详解-程序是如何访问数据库的?
最近我们项目中引入了时序数据库TDengine,所以可以访问的数据库需要配置两个,并且在不同的时机访问不同的数据库,在配置多数据源的过程中,我想了很多问题,花费了一部分精力将数据库访问的原理彻彻底底的梳理了一下,在这里我想和大家分享一下。
在计算机程序中,没有什么问题是通过增加一层抽象层解决不了的,如果有,那就再增加一层。
应用访问数据库程序也一样,通过一层一层的抽象,将最初的通过TCP连接传输复杂的协议数据来操作数据,封装成我们现在的简单几个配置就能操作数据库中数据,真是太神奇了,下面,我们就从这一层一层抽象入手,看看每一层抽象都做了什么,为什么要这样做?
下面,我们主要从以下几个方面聊聊:
1.如何访问数据库?
2.为什么要有JDBC规范,JDBC规范定义了什么?
3.DataSource和DriverManager有什么关系,DataSource本质是什么,DataSource连接池怎么实现?
4.spring的JdbcTemplate又干了什么?
5.mybatis的本质和逻辑是什么?
6.mybatis和springboot是怎么结合的?如何配置多数据源?
1.如何访问数据库?
众所周知,两个进程之间如果要通过网络进行连接并且通行,那么最简单也是最通用的就是socket编程,socket客户端服务端和客户端通过tcp连接起来,就可以双向通信了。
所以最初我们应用程序访问数据库的时候,就是建立一个tcp连接,然后应用程序和数据库共同商量一个应用层协议,进行数据库的操作。
这个应用层协议是很复杂的,需要定义很多东西,比如:
应用程序想要和数据库建立连接的时候,发送什么消息来握手?
怎么去做安全认证,授权,数据加密?
要查询数据的时候发送什么?数据库怎么给我返回?
增删改数据的时候发送什么?数据库怎么告知我结果?
还有数据库相关的事务,函数什么的怎么处理?怎么处理分包、粘包问题?
所以说,如果使用这种方式进行编程会很复杂,但是,这种方式确实解决了应用程序访问数据库的问题。原理如下图所示:

2.为什么要有JDBC规范,JDBC规范定义了什么?
后来,越来越多的数据库定义了自己的业务协议,如果要访问这些数据库操作数据的话,就需要按照他们的协议来,这样,如果我们的程序要连接两个数据库,就需要写两套访问数据库的代码,并且如果后面切换数据库的时候,所有和数据库相关的代码都会被推翻重写,这是很不合理的。
后来,java也觉得这样实在不是办法,一定要想办法解决。
首先,对所有数据库的访问在代码中一定要统一起来才能减少我们开发人员的负担,那么怎么解决协议不一致的问题呢?我们程序语言总不能规范人家数据库的通信协议吧,所以我们必须有一个抽象层,将这些繁杂的访问细节屏蔽了,提供给我们开发人员一个更加简洁的接口进行数据库的操作,于是定义了JDBC(java database connection)规范。
JDBC规范主要是将我们应用程序可能用到的数据库操作定义成统一的接口,我们不管使用什么数据库,只需要调用这些统一的接口就可以,比如获取连接、增删改查数据接口等等,至于接口的具体实现,由于每个数据库的交互协议都不相同,所以由数据库厂商来提供实现,我们只需要引入一个驱动包就行。
那么这个JDBC规范中,要包含哪些东西呢?
首先,要访问数据库,那就必须有一个连接,定义一个Connection吧;然后要执行数据库的sql怎么办?总不能用连接执行sql吧,因此需要定义一个对象来执行sql,就定义一个Statement吧,'陈述’一下,访问数据库要干啥;执行了sql怎么代表包装返回结果呢?定义一个结果集ResultSet吧;因此,应用层代码应该这样写:

先获取连接Connection,从连接获取可以执行sql的Statement,然后执行sql,返回结果为ResultSet,从结果集中,我们可以获取返回的一切,一气呵成,完美!
那么还有一个问题,怎么获取数据库的连接呢?为了遵守开闭原则,我们不能直接new数据库的连接实现,我们可以使用工厂模式,用工厂来创建Connection,这样就解耦了连接使用者和连接创建者,如果我们连接实现改变了,我也不用改变连接的使用者。这个工厂我们就叫他Driver吧。
相对于不同的数据库,我们会有不同的Driver,因此我们需要一个DriverManager去管理这些Driver。
这样,获取连接的过程如下(以mysql为例):
1.我们将mysql的Driver加载进来。
![]()
2.在Mysql Driver的静态代码块中,会将Driver注册到DriverManager中,源代码如下:
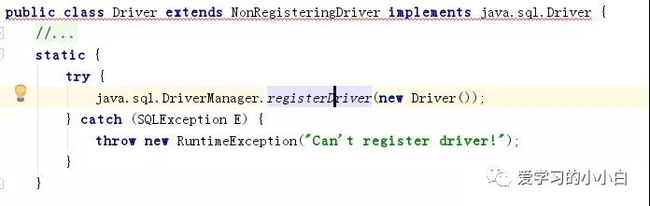
3.这样我们就可以在DriverManager中,通过不同的url获取不同的驱动,从而获取不同的连接了,代码如下:
![]()
在getConnection方法中,会遍历所有的Driver实现,判断url是哪个Driver管理,比如mysqlDriver通过"jdbc:mysql:"判断出是自己管理,因此创建一个mysqlConnection,并返回,这样我们就获得了自己想要的连接了。
综合起来,获取连接就这几行代码:
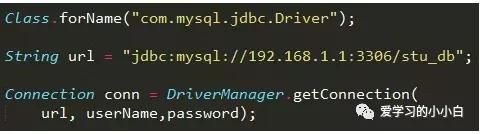
ok,到这里,jdbc就诞生了!
3.DataSource和DriverManager有什么关系,DataSource本质是什么,DataSource连接池怎么实现?
我们在上面的JDBC规范中可以看到连接可以通过DriverManager获取,但是我们在编码中接触的获取连接的东西都是DataSource,那么这两个有什么关系呢?DataSource到底是什么?
在JDBC规范中,我们可以通过DriverManager获取Connection,但是在getConncetion方法的入参中需要传入很多配置参数,这些配置参数是数据库相关的东西,和我们的业务逻辑没有关系,所以说并不应该在我们代码中出现,我们需要将这些配置参数和应用程序解耦。
那么怎么做呢?我们可以将这些配置参数和本身的数据库驱动封装起来,代表一个数据源,并且我们程序可以通过JNDI配置这些参数。这个封装起来的东西,就是DataSource。(JNDI全称java naming and directory interface,是一个java定义的规范,也是所有的数据库厂商需要实现的接口,简单解释就是给资源起个名字,然后通过名字找资源,这样就解耦了资源使用者和资源提供着,在数据源中的表现就是:我们不用在代码中关心数据库的配置,我们只需要知道dataSource的名字,然后系统就可以帮我们自动找到数据库的配置,进行数据的操作)。
现在,我们只要知道DataSource的名称就可以直接获取Conncection,而那些配置参数都在底层通过jndi查找,这样,我们程序中就和数据库配置解耦合了。当然,万变不离其宗,DataSource底层还是使用DriverManager获取Connection。
在使用DataSource的过程中,我们渐渐的发现了一个问题,就是每次执行一个语句就必须重新建立一个Connection,然后又进行三次握手,简直太浪费资源了,于是,java提出了连接池的概念:连接池就是可以缓存连接的地方。我们在启动或者连接不够时建立一些连接, 放到连接池里, 需要连接时直接去取就可以了,用完了之后再放回去就好了,这样就实现了连接的复用,节省了资源。另外,连接池还可以加快操作数据库的速度(获取连接速度加快),限制数据库连接的数量等等。
但是,怎么能让用户无感知使用连接池呢?也就是说,用户在使用连接池和不使用连接池是同一套代码?JDBC在DataSource的实现中,增加了连接池的实现,在获取连接的时候,从连接池的DataSource实现中获取的连接就是池化的连接,这个链接close的时候并不是真正的关闭,而是release到连接池中了,比如HikariDataSource:
public class HikariDataSource extends HikariConfig implements DataSource, Closeable{}
4.spring的JdbcTemplate又干了什么?
我们上面已经基本把jdbc简单说完了,那么现在的代码成什么样子了呢?如下所示:

大家有没有发现什么?
这些代码也太复杂了吧,我就是想查询个数据而已,写了这么一大堆代码,而且这其中有很多代码都是可以通用的,这时候,作为抽象界的大师,spring出来发话了:
我们现在的代码流程是这样的:
声明配置参数-获取连接-获取Statement-执行sql-处理返回值-关闭Statement-关闭连接(外加处理异常以及事务等等)
但是我们关心的其实只有上面的黑体部分,也就是我们通过配置参数告诉在哪里查,然后告诉sql语句,你把返回值查出来我处理一下就好了,就不会有那么冗余的代码了。”
所以,spring推出了JdbcTemplate,它的代码使用方式如下:
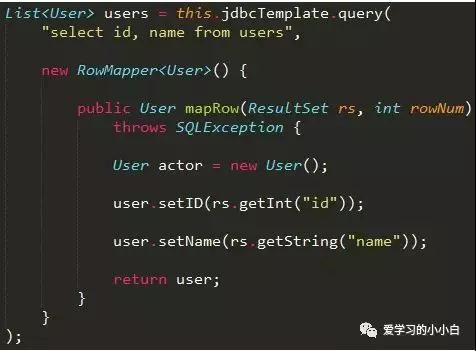
这个jdbcTemplate可以通过如下方式获得:
![]()
当然,按照spring的编码风格来说,JdbcTemplate应该是被‘注入’进去的。
5.mybatis的本质和逻辑是什么?
聪明的程序员使用JDBC或者spring的JdbcTemplate进行数据库的操作持续了很久时间,后来,大家越来越觉得别扭:我使用一个面向对象的开发语言,为什么里面要写和我的业务逻辑没有密切关系的数据库sql?为什么我还必须要知道数据库的字段名称是什么样的?为什么我的sql或者数据库字段名称变了还得重新编译我的应用程序?
大家渐渐明白了,应用程序和数据库的关系断的还不够彻底,还需要继续解耦。
这个时候,mybatis出来了,它几乎完美的解决了这个问题,那么它是怎么做的呢?
首先我们要解耦的话,就要找到一种简便的方式,通过配置文件或者注解将数据库的数据和程序中的对象映射起来,我们只需要操作我们的对象,就相当于操作了数据库中的数据。
也就是说,我们可以将这些数据库相关的东西,比如说是数据库的端口,ip,连接配置,数据库的sql等写在配置文件或者注解中,然后将这些配置文件在适当的时候转换成jdbc代码,代替程序去访问数据库,并将结果通过配置自动解析成我们所需要的结果。
当然,做什么都要站在巨人的肩膀上,mybatis的本质仍然是在jdbc的基础上做了封装,通过极其简单的xml配置或者注解来配置和映射原生类型、接口和java的POJO为数据库中的记录。他几乎避免了所有的jdbc代码和手动设置参数以及获取结果集。
为了做到这些,mybatis定义了以下几个概念:
SqlSessionFactoryBuilder SqlSessionFactory SqlSession
SqlSession可以直接执行sql语句,执行数据库回滚提交等操作(这个底层仍然是调用的jdbc的执行sql的方法,至于为什么可以强制转换成Blog对象,我们下面再说),比如:
Blog blog = (Blog) session.selectOne("org.mybatis.example.BlogMapper.selectBlog", 101);
SqlSessionFactory是用来创建SqlSession的(使用工厂模式是因为可以依赖倒置,符合开闭原则),他可以传入一些和session绑定的属性 比如是否会开启一个事务 是否自定义连接等等。
SqlSession session = sqlSessionFactory.openSession();
SqlSessionFactoryBuilder是用来创建sqlSessionFactory的,主要的作用是从外部资源(比如xml properties)获取配置,创建factory,他配置的是一些通用的参数。
String resource = "org/mybatis/builder/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = builder.build(inputStream);
注:当 Mybatis 与一些依赖注入框架(如 Spring)同时使用时,SqlSession 将被依赖注入框架所创建。
mybatis-config.xml的格式见附录。
通过SqlSessionFactoryBuilder以及SqlSessionFactory,我们可以将访问数据库需要的配置到添加到SqlSession中去,SqlSession才能更好的去操作数据库。
其中,SqlSessionFactoryBuilder以及SqlSessionFactory解耦了访问数据库的配置信息,和jndi的作用差不多,SqlSession解耦了sql语句以及数据库字段。
下面重头戏就来了,我们分析一下,SqlSession是怎么解耦sql语句以及数据库字段的。
在前面我们说了,我们可以使用
Blog blog = (Blog) session.selectOne("org.mybatis.example.BlogMapper.selectBlog", 101);
这样的方式来执行一个操作,我们发现它并没有sql语句或者数据库字段,其实它是把数据库相关的东西解耦了,那么它做了什么呢?
首先,为了解耦sql,我们会将sql配置到xml中(也可以通过注解,但是由于注解方式不能解决复杂的sql,因此这里就不说了),类似如下:
并且这些sql语句在启动的时候会通过namespace+id作为key来注册到mapper中心。
这样,在执行selectOne的时候我们就可以通过第一个参数"org.mybatis.example.BlogMapper.selectBlog"去mapper中心查找,就可以找到对应的sql语句以及结果映射方式resultType或者resultMap。
到这里我们就可以把selectOne方法的底层逻辑大概说清楚了,基本上就是jdbc那一套,声明配置参数-获取连接-获取Statement-执行sql-处理返回值-关闭Statement-关闭连接,只不过在执行sql的时候sql语句去xml中获取了,然后在处理结果的时候,也在xml中获取了而已。
其实到这里为止,mybatis的目标已经实现了:找一种简便的方式,通过配置文件或者注解将数据库的数据和程序中的对象映射起来,我们只需要操作我们的对象,就相当于操作了数据库中的数据。
但是mybatis还不满足于此,它仍然觉得手写字符串类型的“nameSpace+id”是比较麻烦而且容易出错的,也就是说,想把selectOne方法的第一个参数给去掉。
所以,mybatis 还提供了一种执行操作的方式,类似于这样:
try (SqlSession session = sqlSessionFactory.openSession()) {
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);
}
这个的逻辑基本上是说,我创建一个接口,我的接口全限定名和xml配置的nameSpace保持一致,然后接口方法名称和xml配置的id保持一致,这样,我就可以通过接口方法的全限定名来在xml中找到自己对应的sql。这个一对一的假定逻辑也就提供了生成接口实现的可能,大概实现的方法是这样的:
public Blog selectBlog(long id){
return (Blog) session.selectOne("{方法全限定名}", id);
}
所以,在mybatis中,我们只要能够获取session,那就可以通过session获取接口实现,就可以执行所有的访问数据库的方法了。
6.mybatis和springboot是怎么结合的?如何配置多数据源?
首先,sqlsessionFactoryBuilder sqlsessionFactory sqlsession的创建都被封装了起来,只要按照spring或者springboot提供的方式去写配置文件,我们就可以配置session。
因为springboot使用的是依赖注入的方式,所以我们希望在访问数据库的地方可以直接注入Mapper接口的实现。
第一步,我们需要知道哪些接口是需要mybatis生成实现的,springboot通过@MapperScanner配置。
然后,在启动的时候这些扫描到的Mapper接口会依据mapper.xml动态生成接口的实现,一般可以通过“BlogMapper mapper = session.getMapper(BlogMapper.class)”这种方式来生成实现。
最后将这些生成的实现纳入到上下文的管理中,就可以直接注入了。
因为大多数的应用程序都使用的是单数据源,所以springboot对单数据源的配置做了很好的封装,只要在application.properties中配置几个参数就可以了,如下:
## mybatis配置
mybatis.mapper-locations=classpath*:/mapper/**/*.xml
mybatis.config-location=classpath:/config/mybatis-config.xml
## 连接池配置
## 数据库地址
spring.datasource.url=jdbc:mysql://192.168.1.1:3306/db?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.type=org.apache.commons.dbcp2.BasicDataSource
spring.datasource.username=root
spring.datasource.password=666
在单数据源的配置中,DataSource和SqlSessionFactory等都封装了默认的,但是如果使用多数据源的话,就需要单独配置了:
配置类:
@Configuration
@MapperScan(basePackages = "com.dao", sqlSessionFactoryRef = "mysqlSqlSessionFactory")
public class MysqlDataSourceConfig {
//配置数据源
@Bean(name = "mysqlDataSource")
@Primary
@ConfigurationProperties(prefix = "spring.datasource.mysql")
public DataSource getMysqlDateSource() {
return DataSourceBuilder.create().build();
}
//配置factory
@Bean(name = "mysqlSqlSessionFactory")
@Primary
public SqlSessionFactory test1SqlSessionFactory(@Qualifier("mysqlDataSource") DataSource datasource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(datasource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:/mapper/**/*.xml"));
bean.setConfigLocation(new PathMatchingResourcePatternResolver().getResource("classpath:/config/mybatis-config.xml"));
return bean.getObject();
}
配置文件:
spring.datasource.mysql.jdbc-url=jdbc:mysql://192.168.1.1:3306/db?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
spring.datasource.mysql.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.mysql.type=org.apache.commons.dbcp2.BasicDataSource
spring.datasource.mysql.username=root
spring.datasource.mysql.password=666
如果增加数据源的话,上面的配置再来一对就好了。
到这里就结束了,谢谢大家,如有问题,欢迎探讨。
注:这篇文章主要讲的是为什么,很多代码都是删减过的,所以不适合直接使用。
附录:
mybatis-config.xml