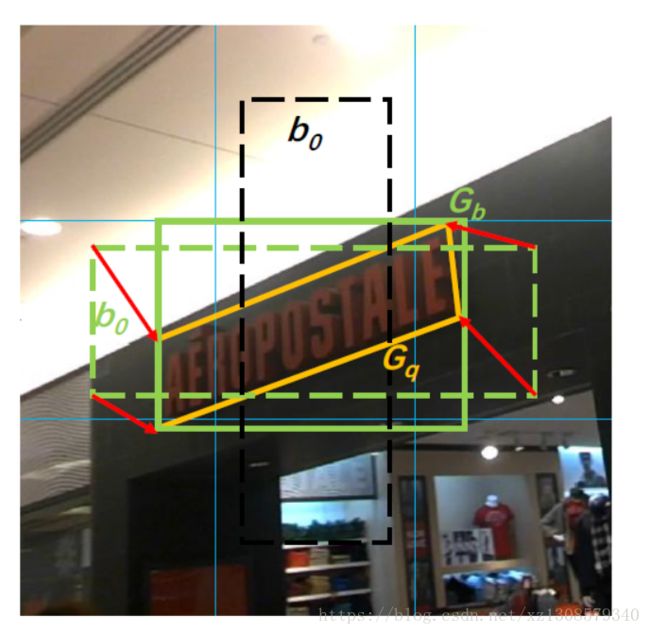
黄色实线是ground truth,绿色虚线是匹配上的default box,红色箭头表示学习过程,这是在3*3的图像上的结果,Note that the black dashed(黑色虚线) default box is not matched to the ground truth. The regression from the matched default box to the minimum horizontal rectangle (green solid) containing the ground truth quadrilateral is not shown for a better visualization.
也就是default boxes绿色虚线框同时回归黄色ground boxes和绿色的最小外接框
各种框表示方法的转换方式
首先就是对于文本框的表示方式发生了变化。论文中讨论了两种表示方式:分别是4个点坐标8个数字(x1,y1,x2,y2,x3,y3,x4,y4)和左上和右上两个点四个坐标外加四边形的高(x1,y1,x2,y2,h)。但论文推荐使用四个坐标的表示方式。

网络预测的结果是

在训练阶段,最小外接框帮助我们更好的匹配default boxes,我们的默认框最好和text的实际框相一致,所以default boxes的尺寸设计非常重要。
text经常有很大的长宽比,我们定义了1,2,3,5,7,10,六种默认的长宽比,由于不仅仅检测水平的text,我们加入了1,2,3,5,1/2,//3,1/5特殊的长宽比,由于文本经常集中在某些区域,所以我们给默认框加入偏置让它更好的预测临近物体。如下图所示:黑色默认框是无法是无法处理两个靠的很近的物体,所以我们加偏置形成了黄色框。

卷积层的改变
text boxes通常是很长的物体,所以有人用1x5的卷积核做卷积,由于我们的是多角度的所以我们使用了3X5的卷积核取代3X3的卷积核。
训练中的特殊处理
1.如何表示ground truth



2.loss functon

3.On-line hard negative mining(在线难力挖掘):
Some textures and signs are very similar to text, which are hard for the network to distinguish. We follow the hard negative mining strategy used n [10] to suppress(压制) them. 不好区分的容易混淆的纹理在线难力区分,More precisely, the training on thecorresponding dataset is divided into two stages. The ratio between the negatives and positives for the first stage is set to3:1, and then changed to 6:1 for the second stage.
4.Data Augmentation数据增强
5.Multi-scale training
6.Testing with efficient cascaded non-maximum suppression
测试的时候改进了nms,将6个尺度的图片归一化,进行nms,由于四边形的nms耗时较多,我们将nms分成了两步执行
- 1进行nms在最小外接框上,设置threshold= 0.5,这一步很快并且消除了大量框。
- 2 :四边形nms设置tnreshold = 0.2
输出作为预测结果。
7.文字识别和文字定位的结合
文本识别可以消除一些假的框,当假框内没有字的时候,Following this intuitive idea, we propose to improve the detection results of TextBoxes++ with word spotting and end-to-end recognition
使用RCNN做文字识别结果反馈给detectio帮助去除一些detection的框
8.实验
我们在ICDAR2015和Text(IC15)上测试了效果,为了验证泛化能力,我们又在ICDAR2013和SVT上进行了测试,除此之外,使用了SynthText进行预训练
9.评估方法
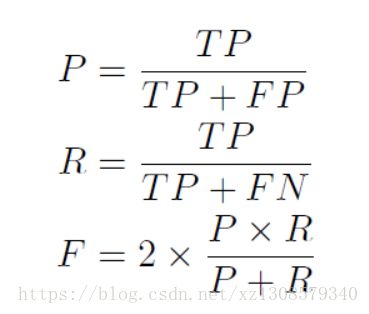
iou大于某个值认为为正例。
F值是最流行的评价标准。
10.实施细节
lr是学习率,s输入图像多少是size,nr是反例和正例的比例,#iter是迭代的轮次。
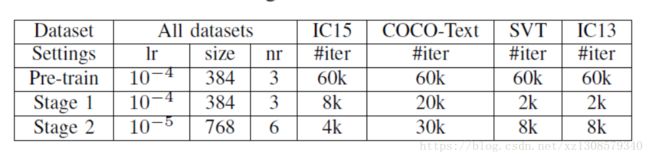
使用Aadm梯度下降算法,分为三个训练阶段
- 1.we pre-train TextBoxes++ on SynthText dataset for all tested datasets.
- 2 :hen the training process is continued on the corresponding training images of each dataset
- 3:we continue this training with a smaller learning rate and a larger negative ratio.
All the experiments presented in this paper are carried out on a PC equipped with a single Titan Xp GPU. The wholetraining process (including the pre-training time on SynthText
dataset) takes about 2 days on ICDAR 2015 Incidental Text dataset, which is currently the most tested dataset.