Hbase安装使用与入门学习
hbase的学习会持续记录在此ing。。。。
1.前言
随着部门全面上云的展开tlist(腾讯内部自研UGC数据存储)也到退出历史舞台的时候了,在关于tlist的替代者数mongodb和Hbase了。这里更多是参照别人的文章记录下Hbase的一些知识。
HBase作为nosql的典型代表,是一个分布式的、面向列的开源数据库,在大数据存储上广受欢迎,因此,第一站就来到这里。
网络上对于HBase的文档有很多,但是看了一圈,没有特别能让一个小白快速入门的介绍(这一点和原作者感同身受)。
本文作为一个入门文档,希望能通过自己的理解,来快速认识HBase到底是什么,它的结构、特点、适用场景有哪些,但不会有深入的技术点的说明。
嗯,就是快速,非常快速并且丝滑地去理解HBase到底是啥。
2. 适用场景
一开始,我们肯定需要了解的是,为什么要用HBase。
存储组件比较多,我们就简单谈谈MySQL和HBase的主要对比。

可以看到,在面对海量数据场景时,如果没有较强的事务要求,查询比较简单,那么HBase是非常适合的。
2. 基本概念
2.1 表、行、列和单元格
为什么正文要从这里开始呢?
因为这个是一切的基础,也是我们初次接触HBase最先想到的问题,HBase的数据格式是怎样的?
但是在入门HBase的过程中,发现一个小白想搞明白HBase到底是个什么存储格式还是挺费劲的。
比如给你这样一个HBaes的数据结构,是不是比较难理解是一个怎样的层级概念?

一个好的办法就是做 知识的迁移。所以,从我们熟悉的Mysql来说,是个非常好的方式(感谢原作者)。
Mysql的表结构我们非常熟悉,所以第一个问题就是,Mysql的表记录在HBase中是如何存储呢?
我们来举个例子,有两张mysql的表,表名叫user和location,表记录如下。
user表

location表

这样的结构,在HBase中的逻辑存储应该是这样的。

抽象出来的概念如下
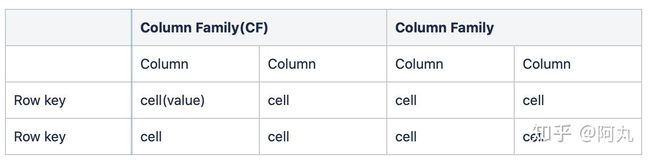
相信有了这样直接的对比,不用我说,大家也能明白HBase的基本存储概念了。
- RowKey:是Byte array,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要。
- Column Family:列族,拥有一个名称(string),包含一个或者多个相关列
- Column:属于某一个column family,familyName:columnName,每条记录可动态添加
- Value(Cell):Byte array
- Version Number:类型为Long,默认值是系统时间戳,可由用户自定义(这个概念在上文的逻辑存储中不太好迁移类比,所以上文的模型中没有给出,可以理解为mysql中的mvcc的版本号)
注:再回过头看之前看不明白的那张“HBaes数据结构”图,就很容易理解了。
那么,在HBase中确定一个值的方式就比较清楚了。

通过RowKey-CF(列组)-Column-Version我们就能找到Value,这样就明白了KV的查询的结构关系。
如果用代码来简单表示,可以这样显示:
SortedMap>>> 做个小结:
最基本的单位是列(column)。一列或者多列形成行(row),并且由唯一的行键(row key)来确定存储。反过来,一个表(table)中有若干行,其中每列可能由多个版本(version),在每一个单元格(cell)中存储了不同的值。
2.2 列式存储
(1)数据模型:HBase是面向列族的非关系型数据库,每行数据列都可以不同,并且列可以按照需求进行动态增加。创建Hbase表可以指创建列族,等需要的时候再创建相应的列。hbase主要涉及如下几个概念,这几个概念在下图得到了比较好的诠释。

(2)物理视图:在物理存储上数据是以K-V对的形式存储的,每个K-V值存储一个Cell里面的数据,不同的列族存储在不同的文件中。Hbase表可以理解为一个3维Map,包括row key, column(family+qualifier),timestamp。对于上图中的表格我们有如下K-V检索关系:
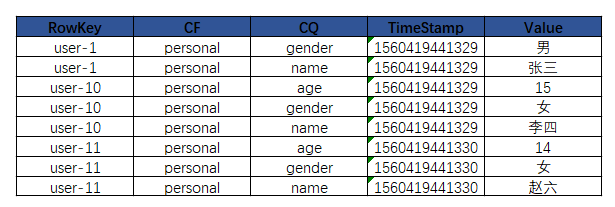
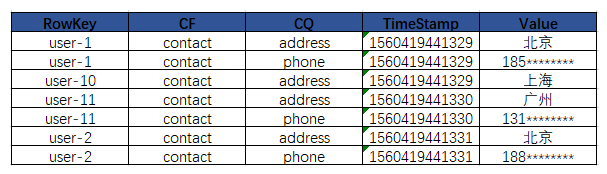
(3)RowKey:rowkey是用来检索记录的主键,唯一标识一行数据(等同于RDMS中的主键)。
Rowkey(行键)可以是任意字符串(最大长度是 64KB)。在hbase内部row key保存为字节数组。存储时数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
(4)Column Family(CF/列族/列簇):hbase表中的每个列都归属于某个列族。列族是schema的一部分(而列不是),也就是说列族必须在使用表之前定义,而列在需要的时候创建就好了。列名都以列族作为前缀。例如course.history,course.math都属于courses这个列族。Hbase的列族不是越多越好,官方推荐的是列族最好小于或者等于3。我们使用的场景一般是1个列族。如下:

(5)Column Qualifier(CQ/列标识):表的每列数据可以通过family.qualifier唯一标识。
(6)Timestamp(数据版本):
1)HBase中通过row和columns确定的一个存储单元称为cell,每个cell都保存着同一份数据的多个版本。
2)默认最大保留三个版本,读取数据时如果未指定版本默认返回最新版本的值。
3)另外注意不建议将版本号设为特别大的值(例如上百),因为这会大大的增加storefile的大小。
4)时间戳是64位整形,版本通过时间戳来索引。时间戳可以由客户在写入时显示赋值,也可以有hbase自动填充此时时间戳是明确到毫秒的当前系统时间。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个cell中不同版本的数据按照时间啊倒叙排列,即最新的数据排在最前面。
5)为了避免数据存在过多版本造成的管理负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,而是保存最近一段时间的版本(如最近七天),用户可以针对每个列族进行设置。
(7)cell:由{row key,column(
(8)Regin:
1)HBase中扩展和负载均衡的基本单位称为regin,regin本质上是以行键排序的连续存储的区间。
2)如果regin太大,系统会自动进行拆分,反之会把多个regin合并(非自动)以减少存储文件数量。
3)每一个regin只能被一台regin服务器(region server)加载,但是每一台region server可以加载多个region。
4)region上按列族划分为多个store;每个store有一个memstore,当有读写请求时先请求memstore,menstorenebula根据rowKey.Column,version进行排序。
4)知识迁移一下,所谓regin类比到mysql可以看作是水平分区(partition)的概念(如“一个包含10亿人信息的表可以分成十个分区,每个分区包含一亿人的记录”)。
5)如下是一个region水平切分的实例。
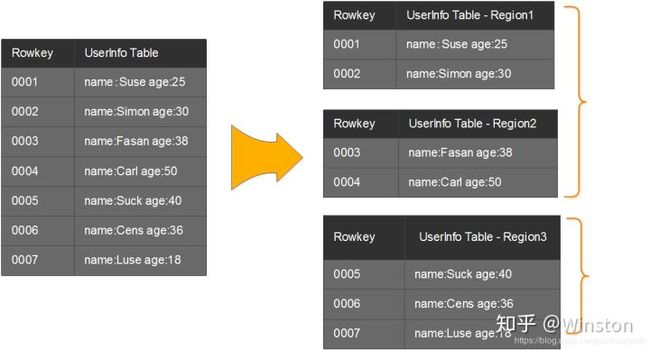
(9)架构体系简介:

HBase有两个进程,RegionServer和Master。HBase依赖于两个服务,ZooKeeper和HDFS。
红线流程:
RegionServer:相当于DateNode,用来管理表里的数据,当一个表数据量很大的时候,可以进行分区,一个区对应的就是一个Region。每个Region管理自己的数据,RegionServer就是管理集群里的Region。
RegionServer会实时地报告Master,首先RegionServer需要实时地将自己的状态报告给Master(比如RegionServer是否是存活地,目前运行状态如何),第二个RegionServer管理了哪些Region,Master也要知道。这样Master就知道了每个RegionServer的状态与RegionServer管理了哪些Region,这样当出现某个RegionServer宕机之后,Master就可以立即将这个RegionServer管理的Region切换到其他存活的RegionServer机器上节点上面。
黑线流程:
同红线,ZooKeeper的信息跟Master是一样的,它也知道哪些机器上的RegionServer是存活的,哪些是宕机的,也知道每个RegionServer管理了哪些Region。
3. 架构
这张图是HBase非常经典的整体架构图。图中展示了HBase的各种组件。
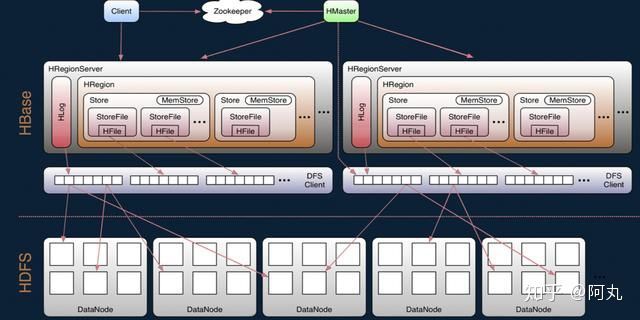
1)Client
Client包含了访问Hbase的接口,另外Client还维护了对应的cache来加速Hbase的访问,比如cache的.META.元数据的信息。
2) Zookeeper
Hbase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
- 通过Zoopkeeper来保证集群中只有1个master在运行,如果master异常,会通过竞争机制产生新的master提供服务
- 通过Zoopkeeper来监控RegionServer的状态,当RegionSevrer有异常的时候,通过回调的形式通知Master RegionServer上下线的信息
- 通过Zoopkeeper存储元数据的统一入口地址
3) HMaster
- master节点为RegionServer分配Region
- 维护整个集群的负载均衡
- 维护集群的元数据信息
- 发现失效的Region,并将失效的Region分配到正常的RegionServer上
- 当RegionSever失效的时候,协调对应Hlog的拆分
4)HReginServer
HregionServer直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
- 管理master为其分配的Region 处理来自客户端的读写请求
- 负责和底层HDFS的交互,存储数据到HDFS
- 负责Region变大以后的拆分
- 负责Storefile的合并工作
5) HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为Hbase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:
- 提供元数据和表数据的底层分布式存储服务
- 数据多副本,保证的高可靠和高可用性
补充:
MVCC全称是: Multiversion concurrency control,多版本并发控制,提供并发访问数据库时,对事务内读取的到的内存做处理,用来避免写操作堵塞读操作的并发问题。
举个例子,程序员A正在读数据库中某些内容,而程序员B正在给这些内容做修改(假设是在一个事务内修改,大概持续10s左右),A在这10s内 则可能看到一个不一致的数据,在B没有提交前,如何让A能够一直读到的数据都是一致的呢?(意思是至少要保证B提交前读到的数据库数据是同一份数据,同样提交后也一样)
有几种处理方法,第一种: 基于锁的并发控制,程序员B开始修改数据时,给这些数据加上锁,程序员A这时再读,就发现读取不了,处于等待情况,只能等B操作完才能读数据,这保证A不会读到一个不一致的数据,但是这个会影响程序的运行效率。还有一种就是:MVCC,每个用户连接数据库时,看到的都是某一特定时刻的数据库快照,在B的事务没有提交之前,A始终读到的是某一特定时刻的数据库快照,不会读到B事务中的数据修改情况,直到B事务提交,才会读取B的修改内容。
一个支持MVCC的数据库,在更新某些数据时,并非使用新数据覆盖旧数据,而是标记旧数据是过时的,同时在其他地方新增一个数据版本。因此,同一份数据有多个版本存储,但只有一个是最新的。
MVCC提供了 时间一致性的 处理思路,在MVCC下读事务时,通常使用一个时间戳或者事务ID来确定访问哪个状态的数据库及哪些版本的数据。读事务跟写事务彼此是隔离开来的,彼此之间不会影响。假设同一份数据,既有读事务访问,又有写事务操作,实际上,写事务会新建一个新的数据版本,而读事务访问的是旧的数据版本,直到写事务提交,读事务才会访问到这个新的数据版本。
MVCC有两种实现方式,第一种实现方式是将数据记录的多个版本保存在数据库中,当这些不同版本数据不再需要时,垃圾收集器回收这些记录。这个方式被PostgreSQL和Firebird/Interbase采用,SQL Server使用的类似机制,所不同的是旧版本数据不是保存在数据库中,而保存在不同于主数据库的另外一个数据库tempdb中。第二种实现方式只在数据库保存最新版本的数据,但是会在使用undo时动态重构旧版本数据,这种方式被Oracle和MySQL/InnoDB使用。
参考:
https://zhuanlan.zhihu.com/p/111188145
https://zhuanlan.zhihu.com/p/92654939
参考三