leetcode-131 分割回文串 go 实现
题目描述
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。返回 s 所有可能的分割方案。分割回文串
输入:
“aab”
输出:
[ [“aa”,“b”], [“a”,“a”,“b”] ]
题解
基本思想参考 dfs+回溯 题解方案,用go语言重新实现了一遍。中间碰到了暴露了自己回溯、动态规划、递归短板,同时一窥 go语言 slice 用法之谜。
package main
import (
"unicode"
"fmt"
)
func main() {
var s string
s = "cbbbcc"
fmt.Println(partition(s))
}
func partition(s string) [][]string {
result := &[][]string{}
list := []string{}
dfs(list,0, s, result)
return *result
}
//实现深度优先遍历及回溯
func dfs(tmpRes []string, index int, s string, result *[][]string) {
if index == len(s){
/*
这是错误的解法:错误出在append slice本身的特性上
*/
//*result = append(*result, tmpRes)
//以下是目前水平找到的破解之法,请各位不吝赐教
tmp := make([]string, len(tmpRes))
for index, v:=range tmpRes{
tmp[index] = v
}
*result = append(*result, tmp)
}
for i := index; i < len(s); i++{
subStr := s[index:i+1]
if methods(subStr){
tmpRes = append(tmpRes, subStr)
fmt.Println("index:%d i:%d, tmpRes:%s", index, i, tmpRes)
dfs(tmpRes,i+1, s, result)
tmpRes = tmpRes[:len(tmpRes)-1]
fmt.Println("index:%d i:%d, tmpRes:%s", index, i, tmpRes)
}
}
}
//实现回文的判断
func methods(s string) bool {
var data []byte = []byte{}
for _, v :=range s{
if unicode.IsDigit(v) || unicode.IsLetter(v){
if !unicode.IsSpace(v){
data = append(data, byte(unicode.ToLower(v)))
}
}
}
for i := 0; i <=len(data)/2 - 1; i ++ {
if data[i] != data[len(data)-i -1] {
return false
}
}
return true
}
破解slice之谜
此处先不讲如何解本道算法题目,只是呈现如何在解题中破解这次困惑的。
现象
如果用本文提到的错误解法得到的结果:
[[c b b b cc c] [c b b b cc] [c b bb c c] [c b bb cc] [c bb b c c] [c bb b cc] [c bbb cc c] [c bbb cc] [cbbbc c]]
正解应该是:
[[c b b b c c] [c b b b cc] [c b bb c c] [c b bb cc] [c bb b c c] [c bb b cc] [c bbb c c] [c bbb cc] [cbbbc c]]
从result第一个元素就可以看出不对了,真是失之毫厘谬以千里啊!到底是为什么呢?debug见分晓,先看怎么错的吧?,以下是debug信息之一:
> main.dfs() E:/WORK/GO/src/testGo/src/main/code.go:30 (PC: 0x4a928d)
Warning: listing may not match stale executable
25: //for index, v:=range tmpRes{
26: // tmp[index] = v
27: //}
28: //*result = append(*result, tmp)
29: *result = append(*result, tmpRes)
=> 30: }
31: for i := index; i < len(s); i++{
32: subStr := s[index:i+1]
33: if methods(subStr){
34: tmpRes = append(tmpRes, subStr)
35: fmt.Println("index:%d i:%d, tmpRes:%s", index, i, tmpRes)
p result
*[][]string len: 1, cap: 1, [
["c","b","b","b","c","c"],
]
p tmpRes
[]string len: 6, cap: 8, ["c","b","b","b","c","c"]
p &tmpRes[5]
(*string)(0xc00008a050)
p &result[0][5]
(*string)(0xc00008c050)
我们看到,result append tmpRes数组后 且tmpRes开始回溯前,result[0] 的元素每个值的地址与 tmpRes值的地址是一模一样的。因为是深度遍历及回溯,所以接着看debug信息(还是图片明显):
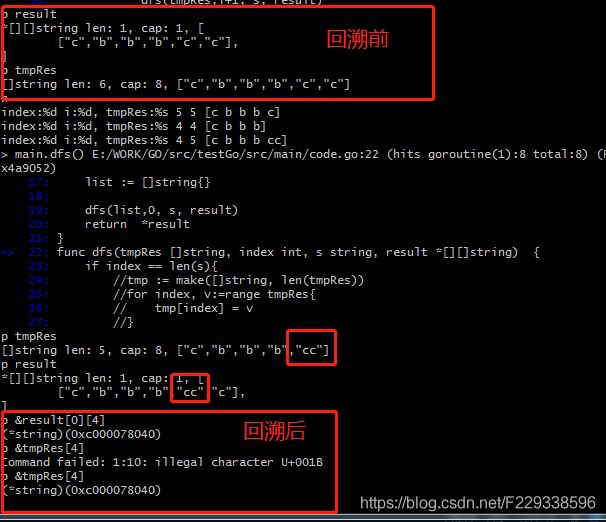
总结
上图的可以明显看出result第0个数组中第4个位置的值被回溯后tmpRes第4个位置的值修改了,append的啊,为何被修改呢?且这种修改发生在已经添加了一个回文字串后,tmpRes回溯的时候修改了上一个回文串对应位置的值,那么上一个已经添加过的回文串就会被修改。上面的错误结果中共有两处该现象,可自行再走一遍。
深入学习可以看看下面链接。
破解
其实本质就是slice自身结构的问题。
struct Slice
{ // must not move anything
byte* array; // actual data
uintgo len; // number of elements
uintgo cap; // allocated number of elements
};
这个结构有3个字段,第一个字段表示array的指针,第二个是表示slice的长度,第三个是表示slice的容量,注意:len和cap都不是指针。说明一个slice对象拥有的是数组的指针。
感谢这位大佬 【GoLang】深入理解slice len cap什么算法? 参数传递有啥蹊跷?