ELK+Kafka搭建日志系统
目录
- 1.什么是ELK
- 2.搭建ELK日志系统
- 2.1 安装JDK
- 2.2 安装Zookeeper
- 2.3 安装Kafka
- 2.4 安装ELK
- 2.4.1 安装Elasticsearch
- 2.4.2 安装Elasticsearch-head(可选)
- 2.4.3 安装Logstash
- 2.4.4 安装Kibana
- 2.5 Nginx代理Kibana
- 3.日志采集
- 3.1 收集系统日志
- 3.2 收集Nginx日志
1.什么是ELK
通俗来讲,ELK 是由 Elasticsearch、Logstash、Kibana 三个开源软件的组成,这三个软件当中,每个软件用于完成不同的功能。
- Elasticsearch: elasticsearch是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索搜索、支持分布式可实现高可用、提供 API 接口,可以处理大规模日志数据,比如 Nginx、Tomcat、系统日志等功能。
- Logstash: logstash可以通过插件实现日志收集和转发,支持日志过滤,支持普通 log、自定义 json格式的日志解析。
- kibana: kibana主要是通过接口调用 elasticsearch 的数据,并进行前端数据可视化的展现。
为什么使用 ELK?
ELK 组件在海量日志系统的运维中,可用于解决以下主要问题:
- 分布式日志数据统一收集,实现集中式查询和管理
- 故障排查
- 安全信息和事件管理
- 报表功能
ELK 组件在大数据运维系统中,主要可解决的问题如下:
- 日志查询,问题排查,故障恢复,故障自愈
- 应用日志分析,错误报警
- 性能分析,用户行为分析
官方站点:https://www.elastic.co/cn/
2.搭建ELK日志系统
架构图:
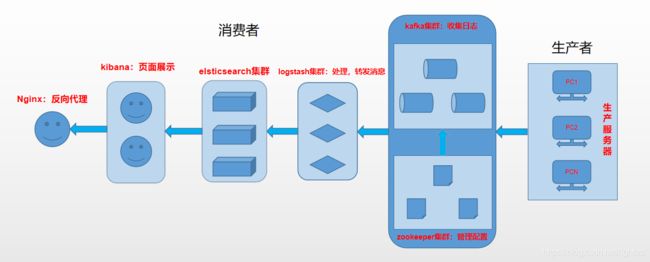 由于 Logstash 比较耗资源,一般我们不会在应用服务器上直接安装 Logstash 来收集日志,我们可能会采用更轻量级的 Filebeat 来采集日志,但当多台 Filebeat 向 Logstash 传输数据再交给ES入库时,压力会比较大,可以在 Filebeat 和 Logstash 之间加上一层消息队列减轻压力,比如Redis、Kafka。
由于 Logstash 比较耗资源,一般我们不会在应用服务器上直接安装 Logstash 来收集日志,我们可能会采用更轻量级的 Filebeat 来采集日志,但当多台 Filebeat 向 Logstash 传输数据再交给ES入库时,压力会比较大,可以在 Filebeat 和 Logstash 之间加上一层消息队列减轻压力,比如Redis、Kafka。
实验环境:
| 系统 | 节点 | JDK | Zookeeper | Kafka | Elasticsearch | logstash | kibana |
|---|---|---|---|---|---|---|---|
| CentOS7.6 | elk-node1 (192.168.100.111) | jdk-8u212 | zookeeper-3.4.14 | kafka_2.12-2.1.0 | elasticsearch-6.8.7 | logstash-6.8.7 | kibana-6.8.7 |
| CentOS7.6 | elk-node2 (192.168.100.112) | jdk-8u212 | zookeeper-3.4.14 | kafka_2.12-2.1.0 | elasticsearch-6.8.7 | logstash-6.8.7 | kibana-6.8.7 |
| CentOS7.6 | elk-node3 (192.168.100.113) | jdk-8u212 | zookeeper-3.4.14 | kafka_2.12-2.1.0 | elasticsearch-6.8.7 | logstash-6.8.7 | – |
实验准备:
~]# systemctl stop firewalld
~]# systemctl disable firewalld
~]# setenforce 0
~]# sed -i '/SELINUX/s/enforcing/disabled/g' /etc/sysconfig/selinux
~]# cat /etc/hosts
...
192.168.100.111 elk-node1
192.168.100.112 elk-node2
192.168.100.113 elk-node3
2.1 安装JDK
下载地址:https://www.oracle.com/technetwork/java/javase/downloads/java-archive-javase8-2177648.html
~]# tar xf jdk-8u212-linux-x64.tar.gz -C /usr/local/
~]# cd /usr/local/
~]# ln -sv jdk1.8.0_212/ jdk
~]# echo 'JAVA_HOME=/usr/local/jdk' > /etc/profile.d/jdk.sh
~]# echo 'PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile.d/jdk.sh
~]# . /etc/profile.d/jdk.sh
~]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
2.2 安装Zookeeper
下载地址: https://mirrors.tuna.tsinghua.edu.cn/apache/
zookeeper配置参数:http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_configuration
在Zookeeper的官网上有这么一句话:ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. 这大概描述了Zookeeper主要可以干哪些事情:配置管理,名字服务,提供分布式同步以及集群管理。此处我们需要使用Zookeeper来管理Kafka集群。
~]# tar xf zookeeper-3.4.14.tar.gz -C /opt/
~]# cd /opt/
~]# ln -sv zookeeper-3.4.14/ zookeeper
~]# cd zookeeper/conf/
~]# cp zoo_sample.cfg zoo.cfg
~]# cat zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/log
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
clientPort=2181
server.0=192.168.100.111:2888:3888
server.1=192.168.100.112:2888:3888
server.2=192.168.100.113:2888:3888
~]# mkdir ../{data,log}
~]# echo 0 > ../data/myid #三台zk编号不同,此处为0,其余两台为1、2,与配置中的server.x有关
~]# echo 'ZK_HOME=/opt/zookeeper' > /etc/profile.d/zk.sh
~]# echo 'PATH=$ZK_HOME/bin:$PATH' >> /etc/profile.d/zk.sh
~]# source /etc/profile.d/zk.sh
~]# zkServer.sh start
~]# zkServer.sh status
~]# zkCli.sh -server localhost:2181
配置解析:
- tickTime:客户端与服务器或者服务器与服务器之间每个tickTime时间就会发送一次心跳。通过心跳不仅能够用来监听机器的工作状态,还可以通过心跳来控制Flower跟Leader的通信时间,默认2秒
- initLimit:集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
- syncLimit:集群中flower服务器(F)跟leader(L)服务器之间的请求和答应最多能容忍的心跳数。
- dataDir:该属性对应的目录是用来存放myid信息跟一些版本,日志,跟服务器唯一的ID信息等。
- clientPort:客户端连接的接口,客户端连接zookeeper服务器的端口,zookeeper会监听这个端口,接收客户端的请求访问!这个端口默认是2181。
- server.N=YYY:A:B
N:代表服务器编号(也就是myid里面的值)
YYY:服务器地址
A:表示 Flower 跟 Leader的通信端口,简称服务端内部通信的端口(默认2888)
B:表示 是选举端口(默认是3888)
2.3 安装Kafka
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/
kafka配置参数:http://kafka.apache.org/documentation/#brokerconfigs
~]# tar xf kafka_2.12-2.1.0.tgz -C /opt/
~]# cd /opt/
~]# ln -sv kafka_2.12-2.1.0/ kafka
~]# cd kafka/config/
~]# cp server.properties server.properties_bak
~]# cat server.properties | grep -v '#' | grep -v "^$"
broker.id=1 #每一个broker在集群中的唯一表示,要求是正数
listeners=PLAINTEXT://192.168.100.111:9092 #监控的kafka端口
num.network.threads=3 #broker处理消息的最大线程数,一般情况下不需要去修改
num.io.threads=8 #broker处理磁盘IO的线程数,数值应该大于你的硬盘数
socket.send.buffer.bytes=102400 #socket的发送缓冲区
socket.receive.buffer.bytes=102400 #socket的接受缓冲区
socket.request.max.bytes=104857600 #socket请求的最大字节数
log.dirs=/opt/kafka/kafka-logs #kafka数据的存放地址,多个地址用逗号分割,多个目录分布在不同磁盘上可以提高读写性能
num.partitions=3 #设置partitions 的个数
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168 #数据文件保留多长时间,此处为168h,粒度还可设置为分钟,或按照文件大小
log.segment.bytes=1073741824 #topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.100.111:2181,192.168.100.112:2181,192.168.100.113:2181 #zookeeper集群地址
zookeeper.connection.timeout.ms=6000 #kafka连接Zookeeper的超时时间
group.initial.rebalance.delay.ms=0
~]# echo 'KFK_HOME=/opt/kafka' > /etc/profile.d/kfk.sh
~]# echo 'PATH=$KFK_HOME/bin:$PATH' >> /etc/profile.d/kfk.sh
~]# source /etc/profile.d/kfk.sh
~]# kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
验证kafka是否可用:
~]# zkCli.sh -server localhost:2181
[zk: localhost:2181(CONNECTED) 0] get /brokers/ids/1
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://192.168.100.111:9092"],"jmx_port":-1,"host":"192.168.100.111","timestamp":"1591675712330","port":9092,"version":4}
cZxid = 0x10000001a
ctime = Tue Jun 09 00:08:32 EDT 2020
mZxid = 0x10000001a
mtime = Tue Jun 09 00:08:32 EDT 2020
pZxid = 0x10000001a
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x20000a7ad170000
dataLength = 200
numChildren = 0
注: kafka节点默认需要的内存为1G,在工作中可能会调大该参数,可修改kafka-server-start.sh的配置项。找到KAFKA_HEAP_OPTS配置项,例如修改为:export KAFKA_HEAP_OPTS="-Xmx2G -Xms2G"。
2.4 安装ELK
下载地址:https://www.elastic.co/cn/downloads/
2.4.1 安装Elasticsearch
~]# tar xf elasticsearch-6.8.7.tar.gz -C /opt/
~]# cd /opt/
~]# ln -sv elasticsearch-6.8.7/ elasticsearch
~]# cd elasticsearch/config/
~]# cp elasticsearch.yml elasticsearch.yml_bak
~]# cat elasticsearch.yml
cluster.name: myes #集群名称,一定要一致,当集群内节点启动的时候,默认使用组播(多播),寻找集群中的节点
node.name: elk-node1 #节点名称
path.data: /opt/elasticsearch/data #数据目录
path.logs: /opt/elasticsearch/log #日志目录
bootstrap.memory_lock: true #启动时锁定内存
network.host: 192.168.100.111 #监听IP
transport.tcp.port: 9300 #集群内通信端口,默认9300
http.port: 9200 #服务监听端口,默认9200
discovery.zen.ping.unicast.hosts: ["elk-node2", "elk-node3"] #集群中其他成员,需要能解析,请先做好host
discovery.zen.minimum_master_nodes: 2 #成为master需要的最小票数
~]# cat jvm.options | grep -v '#' | grep -v '^$' | head -n 2 #默认给elasticsearch分配的内存,生产环境需调大此数值
-Xms1g
-Xmx1g
~]# useradd elastic #elasticsearch 5.0后不能使用root启动
~]# echo "123456" | passwd --stdin elastic
~]# chown -R elastic:elastic /opt/elasticsearch/
~]# vim /etc/sysctl.conf #调整系统虚拟内存,否则会启动不了
vm.max_map_count=262144
~]# sysctl -p
~]# tail -n 4 /etc/security/limits.conf #修改用户可使用最大文件描述符 ,锁定内存
* soft nofile 65536
* hard nofile 65536
* soft memlock unlimited
* hard memlock unlimited
若不设置以上两参数,启动时会报错:
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
[2]: memory locking requested for elasticsearch process but memory is not locked
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
~]# su - elastic #es默认不能使用root启动
~]# cd /opt/elasticsearch/bin
~]# ./opt/elasticsearch/bin/elasticsearch -d #elastic用户
~]# curl http://192.168.100.111:9200/_cat/nodes #查看集群节点信息,*号为集群master
192.168.100.113 18 97 0 0.16 0.10 0.07 mdi - elk-node3
192.168.100.112 13 97 0 0.07 0.14 0.10 mdi * elk-node2
192.168.100.111 26 94 0 0.23 0.68 0.40 mdi - elk-node1
# Master 的职责:统计各 node 节点状态信息、集群状态信息统计、索引的创建和删除、索引分配的管理、关闭 node 节点等
# Slave 的职责:从 master 同步数据、等待机会成为 Master
2.4.2 安装Elasticsearch-head(可选)
Elasticsearch-head简介:
- ElasticSearch-head是一个H5编写的ElasticSearch集群操作和管理工具,可以对集群进行傻瓜式操作。
- 显示集群的拓扑,并且能够执行索引和节点级别操作
- 搜索接口能够查询集群中原始json或表格格式的检索数据
- 能够快速访问并显示集群的状态
- 有一个输入窗口,允许任意调用RESTful API。这个接口包含几个选项,可以组合在一起以产生有趣的结果
- es的图形界面插件,托管于GitHub,使用9100端口
在 elasticsearch 5.x 版本以后不再支持直接安装 head 插件,而是需要通过启动一个服务。以下提供两种安装方式:
NPM安装:
~]# yum install -y git npm #NPM 的全称是 Node Package Manager,是随同 NodeJS 一起安装的包管理和分发工具,它很方便让 JavaScript 开发者下载、安装、上传以及管理已经安装的包。
~]# cd /opt/
~]#git clone http://github.com/mobz/elasticsearch-head.git
~]# cd elasticsearch-head/
~]# npm install grunt -save
~]# ll node_modules/grunt #确认生成文件
~]# npm install #执行安装
~]# npm run start & #后台启动服务
~]# cat /opt/elasticsearch/config/elasticsearch.yml | tail -n 2 #开启跨域访问支持,然后重启 elasticsearch 服务
http.cors.enabled: true
http.cors.allow-origin: "*"
Docker安装:
~]# yum install docker -y
~]# systemctl start docker && systemctl enable docker
~]# mkdir -p /etc/docker
~]# tee /etc/docker/daemon.json <<-'EOF' #配置镜像加速,此处配置阿里云镜像加速
{
"registry-mirrors": ["https://nqq67ahg.mirror.aliyuncs.com"]
}
EOF
~]# systemctl daemon-reload
~]# systemctl restart docker
~]# docker run -d -p 9100:9100 mobz/elasticsearch-head:5
~]# cat /opt/elasticsearch/config/elasticsearch.yml | tail -n 2 #开启跨域访问支持,然后重启 elasticsearch 服务
http.cors.enabled: true
http.cors.allow-origin: "*"
默认监听在9100端口,可直接访问。

2.4.3 安装Logstash
logstash配置我们后面进行说明
~]# tar xf logstash-6.8.3.tar.gz -C /opt/
~]# cd /opt
~]# ln -sv logstash-6.8.3/ logstash
2.4.4 安装Kibana
~]# tar xf kibana-6.8.7-linux-x86_64.tar.gz -C /opt/
~]# cd /opt/
~]# ln -sv kibana-6.8.7-linux-x86_64/ kibana
~]# cd kibana/config/
~]# cp kibana.yml kibana.yml_bak
~]# cat kibana.yml
server.port: 5601
server.host: "192.168.100.111"
server.name: "node1.kibana"
elasticsearch.url: "http://192.168.100.111:9200"
~]# nohup ../bin/kibana & #监听5601端口
写环境变量:
~]# echo 'ES_HOME=/opt/elasticsearch' > /etc/profile.d/elk.sh
~]# echo 'LS_HOME=/opt/logstash' >> /etc/profile.d/elk.sh
~]# echo 'KB_HOME=/opt/kibana' >> /etc/profile.d/elk.sh
~]# echo 'PATH=$ES_HOME/bin:$LS_HOME/bin:$KB_HOME/bin:$PATH' >> /etc/profile.d/elk.sh
~]# source /etc/profile.d/elk.sh
2.5 Nginx代理Kibana
~]# cat /etc/yum.repos.d/nginx.repo #直接使用yum安装
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
~]# yum install -y nginx
~]# cat /etc/nginx/nginx.conf #添加如下配置
http{
...
upstream kibana_server {
server 192.168.100.111:5601;
server 192.168.100.112:5601;
ip_hash;
}
server {
listen 80;
server_name www.kibana.com;
access_log /var/log/nginx/access.log main;
location / {
proxy_pass http://kibana_server;
}
}
...
}
还可以通过Nginx做一些访问控制啥的,这里就不描述了。
3.日志采集
此处我们使用 filebeat 收集本地系统日志,写入 kafka,logstash 从 kafka 中读取数据并传给 elasticsearch,从而 kibana 进行展示。
给需要收集日志主机安装filebeat:
~]# tar xf filebeat-6.8.3-linux-x86_64.tar.gz -C /opt/
~]# cd /opt/
~]# ln -sv filebeat-6.8.3-linux-x86_64/ filebeat
3.1 收集系统日志
此处我们使用 filebeat 收集本地系统日志,写入 kafka,logstash 从 kafka 中读取数据并传给 elasticsearch,从而 kibana 进行展示。
配置启用filebeat:
~]# cat /opt/filebeat/filebeat.yml 修改如下两个配置项
filebeat.inputs: #从哪里收集
- type: log
enabled: true
paths:
- /var/log/messages
output.kafka: #收集的数据写到哪里去
hosts: ["192.168.100.111:9092","192.168.100.112:9092","192.168.100.113:9092"]
topic: messages-topics #写到哪个topics
keep_alive: 10s
nohup ./filebeat -e -c filebeat.yml &
当我们filebeat启用没问题,此时数据就能写到kafka中了。
查看kafka中是否创建了topics:
~]# kafka-topics.sh --list --zookeeper 192.168.100.111:2181,192.168.100.112:2181,192.168.100.113:2181
__consumer_offsets
messages-topics
kafka已有数据,我们还需使用logstash从kafka中读取数据,交给elasticsearch。
logstash-input-kafka配置可参考:https://segmentfault.com/a/1190000016595992
配置启用logstash:
~]# cat /opt/logstash/messages-logstash.conf
input {
kafka {
bootstrap_servers => "192.168.100.111:9092,192.168.100.112:9092,192.168.100.113:9092" #kafka集群地址
group_id => "logstash" #此消费者所属的组的标识符,消费者组是由多个处理器组成的单个逻辑订阅服务器,主题中的消息将分发给具有相同group_id的所有Logstash实例。
auto_offset_reset => "earliest" #如果Kafka中没有初始偏移量,或者偏移量超出范围,自动重置偏移量到最早的偏移量
decorate_events => true #在输出消息的时候会输出自身的信息包括:消费消息的大小,topic 来源以及 consumer 的 group 信息。
topics => ["messages-topics"] #哪个topics取数据
type => "messages" #用于其他插件进行判断
}
}
output {
if [type] == "messages" {
elasticsearch {
hosts => ["192.168.100.111:9200"]
index => "messages-%{+YYYY-MM}" #索引名称
}
}
}
~]# cd /opt/logstash
~]# nohup ./bin/logstash -f messages-logstash.conf &
在kibana添加索引:
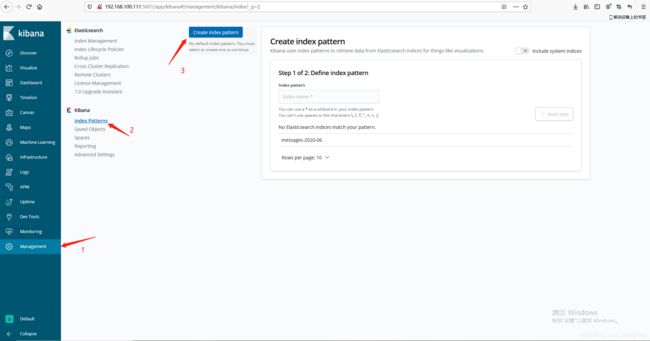


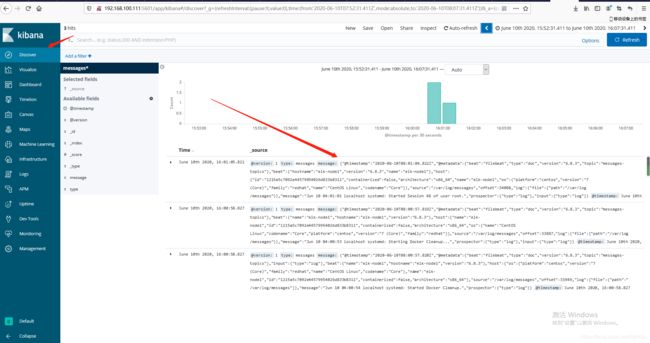 至此,我们的日志系统流程就走通了。
至此,我们的日志系统流程就走通了。
3.2 收集Nginx日志
上面我们收集了系统日志,现在再加上nginx访问日志。
filebeat配置修改:
~]# cat /opt/filebeat/filebeat.yml #修改如下两个配置项,修改后重启服务
- type: log
enabled: true
paths:
- /var/log/messages
fields:
topics: messages-topics
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
fields:
topics: nginx-access-topics
output.kafka:
hosts: ["192.168.100.111:9092","192.168.100.112:9092","192.168.100.113:9092"]
topic: '%{[fields][topics]}'
keep_alive: 10s
logstash修改配置:
~]# cat messages-logstash.conf #修改如下配置项,修改后重启服务
input {
kafka {
bootstrap_servers => "192.168.100.111:9092,192.168.100.112:9092,192.168.100.113:9092"
group_id => "logstash"
auto_offset_reset => "earliest"
decorate_events => true
topics => ["messages-topics"]
type => "messages"
}
kafka {
bootstrap_servers => "192.168.100.111:9092,192.168.100.112:9092,192.168.100.113:9092"
group_id => "logstash"
auto_offset_reset => "earliest"
decorate_events => true
topics => ["nginx-access-topics"]
type => "nginx-access"
}
}
output {
if [type] == "messages" {
elasticsearch {
hosts => ["192.168.100.111:9200"]
index => "messages-%{+YYYY-MM}"
}
}
if [type] == "nginx-access" {
elasticsearch {
hosts => ["192.168.100.111:9200"]
index => "nginx-access-%{+YYYY-MM}"
}
}
}
至此,我们就能简单实现日志采集、分类、索引、展示等功能了。