使用Keras和MINIST数据集实现简单的stacking
前言
最近做的项目要结题了,发现中期之后啥都没干,赶紧从0开始学习模型融合和RNN的一些基本知识,先套个模型出来再说。
这里主要是在实验的传感器还没到之前搭的一个学习用的demo,走一遍训练的流程。
大致的模型框架是两个基分类器分别使用全连接神经网络和LSTM/GRU网络,然后将预测结果做concate后,送入个简单的softmax回归输出。由于实在是没法使用在线的MINIST,所以用了coursera ML课程中的的手写数据集。对,就是Ng的那个.mat文件,原始数据维度是5000x400。

整个的demo主要利用Keras实现,sklearn库做K折交叉验证的划分。由于个人刚接触,还是个菜鸡,对于stacking的理解并不到位,可能在meta-classifier上有问题,还请多多指正。
基分类器的搭建与训练
模型搭建
基分类器主要是全连接神经网络和LSTM/GRU,LSTM和GRU分别与全连接网络做stacking看最后结果。
首先是全连接网络,这个就比较简单,这里直接贴代码:
def FC_Model():
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(400,)))#input layer
model.add(tf.keras.layers.Dense(20,activation = 'relu',name = 'hidden_layer'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
对于LSTM/GRU,大体的思路是:将一张图片的原始数据(400x1),变换为(20x20),将第一个20作为特征数目,第二个20作为时间步数,传入模型中训练。
Keras中LSTM/GRU层的第一个参数为units,即为隐藏单元的个数,关于这个的理解,可以参考这里。其实就是在LSTM的激活函数之前,ht-1+xt要乘以一个权值矩阵,将向量变换为h的大小,这个就是隐藏单元个数。第二个需要注意的参数是return_sequence,一般在最后一个LSTM/GRU单元为False,中间单元为True;如果为False,就只会输出最后一次的值,如果为True就输出所有序列的值。
def Lstm_Model(inputshape):
model = keras.models.Sequential()
input = keras.layers.Input(shape = inputshape)
model.add(input)
model.add(keras.layers.LSTM(100, return_sequences=True))
model.add(keras.layers.LSTM(10, return_sequences=False))
model.add(keras.layers.Dense(10,activation = 'softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
def GRU_Model(inputshape):
model = keras.models.Sequential()
input = keras.layers.Input(shape = inputshape)
model.add(input)
model.add(keras.layers.GRU(100, return_sequences=True))
model.add(keras.layers.GRU(10, return_sequences=False))
model.add(keras.layers.Dense(10,activation = 'softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
数据集处理与训练
然后是加载数据和训练,由于是采用stacking算法,那么就需要使用K折交叉验证训练,将K次训练的预测concatenate、K次的测试取均值之后再传入次级分类器。关于stacking算法的训练的详细解释,可以参考这里。
关于数据集的处理,先划分训练集和测试集
K=2#K为交叉验证的折数
data_dic = sio.loadmat(constants.path1+'/ex4data1.mat')#读取数据集
X = data_dic['X']#X is a 5000x400 matrix
Y =data_dic['y'].flatten()#flat Y,Y.shape = (5000,0)
Y[Y ==10] = 0 #吴恩达给的数据中,Y=10对应的是0
print("训练Dense模型输入1,训练LSTM模型输入2,GRU输入其他")#懒得写多个训练了
inputnum = input()
if(int(inputnum) ==1):
print("start init FCModel")
else :
X = X.reshape((5000,20,20))#对于LSTM/GRU,需要变更数据维度
seed = 7#设置随机种子
x_train,x_test,y_train,y_test = train_test_split(X,Y,test_size=0.2,random_state=0)
#划分训练集和测试集,测试集数目为1k
然后开始进行K折交叉验证,这里用的sklearn库的StratifiedKFold方法。注意:一定要设置随机种子!!!对于每个基分类器的训练,随机种子必须一样,保证测试集的信息不会泄露进而导致overfit!!!具体的解释可以参照这里。
kfold = StratifiedKFold(n_splits=K, shuffle=True, random_state=seed)
i=0
for train, test in kfold.split(x_train, y_train):
#注意:每次训练都要重新初始化模型,不能在训练好的模型上接着训练
if(int(inputnum)==1):
model = FC_Model()
elif(int(inputnum)==2):
model = Lstm_Model((20,20))
else :
model = GRU_Model((20,20))
model.fit(x_train[train], y_train[train], epochs=2, batch_size=10)
# evaluate the model
model.evaluate(x_train[test],y_train[test])
scores = model.predict(x_train[test])#在交叉验证集上做预测
testscores = model.predict(x_test)#在测试集上做预测
if(i==0):
trainprd = scores
trainlabel = y_train[test]
testprd = testscores
else:
trainprd = np.concatenate((trainprd,scores),axis = 0)
trainlabel = np.concatenate((trainlabel,y_train[test]),axis = 0)
#拼接预测Pi,y_train
testprd +=testscores
#将不同训练的预测值相加
i+=1
testprd /=i#对测试集的输出取均值
trainprd = np.concatenate((trainprd,trainlabel[:,np.newaxis]),axis = 1)
#trainprd为次级分类器的训练数据,在X的基础上加入一列Y,方便后续读取[X,Y]
然后将处理好的训练集和测试集的预测结果写入csv文件保存(实在是因为懒得多个模型一个个处理再一起concatenate,再训练,就分步做了)。
if(int(inputnum)==1):
np.savetxt("FCModel_train.csv", trainprd, delimiter=",")
testprd = np.concatenate((testprd,y_test[:, np.newaxis]),axis = 1)
np.savetxt("FCModel_test.csv", testprd, delimiter=",")
elif(int(inputnum)==2):
np.savetxt("LSTMModel_train.csv", trainprd, delimiter=",")
testprd = np.concatenate((testprd,y_test[:, np.newaxis]),axis = 1)
np.savetxt("LSTMModel_test.csv", testprd, delimiter=",")
else :
np.savetxt("GRUModel_train.csv", trainprd, delimiter=",")
testprd = np.concatenate((testprd,y_test[:, np.newaxis]),axis = 1)
np.savetxt("GRUModel_test.csv", testprd, delimiter=",")
那么基分类器部分就差不多完成了。
元分类器的搭建与训练
搭建元(次级)分类器
比较简单,直接贴代码:
def MetaClassifer():
inputA = tf.keras.layers.Input(shape = 20)
#z = tf.keras.layers.Dense(10, activation="relu")(inputA)
z = tf.keras.layers.Dense(10,activation = 'softmax')(inputA)
model = tf.keras.models.Model(inputs=inputA, outputs=z)
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
实际上这里有修改,可以明显看出来。原来是打算做2个Dense层,但是后来测试发现:两层和一层结果差不多…就直接修改了。
读取并处理数据集
fctrain = np.loadtxt("FCModel_train.csv", delimiter=",")
fctest = np.loadtxt("FCModel_test.csv", delimiter=",")
#读取全连接神经网络的预测值
lstmtest = np.loadtxt("GRUModel_test.csv", delimiter=",")
lstmtrain = np.loadtxt("GRUModel_train.csv", delimiter=",")
读取LSTM/GRU的预测值
Y_train = fctrain[:,10]
Y_test = fctest[:,10]
#由于拼接了原有标签,因此需要提取子矩阵作为Y
X_train = np.concatenate((fctrain[:,0:10],lstmtrain[:,0:10]),axis = 1)
X_test = np.concatenate((fctest[:,0:10],lstmtest[:,0:10]),axis = 1)
#从原始数据集中提取X,并将两个模型的预测值做concatenate
开始训练
model = MetaClassifer()
model.fit(X_train, Y_train, epochs=10, batch_size=10)
model.evaluate(X_test,Y_test)
结果
结果非常amazing啊,我都不知道为什么。首先是全连接神经网络的参数多于LSTM(好像),但是训练速度前者快多了。。。其次是准确率,同样训练10epochs,全连接网络的准确率接近95%,而LSTM刚过90%。
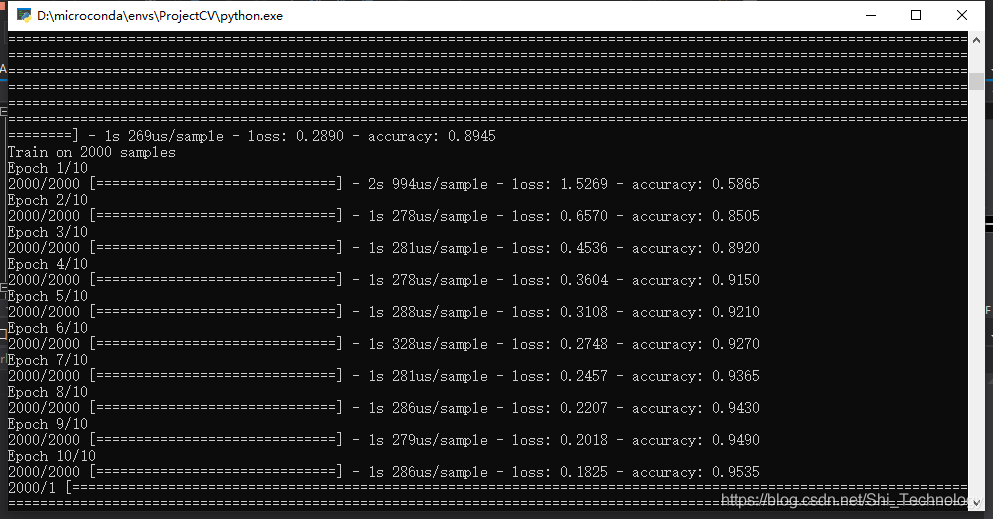
这是LSTM训练10次之后
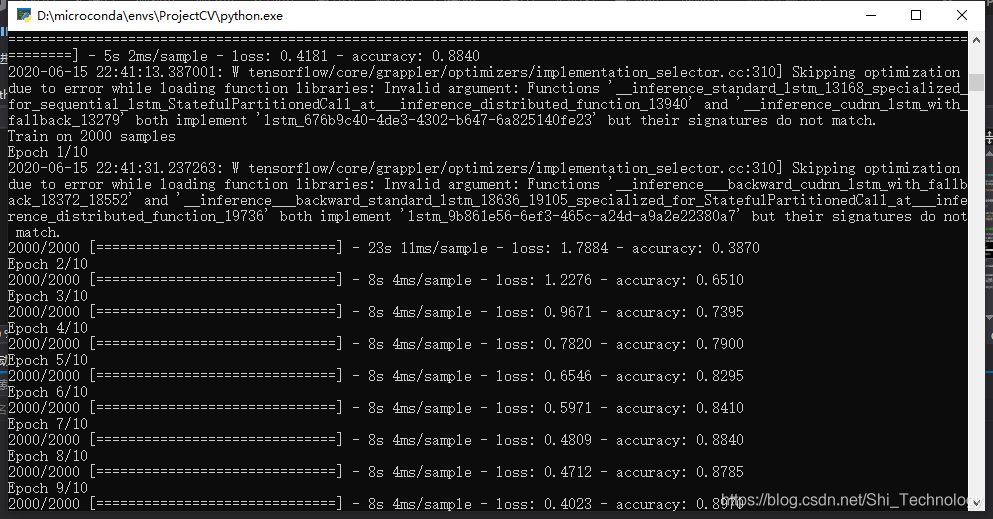
这是GRU训练10次后:
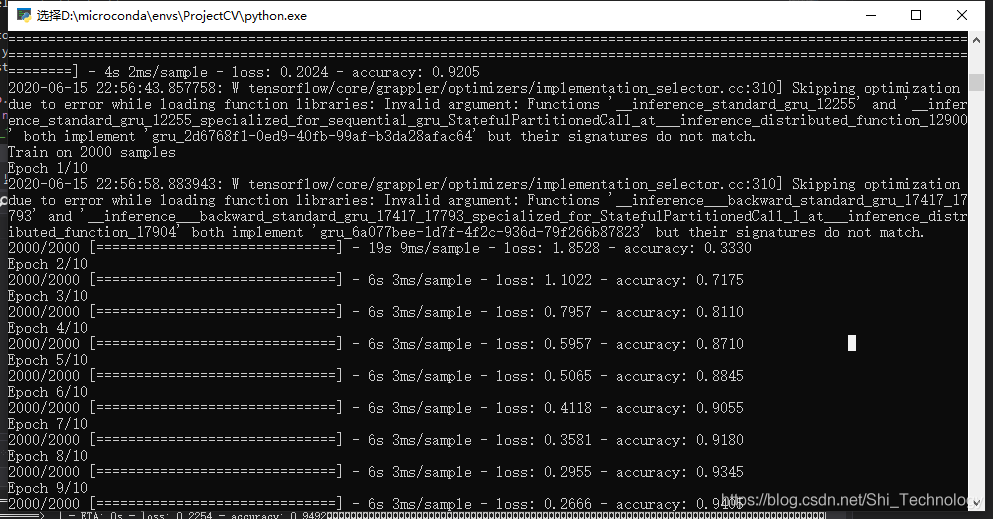
.最后一点更加神奇,无论是全连接网络是80%的准确率还是95%的准确率,无论是LSTM还是GRU融合,最后模型的准确率总会稳定在92-93%…
LSTM+FC
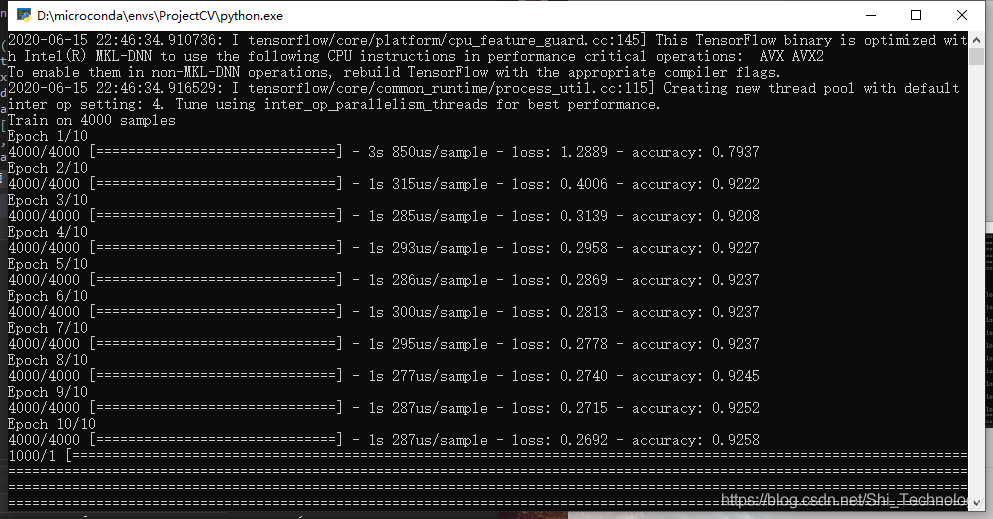
GRU+FC
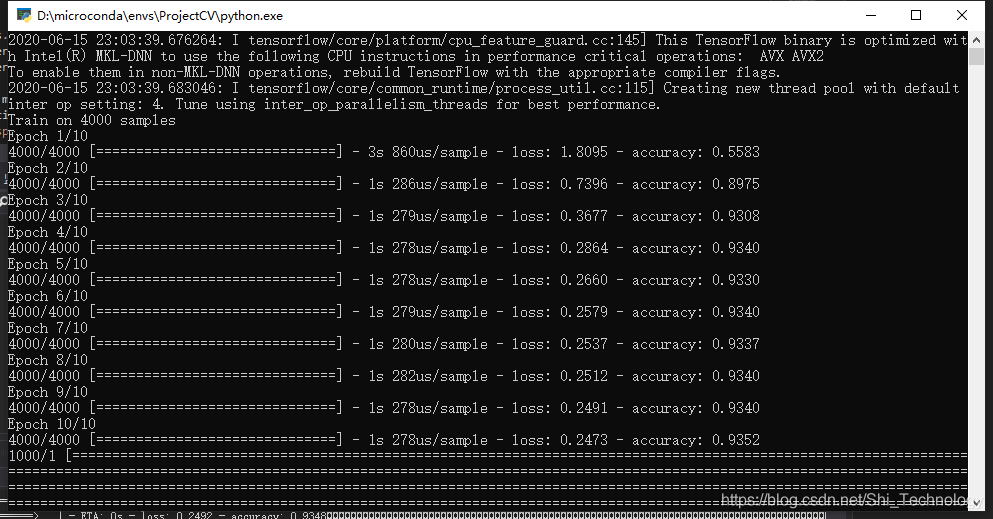
我对于stacking已经迷惑了,这到底是表现好了呢,还是表现取中间了呢。。。