一、各种进制的相互转换
先比比一下二进制的缺点,移植性差。
一、正整数的十进制转换二进制:要点:除二取余,倒序排列
解释:将一个十进制数除以二,得到的商再除以二,依此类推直到商等于一或零时为止,倒取将除得的余数,即换算为二进制数的结果
例如把52换算成二进制数,计算结果如图:
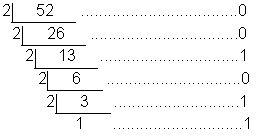
52除以2得到的余数依次为:0、0、1、0、1、1,倒序排列,所以52对应的二进制数就是110100。
由于计算机内部表示数的字节单位都是定长的,以2的幂次展开,或者8位,或者16位,或者32位....。
于是,一个二进制数用计算机表示时,位数不足2的幂次时,高位上要补足若干个0。本文都以8位为例。那么:
(52)10=(00110100)2
二、负整数转换为二进制
要点:(正数除二取余,倒序排列)取反加一
解释:将该负整数对应的正整数先转换成二进制,然后对其“取补”,再对取补后的结果加1即可
例如要把-52换算成二进制:
1.先取得52的二进制:00110100
2.对所得到的二进制数取反:11001011
3.将取反后的数值加一即可:11001100
即:(-52)10=(11001100)2
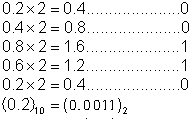
三、小数转换为二进制
要点:(小数)乘二取整,正序排列
解释:对被转换的小数乘以2,取其整数部分(0或1)作为二进制小数部分,取其小数部分,再乘以2,又取其整数部分作为二进制小数部分,然后取小数部分,再乘以2,直到小数部分为0或者已经去到了足够位数。每次取的整数部分,按先后次序排列,就构成了二进制小数的序列
例如把0.2转换为二进制,转换过程如图:

0.2乘以2,取整后小数部分再乘以2,运算4次后得到的整数部分依次为0、0、1、1,结果又变成了0.2,
若果0.2再乘以2后会循环刚开始的4次运算,所以0.2转换二进制后将是0011的循环,即:
(0.2)10=(0.0011 0011 0011 .....)2
循环的书写方法为在循环序列的第一位和最后一位分别加一个点标注
四、二进制转换为十进制:
整数二进制用数值乘以2的幂次依次相加,小数二进制用数值乘以2的负幂次然后依次相加!
比如将二进制110转换为十进制:
首先补齐位数,00000110,首位为0,则为正整数,那么将二进制中的三位数分别于下边对应的值相乘后相加得到的值为换算为十进制的结果

如果二进制数补足位数之后首位为1,那么其对应的整数为负,那么需要先取反然后再换算(这里显然他的方法是错的,应该取反后加1)
比如11111001,首位为1,那么需要先对其取反,即:-00000110
00000110,对应的十进制为6,因此11111001对应的十进制即为-6
换算公式可表示为:
11111001=-00000110
=-6 //应该是-7
如果将二进制0.110转换为十进制:
将二进制中的三位数分别于下边对应的值相乘后相加得到的值为换算为十进制的结果
二、C语言中的一些运算
1.位级运算
C语言支持按位布尔运算,包括:
& 与 (AND),
| 或 (OR),
~ 取反 (NOT),
^ 异或 (EXCLUSIVE-OR)。
有以下常用结论:
对于任意向量a,有a ^ a = 0.
异或(^) 是可交换的和可结合的。a ^ (a ^ b) = (a ^ b) ^ b = b; b ^ (a ^ b) = (b ^ b) ^ a = a.
0 ^ A = A (0 异或任何数 A 结果还是 A).
位级运算常见用法:实现掩码运算。
这里掩码指位模式,表示从一个字中选出的位的集合。比如掩码 0xFF(最低的8位为1)表示一个字的低位字节。x = 0x89ABCDEF, 那么 x & 0xFF = 0x000000EF,生成由x的最低有效字节组成的值。
2.逻辑运算
&&与运算,双目,对应数学中的“且”左结合1&&0、(9>3)&&(b>a)
||或运算,双目左结合1||0、(9>3)||(b>a)
!非运算。单目右结合!a、!(2<5)
逻辑运算的结果
在编程中,我们一般将零值称为“假”,将非零值称为“真”。逻辑运算的结果也只有“真”和“假”,“真”对应的值为 1,“假”对应的值为 0。
1) 与运算(&&)
在C中如果前一个条件为真,后面就不看了,所以,后面即使语法或逻辑有误也可能不会报错。
参与运算的两个量都为真时,结果才为真,否则为假。例如:
5&&0
5为真,0为假,相与的结果为假,也就是 0。
(5>0) && (4>2)
5>0 的结果是1,为真,4>2结果是1,也为真,所以相与的结果为真,也就是1。
2) 或运算(||)
参与运算的两个量只要有一个为真,结果就为真;两个量都为假时,结果为假。例如:
10 || 0
10为真,0为假,相或的结果为真,也就是 1。
(5>0) || (5>8)
5>0 的结果是1,为真,5>8 的结果是0,为假,所以相或的结果为真,也就是1。
3) 非运算(!)
参与运算的量为真时,结果为假;参与运算的量为假时,结果为真。例如:
!0
0 为假,非运算的结果为真,也就是 1。
!(5>0)
5>0 的结果是1,为真,非运算的结果为假,也就是 0。
优先级
逻辑运算符和其它运算符优先级从低到高依次为:
赋值运算符(=) < &&和|| < 关系运算符 < 算术运算符 < 非(!)
&& 和 || 低于关系运算符,! 高于算术运算符。
按照运算符的优先顺序可以得出:
a>b && c>d 等价于 (a>b)&&(c>d)
!b==c||d
a+b>c&&x+yc)&&((x+y)
另外,逻辑表达式也可以嵌套使用,例如a>b && b || 9>c,a || c>d && !p。
3.移位运算


四、有符号和无符号整型
参考博客:有符号和无符号整型;
strlen的返回值类型为size_t,C语言中将size_t定义为unsigned int,当s比t短时,strlen(s) - strlen(t)为负数,但无符号数的运算结果隐式转换为无符号数就变成了很大的无符号数.
数getpeername的安全漏洞
2002年,从事FreeBSD开源操作系统项目的程序员意识到,他们对getpeername函数的实现存在安全漏洞。代码的简化版本如下:

在这段代码里,第7行给出的是库函数memcpy的原型,这个函数是要将一段指定长度为n的字节从存储器的一个区域复制到另一个区域。
从第14行开始的函数copy_from_kernel是要将一些操作系统内核维护的数据复制到指定的用户可以访问的存储器区域。对用户来说,大多数内核维护的数据结构应该是不可读的,因为这些数据结构可能包含其他用户和系统上运行的其他作业的敏感信息,但是显示为kbuf的区域是用户可以读的。参数maxlen给出的是分配给用户的缓冲区的长度,这个缓冲区是用参数user_dest指示的。然后,第16行的计算确保复制的字节数据不会超出源或者目标缓冲区可用的范围。
不过,假设有些怀有恶意的程序员在调用copy_from_kernel的代码中对maxlen使用了负数值,那么,第16行的最小值计算会把这个值赋给len,然后len会作为参数n被传递给memcpy。不过,请注意参数n是被声明为数据类型size_t的。这个数据类型是在库文件stdio.h中(通过typedef)被声明的。典型地,在32位机器上被定义为unsigned int。既然参数n是无符号的,那么memcpy会把它当作一个非常大的正整数,并且试图将这样多字节的数据从内核区域复制到用户的缓冲区。虽然复制这么多字节(至少231个)实际上不会完成,因为程序会遇到进程中非法地址的错误,但是程序还是能读到没有被授权的内核存储器区域。
我们可以看到,这个问题是由于数据类型的不匹配造成的:在一个地方,长度参数是有符号数;而另一个地方,它又是无符号数。正如这个例子表明的那样,这样的不匹配会成为缺陷的原因,甚至会导致安全漏洞。幸运的是,还没有案例报告有程序员在FreeBSD上利用了这个漏洞。他们发布了一个安全建议,“FreeBSD-SA-02:38.signed-error”,建议系统管理员如何应用补丁消除这个漏洞。要修正这个缺陷,只要将copy_from_kernel的参数maxlen声明为类型size_t,也就是与memcpy的参数n一致。同时,我们也应该将本地变量len和返回值声明为size_t。
五、整数运算
参考博客:深入理解计算机系统--整数运算;
六、浮点数
关于浮点数的细节标准:浮点数的表示;
浮点数运算:浮点数运算与舍入;