一种超级简单的Self-Attention ——keras 实战
作者:王同学死磕技术
链接:https://www.jianshu.com/p/0f0c674837e3
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Attention技术在 NLP 模型中几乎已经成了不可或缺的重要组成部分,最早Attention主要应用在机器翻译中起到了文本对齐的作用,比如下图,Attention 矩阵会将 法语的 La Syrie 和英语的 Syrie 对齐,Attention 机制极大的提升了机器翻译模型的性能。

而最近各种花式的Attention机制相继被提出,同时这些Attention机制也不断的刷新着各种NLP任务的SOTA(state of the art)。Attention 机制 一般用于RNN,其主要思想是引入一个外部的权重得分值,对RNN每个时刻Cell的输出做一个重要度打分。由于RNN本质上还是一个特征抽取的过程,所以Attention机制的目标是帮助我们自动找出RNN的哪个时刻Cell的输出是强特,如果是RNN的输入是一个句子,我们就希望Attention机制能够帮我们找出,句子中的哪个词是比较关键的词 。通俗的说法就是Attention机制使模型在做任务时,将注意力主要集中在了对任务有帮助的的重要的特征上面。
广义的Attention机制
尽管上文通过RNN 引出了Attention这个概念,但是它并不是只适用于RNN ,至于Attention机制比较广义的定义,我们可以参考Google 在2017年提出的Attention is all your need:Attention机制 包含 一个Query,一个Key和一个Value,其中Key和Value向量是一一对映得,如果是文本任务的话,意味着说Key 和 Value 表示的是同一句话(可能只是表示方式不同,通过了不同的参数进行特征变换)。然后 Query和Key通过某种运算得到 权重得分值 去选择 Value 中重要的特征去做任务。
其具体过程大致分为2个步骤:
- 将Query和Key 经过某种数学运算的结果通过softmax激活函数激活 就可以得到上文所说的权重得分值
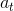 ,而这个Query 和 Key,在不同的任务中可能是不同东西。比如
,而这个Query 和 Key,在不同的任务中可能是不同东西。比如
- 在基于aspect的情感分析中,Query指的是 aspect,Key指的是句子;
- 在阅读理解任务中 Query指的是问题,Key指的是文档;
- 而在简单的文本分类任务中,Query 和 Key 甚至都可以指同一个句子,也就是我们经常提到self-attention,当然self-attention 也有几种不同的操作方式,这里笔者就不展开说了。
至于而这个权重得分值如何计算得到,有下面几种方式,其中 可以理解成上文的Query ,
可以理解成上文的Query ,![]() 可以理解成上文的Key:
可以理解成上文的Key:

2.将权重得分值和 Value做加权求和或者加权平均,得到最终的特征表示。而Value 和Key指代的东西几乎一样,只不过表示方式不同(可能通过了不同的参数进行特征变换)。
- 在基于aspect的情感分析中,Value指的是句子;
- 在阅读理解任务中Value指的是文档;
- 而在简单的文本分类任务中,Value依然指的是句子。
超级简单的Self-attention
而笔者今天实战的文本分类就是介绍是一种很简单的self-attention机制 ,如下图所示:将 RNN中每个时刻的输出 通过一个层感知机然后进行softmax激活得到权重得分值 ,再反过来将权重得分值 和 RNN中每个时刻的输出 进行加权求和,得到句子最终的特征表示。

实战部分
这里笔者采用了两种不同的attention模式。
from keras.datasets import imdb
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Embedding ,Dense ,merge,Input,LSTM,Permute,Softmax,Lambda,Flatten,CuDNNGRU
from keras import Model
import keras.backend as K
from keras.utils import to_categorical
import os
max_len = 200
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000)
train_data_pad = pad_sequences(train_data,padding="post",maxlen = max_len )
test_data_pad = pad_sequences(test_data,padding="post",maxlen = max_len )
train_labels_input = to_categorical(train_labels)
test_labels_input = to_categorical(test_labels)基于 特征词向量 整体的 attetion
即最后权重得分是一个标量,将其特征词向量相乘 ,对特征词向量每个维度进行同样的缩放操作。
K.clear_session()
input_ = Input(shape=(max_len,))
words = Embedding(10000,100,input_length=max_len)(input_)
sen = CuDNNGRU(64,return_sequences=True)(words) #[b_size,maxlen,64]
#attention
attention_pre = Dense(1, name='attention_vec')(sen) #[b_size,maxlen,1]
attention_probs = Softmax()(attention_pre) #[b_size,maxlen,1]
attention_mul = Lambda(lambda x:x[0]*x[1])([attention_probs,sen])
output = Flatten()(attention_mul)
output = Dense(32,activation="relu")(output)
output = Dense(2, activation='softmax')(output)
model = Model(inputs = input_ , outputs = output)
model.compile(loss="categorical_crossentropy",optimizer="adam",metrics=["acc"])
model.summary()
model.fit(train_data_pad,train_labels_input,batch_size=64,epochs=2,validation_data=(test_data_pad,test_labels_input))基于 特征词向量 每个维度的attention
即最后 权重得分是一个向量 ,和特征词向量做element-wise的相乘,对特征词向量每个维度进行不同的缩放操作。
K.clear_session()
input_ = Input(shape=(max_len,))
words = Embedding(10000,100,input_length=max_len)(input_)
sen = CuDNNGRU(64,return_sequences=True)(words) #[b_size,maxlen,64]
#attention
attention_pre = Dense(64, name='attention_vec')(sen) #[b_size,maxlen,64]
attention_probs = Softmax()(attention_pre) #[b_size,maxlen,64]
attention_mul = Lambda(lambda x:x[0]*x[1])([attention_probs,sen])
output = Flatten()(attention_mul)
output = Dense(32,activation="relu")(output)
output = Dense(2, activation='softmax')(output)
model = Model(inputs = input_ , outputs = output)
model.compile(loss="categorical_crossentropy",optimizer="adam",metrics=["acc"])
model.summary()
model.fit(train_data_pad,train_labels_input,batch_size=64,epochs=2,validation_data=(test_data_pad,test_labels_input))