CS224n-winter2019 exploring_word_vectors
这里写自定义目录标题
- 第一次写博客,不到之处请见谅。
- 词向量
- part1 基于计数的词向量
- 绘制共生词嵌入
- Question 1.1 实现不同单词
- Question 1.2:实现共现矩阵
- 实现降到$k$维
- Question 1.4: Implement plot_embeddings
- Question 1.5: Co-Occurrence Plot Analysis
- Part 2: Prediction-Based Word Vectors
- Question 2.1: Word2Vec Plot Analysis
- Cosine Similarity
- Question 2.2: Polysemous Words
- Question 2.3: Synonyms & Antonyms
- Solving Analogies with Word Vectors
- Question 2.4: Finding Analogies
- Question 2.5: Incorrect Analogy
- Question 2.6: Guided Analysis of Bias in Word Vectors
- Question 2.7: Independent Analysis of Bias in Word Vectors
- 点个赞呗
第一次写博客,不到之处请见谅。
# All Import Statements Defined Here
# Note: Do not add to this list.
# All the dependencies you need, can be installed by running .
# ----------------
import ssl
_create_unverified_https_context = ssl._create_unverified_context
ssl._create_default_https_context = _create_unverified_https_context
import sys
assert sys.version_info[0]==3
assert sys.version_info[1] >= 5
from gensim.models import KeyedVectors
from gensim.test.utils import datapath
import pprint
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [10, 5]
import nltk
nltk.download('reuters')
from nltk.corpus import reuters
import numpy as np
import random
import scipy as sp
from sklearn.decomposition import TruncatedSVD
from sklearn.decomposition import PCA
START_TOKEN = ''
END_TOKEN = ''
np.random.seed(0)
random.seed(0)
# ----------------
导包存在出现连接不上服务器的问题,私自下载好了reuters压缩包,放在了C:\Users\Administrator\AppData\Roaming\nltk_data\corpora下面,注意,Roaming是隐藏文件夹。
词向量
字向量通常用作下游NLP任务的基本组件,例如,问答系统,文本生成,文本翻译等。因此,建立对词向量优缺点的直观印象很重要。在这里,您将探讨两种类型的词向量:从共现矩阵派生的和通过word2vec派生的。
注释:词向量和词嵌入经常可以互换使用。词向量的意思是我们在低维空间编码单词的含义。正如维基百科描述的那样,“从概念上讲,它涉及从每个单词一维空间到具有更低维度的连续向量空间的数学嵌入”。
part1 基于计数的词向量
大多数词向量模型来源自下面的想法:
你应该把单词放在他原来的地方理解 https://en.wikipedia.org/wiki/John_Rupert_Firth (科学上网)许多单词向量实现是由类似的单词(即,近似的)同义词将在类似的上下文中使用的想法驱动的。结果,类似的单词通常与单词的共享子集(即上下文)一起被说出或写入。通过检查这些上下文,我们可以尝试为我们的单词开发嵌入。 考虑到这种直觉,构建单词向量的许多“旧学派”方法依赖于单词计数。 在这里,我们详细阐述其中一种策略,共现矩阵(更多信息,请参见http://web.stanford.edu/class/cs124/lec/vectorsemantics.video.pdf或https://medium.com/data-science-group-iitr/word-embedding-2d05d270b285)。
共现
共现矩阵计算在某些上下文中单词共同出现的频率。给定文档中某个单词 w i w_i wi,考虑到它周围的几个单词出现的次数。假设我们窗口大小为 n n n,即文档中该单词前面和后面 n n n个。我们建立了一个共现矩阵 M M M,这是一个按字的对称矩阵, M i j M_{ij} Mij是 w j w_j wj出现在 w i w_i wi上下文的次数。
例如
文档1:“all that glitters is not gold”
文档2: “all is well that ends well”

注释:
在NLP中,我们经常添加START和END标记来表示句子,段落或文档的开头和结尾。 在这种情况下,我们想象封装每个文档的START和END标记,例如“START所有闪烁的不是金子END”,并在我们的共现计数中包括这些标记。
该矩阵的行(或列)提供一种类型的单词向量(基于单词 - 单词共现的那些),但是这些向量通常很大(语料库中不同单词的数量是线性的)。因此,我们接下来要进行降维。特别是,我们将运行SVD(奇异值分解),这是一种广义PCA(主成分分析),用于选择前 k k k主成分。 这是使用SVD降低降维的可视化。在这张图片中,我们的共生矩阵是 A A A, n n n行对应 n n n个words。 我们获得了一个完整的矩阵分解,奇异值在对角 S S S矩阵中排序,我们新的,更短的长度 k k k单词向量在 U k U_k Uk中。

这种降维的共现表示保留了单词之间的语义关系,例如, 医生和医院将比医生和狗更近。
绘制共生词嵌入
在这里,我们将使用Reuters(商业和财经新闻)语料库。 如果您尚未运行此页面顶部的导入单元格,请立即运行(单击它并按SHIFT-RETURN)。 该语料库包含10,788个新闻文件,总计130万字。这些文件涵盖90个类别,分为测试集和训练集。我们在下面提供了read_corpus函数,它只从“crude”(即有关石油,天然气等的新闻文章)类别中提取文章。 该函数还为每个文档和小写单词添加了START和END标记。 您没有执行任何其他类型的预处理。
def read_corpus(category="crude"):
""" Read files from the specified Reuter's category.
Params:
category (string): category name
Return:
list of lists, with words from each of the processed files
"""
## files为docement列表
files = reuters.fileids(category)
# 返回结果是的列表里面很多个小列表,每个小列表是一篇文章
# [START_TOKEN] + [ w.lower()for f in files for w in list(reuters.words(f)) ]+ [END_TOKEN] 这种表示是所有文章在一个列表中
return [[START_TOKEN] + [w.lower() for w in list(reuters.words(f))] + [END_TOKEN] for f in files]
路透社新闻相互覆盖,即一条新闻包含好几个主题,即文件和类别是一对多的关系。例如:
查询主题为baley的文章,reuters.fileids(‘barley’)
-> [‘test/15618’, ‘test/15649’, ‘test/15676’, ‘test/15728’, ‘test/15871’, …]
查询某个文章的主题 reuters.categories(‘training/9865’)
-> [‘barley’, ‘corn’, ‘grain’, ‘wheat’]
reuters_corpus = read_corpus()
pprint.pprint(reuters_corpus[:1], compact=True, width=100)
[’’, ‘japan’, ‘to’, ‘revise’, ‘long’, ‘-’, ‘term’, ‘energy’, ‘demand’, ‘downwards’, ‘the’,
‘ministry’, ‘of’, ‘international’, ‘trade’, ‘and’, ‘industry’, ‘(’, ‘miti’, ‘)’, ‘will’, ‘revise’,
‘its’, ‘long’, ‘-’, ‘term’, ‘energy’, ‘supply’, ‘/’, ‘demand’, ‘outlook’, ‘by’, ‘august’, ‘to’,
‘meet’, ‘a’, ‘forecast’, ‘downtrend’, ‘in’, ‘japanese’, ‘energy’, ‘demand’, ‘,’, ‘ministry’,
‘officials’, ‘said’, ‘.’, ‘miti’, ‘is’, ‘expected’, ‘to’, ‘lower’, ‘the’, ‘projection’, ‘for’,
‘primary’, ‘energy’, ‘supplies’, ‘in’, ‘the’, ‘year’, ‘2000’, ‘to’, ‘550’, ‘mln’, ‘kilolitres’,
‘(’, ‘kl’, ‘)’, ‘from’, ‘600’, ‘mln’, ‘,’, ‘they’, ‘said’, ‘.’, ‘the’, ‘decision’, ‘follows’,
‘the’, ‘emergence’, ‘of’, ‘structural’, ‘changes’, ‘in’, ‘japanese’, ‘industry’, ‘following’,
‘the’, ‘rise’, ‘in’, ‘the’, ‘value’, ‘of’, ‘the’, ‘yen’, ‘and’, ‘a’, ‘decline’, ‘in’, ‘domestic’,
‘electric’, ‘power’, ‘demand’, ‘.’, ‘miti’, ‘is’, ‘planning’, ‘to’, ‘work’, ‘out’, ‘a’, ‘revised’,
‘energy’, ‘supply’, ‘/’, ‘demand’, ‘outlook’, ‘through’, ‘deliberations’, ‘of’, ‘committee’,
‘meetings’, ‘of’, ‘the’, ‘agency’, ‘of’, ‘natural’, ‘resources’, ‘and’, ‘energy’, ‘,’, ‘the’,
‘officials’, ‘said’, ‘.’, ‘they’, ‘said’, ‘miti’, ‘will’, ‘also’, ‘review’, ‘the’, ‘breakdown’,
‘of’, ‘energy’, ‘supply’, ‘sources’, ‘,’, ‘including’, ‘oil’, ‘,’, ‘nuclear’, ‘,’, ‘coal’, ‘and’,
‘natural’, ‘gas’, ‘.’, ‘nuclear’, ‘energy’, ‘provided’, ‘the’, ‘bulk’, ‘of’, ‘japan’, “’”, ‘s’,
‘electric’, ‘power’, ‘in’, ‘the’, ‘fiscal’, ‘year’, ‘ended’, ‘march’, ‘31’, ‘,’, ‘supplying’,
‘an’, ‘estimated’, ‘27’, ‘pct’, ‘on’, ‘a’, ‘kilowatt’, ‘/’, ‘hour’, ‘basis’, ‘,’, ‘followed’,
‘by’, ‘oil’, ‘(’, ‘23’, ‘pct’, ‘)’, ‘and’, ‘liquefied’, ‘natural’, ‘gas’, ‘(’, ‘21’, ‘pct’, ‘),’,
‘they’, ‘noted’, ‘.’, ‘’]
Question 1.1 实现不同单词
编写一种方法来计算语料库中出现的不同单词(单词类型)。你可以用for循环来实现,但使用Python列表推导更有效率。
def distinct_words(corpus):
""" Determine a list of distinct words for the corpus.
Params:
corpus (list of list of strings): corpus of documents
Return:
corpus_words (list of strings): list of distinct words across the corpus, sorted (using python 'sorted' function)
num_corpus_words (integer): number of distinct words across the corpus
"""
corpus_words = []
num_corpus_words = -1
# ------------------
# Write your implementation here.
temp= [y for x in corpus for y in x]
corpus_words = sorted(set(temp))
num_corpus_words = len(corpus_words)
# ------------------
#返回的结果是语料库中的所有单词按照字母顺序排列的。
return corpus_words, num_corpus_words
Question 1.2:实现共现矩阵
写一个方法实现一个窗口大小为 n n n的共现矩阵(默认大小为4)
def compute_co_occurrence_matrix(corpus, window_size=4):
""" Compute co-occurrence matrix for the given corpus and window_size (default of 4).
Note: Each word in a document should be at the center of a window. Words near edges will have a smaller
number of co-occurring words.
For example, if we take the document "START All that glitters is not gold END" with window size of 4,
"All" will co-occur with "START", "that", "glitters", "is", and "not".
Params:
corpus (list of list of strings): corpus of documents
window_size (int): size of context window
Return:
M (numpy matrix of shape (number of corpus words, number of number of corpus words)):
Co-occurence matrix of word counts.
The ordering of the words in the rows/columns should be the same as the ordering of the words given by the distinct_words function.
word2Ind (dict): dictionary that maps word to index (i.e. row/column number) for matrix M.
"""
words, num_words = distinct_words(corpus)
M = None
word2Ind = {}
M = np.zeros((num_words, num_words))
# ------------------
word2Ind = {w:i for i,w in enumerate(words)}
for doc in corpus:
for i, word in enumerate(doc):
## 注意for的范围和循环条件
for j in range(i-window_size,i+window_size+1):
if j<0 or j>=len(doc):
continue
if j != i:
M[word2Ind[word], word2Ind[doc[j]]]+=1
# ------------------
return M, word2Ind
实现降到 k k k维
构造一种在矩阵上执行降维的方法,以生成k维嵌入。 使用SVD获取前k个分量并生成新的k维嵌入矩阵。
def reduce_to_k_dim(M, k=2):
""" Reduce a co-occurence count matrix of dimensionality (num_corpus_words, num_corpus_words)
to a matrix of dimensionality (num_corpus_words, k) using the following SVD function from Scikit-Learn:
- http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.TruncatedSVD.html
Params:
M (numpy matrix of shape (number of corpus words, number of number of corpus words)): co-occurence matrix of word counts
k (int): embedding size of each word after dimension reduction
Return:
M_reduced (numpy matrix of shape (number of corpus words, k)): matrix of k-dimensioal word embeddings.
In terms of the SVD from math class, this actually returns U * S
"""
n_iters = 10 # Use this parameter in your call to `TruncatedSVD`
M_reduced = None
print("Running Truncated SVD over %i words..." % (M.shape[0]))
# ------------------
SVD = TruncatedSVD(n_components=k, n_iter=n_iters)
M_reduced = SVD.fit_transform(M)
# ------------------
print("Done.")
return M_reduced
Question 1.4: Implement plot_embeddings
在这里,您将编写一个函数来绘制2D空间中的一组2D矢量。
def plot_embeddings(M_reduced, word2Ind, words):
""" Plot in a scatterplot the embeddings of the words specified in the list "words".
NOTE: do not plot all the words listed in M_reduced / word2Ind.
Include a label next to each point.
Params:
M_reduced (numpy matrix of shape (number of corpus words, k)): matrix of k-dimensioal word embeddings
word2Ind (dict): dictionary that maps word to indices for matrix M
words (list of strings): words whose embeddings we want to visualize
"""
# ------------------
for word in words:
coord = M_reduced[word2Ind[word]]
x = coord[0]
y = coord[1]
plt.scatter(x,y, marker='x', color='red')
plt.text(x, y, word, fontsize=9)
plt.show()
# ------------------
# ---------------------
# Run this sanity check
# Note that this not an exhaustive check for correctness.
# The plot produced should look like the "test solution plot" depicted below.
# ---------------------
print ("-" * 80)
print ("Outputted Plot:")
M_reduced_plot_test = np.array([[1, 1], [-1, -1], [1, -1], [-1, 1], [0, 0]])
word2Ind_plot_test = {'test1': 0, 'test2': 1, 'test3': 2, 'test4': 3, 'test5': 4}
words = ['test1', 'test2', 'test3', 'test4', 'test5']
plot_embeddings(M_reduced_plot_test, word2Ind_plot_test, words)
print ("-" * 80)

Question 1.5: Co-Occurrence Plot Analysis
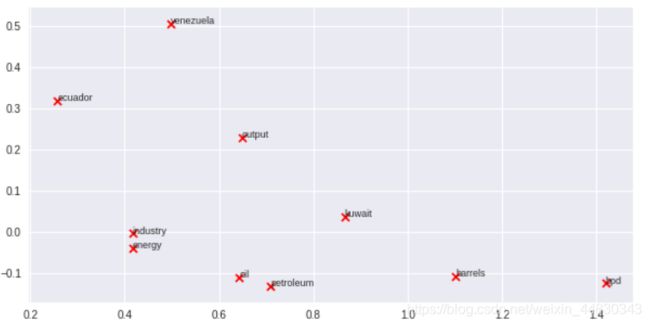
现在我们将把你写的所有部分组合在一起! 我们将在路透社“crude”语料库中计算固定窗口为5的共现矩阵。 然后我们将使用TruncatedSVD来计算每个单词的二维嵌入。 TruncatedSVD返回U * S,因此我们对返回的向量进行归一化,以便所有向量都出现在单位圆周围(因此接近度是方向接近度)。
运行以下单元格以生成绘图。 它可能需要几秒钟才能运行。 什么在二维嵌入空间中聚集在一起? 什么不会聚集在一起你可能认为应该有什么? 注意:“bpd”代表“每天桶数”,是原油主题文章中常用的缩写。
# -----------------------------
# Run This Cell to Produce Your Plot
# ------------------------------
reuters_corpus = read_corpus()
M_co_occurrence, word2Ind_co_occurrence = compute_co_occurrence_matrix(reuters_corpus)
M_reduced_co_occurrence = reduce_to_k_dim(M_co_occurrence, k=2)
# Rescale (normalize) the rows to make them each of unit-length
M_lengths = np.linalg.norm(M_reduced_co_occurrence, axis=1)
M_normalized = M_reduced_co_occurrence / M_lengths[:, np.newaxis] # broadcasting
words = ['barrels', 'bpd', 'ecuador', 'energy', 'industry', 'kuwait', 'oil', 'output', 'petroleum', 'venezuela']
plot_embeddings(M_normalized, word2Ind_co_occurrence, words)

Part 2: Prediction-Based Word Vectors
正如在课堂上讨论的那样,最近基于预测的单词向量已经变得流行,例如,word2vec。 在这里,我们将探讨word2vec生成的嵌入。 有关word2vec算法的更多详细信息,请重新阅读课堂笔记和演讲幻灯片。
def load_word2vec(embeddings_fp="./GoogleNews-vectors-negative300.bin"):
""" Load Word2Vec Vectors
Param:
embeddings_fp (string) - path to .bin file of pretrained word vectors
Return:
wv_from_bin: All 3 million embeddings, each lengh 300
This is the KeyedVectors format: https://radimrehurek.com/gensim/models/deprecated/keyedvectors.html
"""
embed_size = 300
print("Loading 3 million word vectors from file...")
## 自己下载的文件
wv_from_bin = KeyedVectors.load_word2vec_format(embeddings_fp, binary=True)
vocab = list(wv_from_bin.vocab.keys())
print("Loaded vocab size %i" % len(vocab))
return wv_from_bin
wv_from_bin = load_word2vec()
让我们直接比较word2vec嵌入与共生矩阵的嵌入。 运行以下单元格:
1、将300万个word2vec向量放入矩阵M中
2、运行reduce_to_k_dim(截断的SVD函数)将矢量从300维减少到2维。
def get_matrix_of_vectors(wv_from_bin):
""" Put the word2vec vectors into a matrix M.
Param:
wv_from_bin: KeyedVectors object; the 3 million word2vec vectors loaded from file
Return:
M: numpy matrix shape (num words, 300) containing the vectors
word2Ind: dictionary mapping each word to its row number in M
"""
words = list(wv_from_bin.vocab.keys())
print("Putting %i words into word2Ind and matrix M..." % len(words))
word2Ind = {}
M = []
curInd = 0
for w in words:
try:
M.append(wv_from_bin.word_vec(w))
word2Ind[w] = curInd
curInd += 1
except KeyError:
continue
M = np.stack(M)
print("Done.")
return M, word2Ind
M, word2Ind = get_matrix_of_vectors(wv_from_bin)
M_reduced = reduce_to_k_dim(M, k=2)
Question 2.1: Word2Vec Plot Analysis
words = ['barrels', 'bpd', 'ecuador', 'energy', 'industry', 'kuwait', 'oil', 'output', 'petroleum', 'venezuela']
plot_embeddings(M_reduced, word2Ind, words)
Cosine Similarity
现在我们有了单词向量,我们需要一种方法来根据这些向量量化单个单词之间的相似性。 一个这样的度量是余弦相似性。 我们将使用它来找到彼此“接近”和“远”的单词。
我们可以将n维向量看作n维空间中的点。 如果我们采用这种观点,L1和L2距离有助于量化“我们必须旅行”以获得这两点之间的空间量。 另一种方法是检查两个矢量之间的角度。
Question 2.2: Polysemous Words
找到一个多义词(例如,“leaves”或“scoop”),使得前10个最相似的词(根据余弦相似性)包含来自两个含义的相关词。 例如,“leaves”在前10名中都有“vanish”和“stalks”,“scoop”同时包含“handed_waffle_cone”和“lowdown”。 在找到之前,您可能需要尝试几个多义词。 请说明您发现的多义词以及前10名中出现的多重含义。
wv_from_bin.most_similar("happy")

Question 2.3: Synonyms & Antonyms
在考虑余弦相似度时,考虑余弦距离通常会更方便,它只是1 - 余弦相似度(??)。
找到三个单词(w1,w2,w3),其中w1和w2是同义词,w1和w3是反义词,但余弦距离(w1,w3)<余弦距离(w1,w2)。 例如,w1 =“happy”更接近w3 =“sad”而不是w2 =“happy”。
# ------------------
# Write your synonym & antonym exploration code here.
w1 = "sleep"
w2 = "nap"
w3 = "awake"
w1_w2_dist = wv_from_bin.distance(w1, w2)
w1_w3_dist = wv_from_bin.distance(w1, w3)
print("Synonyms {}, {} have cosine distance: {}".format(w1, w2, w1_w2_dist))
print("Antonyms {}, {} have cosine distance: {}".format(w1, w3, w1_w3_dist))
# ------------------
Synonyms sleep, nap have cosine distance: 0.38177746534347534
Antonyms sleep, awake have cosine distance: 0.4313364028930664
Solving Analogies with Word Vectors
Word2Vec向量具有解决类比的能力。
比如说: “man : king :: woman : x”, x是什么?
在下面的单元格中,我们将向您展示如何使用单词向量来查找x。 most_similar函数查找与positive列表中的单词最相似的单词,并且与negative列表中的单词最不相似。 类比的答案将是排名最相似的词(最大数值)。
pprint.pprint(wv_from_bin.most_similar(positive=['woman', 'king'], negative=['man']))
[(‘queen’, 0.7118192911148071),
(‘monarch’, 0.6189674139022827),
(‘princess’, 0.5902431011199951),
(‘crown_prince’, 0.5499460697174072),
(‘prince’, 0.5377321243286133),
(‘kings’, 0.5236844420433044),
(‘Queen_Consort’, 0.5235945582389832),
(‘queens’, 0.518113374710083),
(‘sultan’, 0.5098593235015869),
(‘monarchy’, 0.5087411999702454)]
Question 2.4: Finding Analogies
找到根据这些向量保持的类比的例子(即,预期的单词排在最前面)。 在您的解决方案中,请以x:y :: a:b的形式说明完整的类比。 如果您认为类比很复杂,请解释为什么类比在一两句话中成立。
pprint.pprint(wv_from_bin.most_similar(positive=['english','spain'], negative=['canada']))
[(‘spanish’, 0.5764416456222534),
(‘portugal’, 0.568500816822052),
(‘raul’, 0.543082594871521),
(‘lyk’, 0.5288429856300354),
(‘messi’, 0.5282317996025085),
(‘robben’, 0.5281049609184265),
(‘madrid’, 0.5262929201126099),
(‘barcelona’, 0.5260317325592041),
(‘Institute_ITRI_eng’, 0.5254518985748291),
(‘portuguese’, 0.522739589214325)]
Question 2.5: Incorrect Analogy
找一个根据这些向量不能保持的类比的例子。 在您的解决方案中,以x:y :: a:b的形式陈述预期的类比,并根据单词向量说明b的(不正确的)值。
pprint.pprint(wv_from_bin.most_similar(positive=['rome', 'spain'], negative=['italy']))
[(‘carlos’, 0.504329264163971),
(‘samuel’, 0.4907485842704773),
(‘albert’, 0.48940616846084595),
(‘dubai’, 0.48854902386665344),
(‘madrid’, 0.48699095845222473),
(‘jh’, 0.48649877309799194),
(‘cra’, 0.4857587218284607),
(‘eddie’, 0.4807842969894409),
(‘melrose’, 0.47857555747032166),
(‘andre’, 0.47524213790893555)]
Question 2.6: Guided Analysis of Bias in Word Vectors
重要的是要认识到我们的嵌入词隐含的偏见(性别,种族,性取向等)。
运行下面的单元格,检查(a)哪些术语与“women”和“boss”最相似,与“man”最相似,以及(b)哪些术语最类似于“男人”和“老板”,大多数 与“女人”不同。
# Run this cell
# Here `positive` indicates the list of words to be similar to and `negative` indicates the list of words to be
# most dissimilar from.
pprint.pprint(wv_from_bin.most_similar(positive=['woman', 'boss'], negative=['man']))
print()
pprint.pprint(wv_from_bin.most_similar(positive=['man', 'boss'], negative=['woman']))
[(‘bosses’, 0.5522644519805908),
(‘manageress’, 0.49151360988616943),
(‘exec’, 0.459408164024353),
(‘Manageress’, 0.45598435401916504),
(‘receptionist’, 0.4474116861820221),
(‘Jane_Danson’, 0.44480547308921814),
(‘Fiz_Jennie_McAlpine’, 0.44275766611099243),
(‘Coronation_Street_actress’, 0.44275569915771484),
(‘supremo’, 0.4409852921962738),
(‘coworker’, 0.4398624897003174)]
[(‘supremo’, 0.6097397804260254),
(‘MOTHERWELL_boss’, 0.5489562153816223),
(‘CARETAKER_boss’, 0.5375303626060486),
(‘Bully_Wee_boss’, 0.5333974361419678),
(‘YEOVIL_Town_boss’, 0.5321705341339111),
(‘head_honcho’, 0.5281980037689209),
(‘manager_Stan_Ternent’, 0.525971531867981),
(‘Viv_Busby’, 0.5256163477897644),
(‘striker_Gabby_Agbonlahor’, 0.5250812768936157),
(‘BARNSLEY_boss’, 0.5238943099975586)]
Question 2.7: Independent Analysis of Bias in Word Vectors
使用most_similar函数找到另一种情况,其中向量表现出一些偏差。 请简要说明您发现的偏见示例。
pprint.pprint(wv_from_bin.most_similar(positive=['woman','nurse'], negative=['man']))
[(‘registered_nurse’, 0.7375059127807617),
(‘nurse_practitioner’, 0.6650707721710205),
(‘midwife’, 0.6506887674331665),
(‘nurses’, 0.6448697447776794),
(‘nurse_midwife’, 0.6239830255508423),
(‘birth_doula’, 0.5852459669113159),
(‘neonatal_nurse’, 0.5670714974403381),
(‘dental_hygienist’, 0.5668443441390991),
(‘lactation_consultant’, 0.566798985004425),
(‘respiratory_therapist’, 0.5652169585227966)]