在上一篇文章Java设计模式综合运用(门面+模版方法+责任链+策略)中,笔者写了一篇门面模式、模版方法、责任链跟策略模式的综合运用的事例文章,但是后来笔者发现,在实现策略模式的实现上,发现了一个弊端:那就是如果在后续业务发展中,需要再次增加一个业务策略的时候,则需要再次继承
AbstractValidatorHandler类(详情请参见上篇文章),这样就会造成一定的类膨胀。今天我利用注解的方式改造成动态策略模式,这样就只需要关注自己的业务类即可,无需再实现一个类似的Handler类。
1. 项目背景
1.1 项目简介
在公司的一个业务系统中,有这样的一个需求,就是根据不同的业务流程,可以根据不同的组合主键策略进行动态的数据业务查询操作。在本文中,我假设有这样两种业务,客户信息查询和订单信息查询,对应以下枚举类:
/**
* 业务流程枚举
* @author landyl
* @create 11:18 AM 05/07/2018
*/
public enum WorkflowEnum {
ORDER(2),
CUSTOMER(3),
;
....
}
每种业务类型都有自己的组合主键查询规则,并且有自己的查询优先级,比如客户信息查询有以下策略:
- customerId
- requestId
- birthDate+firstName
以上仅是假设性操作,实际业务规则比这复杂的多
1.2 流程梳理
主要业务流程,可以参照以下简单的业务流程图。
1.2.1 查询抽象模型
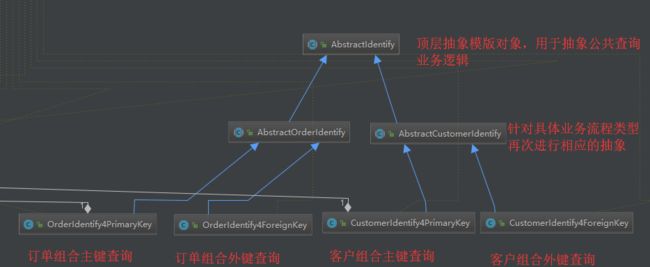
1.2.2 组合主键查询策略

1.2.3 组合主键查询责任链

2. Java注解简介
注解的语法比较简单,除了@符号的使用之外,它基本与Java固有语法一致。
2.1 元注解
JDK1.5提供了4种标准元注解,专门负责新注解的创建。
| 注解 | 说明 |
|---|---|
| @Target | 表示该注解可以用于什么地方,可能的ElementType参数有: CONSTRUCTOR:构造器的声明 FIELD:域声明(包括enum实例) LOCAL_VARIABLE:局部变量声明 METHOD:方法声明 ACKAGE:包声明 PARAMETER:参数声明 TYPE:类、接口(包括注解类型)或enum声明 |
| @Retention | 表示需要在什么级别保存该注解信息。可选的RetentionPolicy参数包括: SOURCE:注解将被编译器丢弃 CLASS:注解在class文件中可用,但会被VM丢弃 RUNTIME:JVM将在运行期间保留注解,因此可以通过反射机制读取注解的信息。 |
| @Document | 将注解包含在Javadoc中 |
| @Inherited | 允许子类继承父类中的注解 |
2.2 自定义注解
定义一个注解的方式相当简单,如下代码所示:
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
//使用@interface关键字定义注解
public @interface Description {
/*
* 注解方法的定义(其实在注解中也可以看做成员变量)有如下的规定:
* 1.不能有参数和抛出异常
* 2.方法返回类型只能为八种基本数据类型和字符串,枚举和注解以及这些类型构成的数组
* 3.可以包含默认值,通过default实现
* 4.如果只有一个方法(成员变量),最好命名为value
*/
String value();
int count() default 1; //默认值为1
}
注解的可用的类型包括以下几种:所有基本类型、String、Class、enum、Annotation、以上类型的数组形式。元素不能有不确定的值,即要么有默认值,要么在使用注解的时候提供元素的值。而且元素不能使用null作为默认值。注解在只有一个元素且该元素的名称是value的情况下,在使用注解的时候可以省略“value=”,直接写需要的值即可。
2.3 使用注解
如上所示的注解使用如下:
/**
* @author landyl
* @create 2018-01-12:39 PM
*/
//在类上使用定义的Description注解
@Description(value="class annotation",count=2)
public class Person {
private String name;
private int age;
//在方法上使用定义的Description注解
@Description(value="method annotation",count=3)
public String speak() {
return "speaking...";
}
}
使用注解最主要的部分在于对注解的处理,那么就会涉及到注解处理器。从原理上讲,注解处理器就是通过反射机制获取被检查方法上的注解信息,然后根据注解元素的值进行特定的处理。
/**
* @author landyl
* @create 2018-01-12:35 PM
* 注解解析类
*/
public class ParseAnnotation {
public static void main(String[] args){
//使用类加载器加载类
try {
Class c = Class.forName("com.annatation.Person");//加载使用了定义注解的类
//找到类上的注解
boolean isExist = c.isAnnotationPresent(Description.class);
if(isExist){
//拿到注解示例
Description d = (Description)c.getAnnotation(Description.class);
System.out.println(d.value());
}
//找到方法上的注解
Method[] ms = c.getMethods();
for(Method m : ms){
boolean isMExist = m.isAnnotationPresent(Description.class);
if(isMExist){
Description d = m.getAnnotation(Description.class);
System.out.println(d.value());
}
}
//另外一种注解方式
for(Method m:ms){
Annotation[] as = m.getAnnotations();
for(Annotation a:as){
if(a instanceof Description){
Description d = (Description)a;
System.out.println(d.value());
}
}
}
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
3. 策略模式升级版
3.1 策略模式实现方式
- 使用工厂进行简单的封装
- 使用注解动态配置策略
- 使用模版方法模式配置策略(参见Java设计模式综合运用(门面+模版方法+责任链+策略))
- 使用工厂+注解方式动态配置策略(利用Spring加载)
其中第1、2点请参见org.landy.strategy 包下的demo事例即可,而第4点的方式其实就是结合第1、2、3点的优点进行整合的方式。
3.2 注解方式优点
使用注解方式可以极大的减少使用模版方法模式带来的扩展时需要继承模版类的弊端,工厂+注解的方式可以无需关心其他业务类的实现,而且减少了类膨胀的风险。
3.3 组合主键查询策略
本文以组合主键查询策略这一策略进行说明,策略注解如下:
/**
* 组合主键查询策略(根据不同业务流程区分组合主键查询策略,并且每个业务流程都有自己的优先级策略)
* @author landyl
* @create 2:22 PM 09/29/2018
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface KeyIdentificationStrategy {
/**
* 主键策略优先级
* @return
*/
int priority() default 0;
/**
* 业务流程类型(如:订单信息,会员信息等业务流程)
* @return
*/
WorkflowEnum workflowId();
/**
* the spring bean name
* @return
*/
String beanName();
}
3.4 策略工厂
既然定义了组合主键查询策略注解,那必然需要一个注解处理器进行解析注解的操作,本文以工厂的方式进行。主要逻辑如下:
-
扫描指定包下的Java类,找出相应接口(即
KeyIdentification)下的所有Class对象。private ListpackageNames = this.getBasePackages(); List -
解析注解
KeyIdentificationStrategy,定义一个排序对象(KeyIdentificationComparator),指定优先级。/** * define a comparator of the KeyIdentification object through the priority of the IdentifyPriority for sort purpose. * @see KeyIdentificationStrategy */ private class KeyIdentificationComparator implements Comparator { @Override public int compare(Object objClass1, Object objClass2) { if(objClass1 != null && objClass2 != null) { OptionalstrategyOptional1 = getPrimaryKeyIdentificationStrategy((Class)objClass1); Optional strategyOptional2 = getPrimaryKeyIdentificationStrategy((Class)objClass2); KeyIdentificationStrategy ip1 = strategyOptional1.get(); KeyIdentificationStrategy ip2 = strategyOptional2.get(); Integer priority1 = ip1.priority(); Integer priority2 = ip2.priority(); WorkflowEnum workflow1 = ip1.workflowId(); WorkflowEnum workflow2 = ip2.workflowId(); //先按业务类型排序 int result = workflow1.getValue() - workflow2.getValue(); //再按优先级排序 if(result == 0) return priority1.compareTo(priority2); return result; } return 0; } } -
根据注解,把相应业务类型的组合主键查询策略对象放入容器中(即
DefaultKeyIdentificationChain)。KeyIdentificationStrategy strategy = strategyOptional.get(); String beanName = strategy.beanName(); //业务流程类型 WorkflowEnum workflowId = strategy.workflowId(); KeyIdentificationStrategy priority = getPrimaryKeyIdentificationStrategy(v).get(); LOGGER.info("To add identification:{},spring bean name is:{},the identify priority is:{},workflowId:{}",simpleName,beanName,priority.priority(),workflowId.name()); KeyIdentification instance = ApplicationUtil.getApplicationContext().getBean(beanName,v); defaultKeyIdentificationChain.addIdentification(instance,workflowId); 后续,在各自对应的业务查询组件对象中即可使用该工厂对象调用如下方法,即可进行相应的查询操作。
public IdentificationResultType identify(IdentifyCriterion identifyCriterion,WorkflowEnum workflowId) {
//must set the current workflowId
defaultKeyIdentificationChain.doClearIdentificationIndex(workflowId);
return defaultKeyIdentificationChain.doIdentify(identifyCriterion,workflowId);
}
4. 总结
以上就是本人在实际工作中,对第一阶段使用到的设计模式的一种反思后得到的优化结果,可能还有各种不足,但是个人感觉还是有改进,希望大家也不吝赐教,大家一起进步才是真理。
代码地址:https://github.com/landy8530/DesignPatterns (欢迎Star)