CS224N刷题——Assignment3.1_A window into NER
Assignment #3
A primer on named entity recognition
这一节作业我们会建立几种不同的模型来实现命名实体识别(NER)。NER是信息抽取的一个子任务,旨在将文本中的命名实体定位并分类为预先定义的类别,如人名、组织、地点、时间表达式、数量、货币值、百分比等。对于上下文中给定的一个单词,预测它是否代表下列四个类别中的一个:
- 人名(PER):例如“Martha Stewart”,“Obama”,“Tim Wagner”等等,代词“he”或者“she”不考虑为命名实体。
- 组织(ORG):例如“American Airlines”,“Goldman Sachs”,“Department of Defense”。
- 地点(LOC):例如“Germany”,“Panama Strait”,“Brussels”,不包括未命名地点,比如“the bar”或者“the farm”。
- 其他(MISC):例如“Japanese”,“USD”,“1000”,“Englishmen”。
我们将此定义为一个五分类问题,使用上面的四个类和一个空类(O)来表示不代表命名实体的单词(大多数单词都属于此类别)。对于跨越多个单词的实体(“Department of Defense”),每个单词都被单独标记,并且每个连续的非空标记序列都被视为一个实体。
下面是一个示例句子(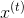 ),其中每个单词上面都被标记了命名实体(
),其中每个单词上面都被标记了命名实体(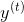 )以及系统生成的假设预测(
)以及系统生成的假设预测(![]() ):
):

在上述例子中,系统错误地预测“American”为MISC类,并且忽视了“Airlines”和“Corp”。总的来说,它预测了三个实体,“American”,“AMR”,“Tim Wagner”。为了评测NER系统输出的质量,我们关注准确率,召回率和F1值。特别地,我们会在token级别和命名实体级别都报告准确率,召回率和F1值。在之前的例子中:
-
准确率计算为预测的正确非空标签与预测的非空标签总数之比(上述例子中,p=3/4)。
-
召回率计算为预测的正确非空标签与正确的非空标签总数之比(上述例子中,r=3/6)。
-
F1是准确率和召回率的调和平均值(上述例子中,F1=6/10)。
对于实体级别的F1:
- 准确率是预测实体名称跨度的分数,与黄金标准评估数据中的跨度完全一致。在我们的示例中,“AMR”将被错误地标记,因为它不包括整个实体,即“AMR Corp.”,而“American”也一样,我们将得到1/3的准确率得分。
- 召回率同样是黄金标准中出现在预测中完全相同位置的名称数量。在这里,我们会得到1/3分的召回率得分。
- 最后,F1值仍然是两者的调和平均值,例子中为1/3。
我们的模型还输出一个单词级别的混淆矩阵。混淆矩阵是一种特定的表格布局,允许可视化分类性能。矩阵的每一列表示预测类别中的实例,而每一行表示实际类别中的实例。这个名字源于这样一个事实,即它可以很容易地看出系统是否混淆了两个类(即通常错误地将一个类标记为另一个类)。
1.A window into NER
让我们来看一个简单的基线模型,它使用来自周围窗口的特征分别预测每个单词的标签。

图1显示了一个输入序列的例子和这个序列的第一个窗口。令![]() 为长度为T的输入序列,
为长度为T的输入序列,![]() 为长度为T的输出序列。每个元素和都是代表序列中索引为t的单词的one-hot向量。在基于窗口的分类器中,每个输入序列被分割成T个新的数据点,每个点代表一个窗口及其标签。通过将的左右两侧的w个单词连在一起,从周围的窗口构造一个新的输入:
为长度为T的输出序列。每个元素和都是代表序列中索引为t的单词的one-hot向量。在基于窗口的分类器中,每个输入序列被分割成T个新的数据点,每个点代表一个窗口及其标签。通过将的左右两侧的w个单词连在一起,从周围的窗口构造一个新的输入:![]() ,我们继续使用作为它的标签。对于在句首以标记为中心的窗口,我们在窗口的开头添加特殊的开始标记(
,我们继续使用作为它的标签。对于在句首以标记为中心的窗口,我们在窗口的开头添加特殊的开始标记(
有了这些,每个输入和输出都有一个统一的长度(分别为w和1),我们可以使用一个简单的前馈神经网络从![]() 预测:
预测:
作为一个从每个窗口预测标签的简单但有效的模型,我们会使用一个带ReLU激活的单隐层,与softmax输出层相结合,以及交叉熵损失:
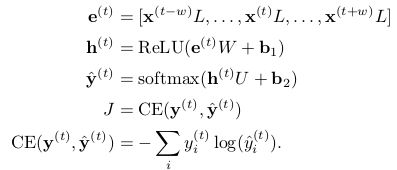
其中![]() 是词向量,
是词向量,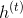 是H维的,
是H维的,![]() 是C维的,其中V是词表的大小,D是词向量的大小,H是隐藏层的大小,C是预测类别的数量(这里是5)。
是C维的,其中V是词表的大小,D是词向量的大小,H是隐藏层的大小,C是预测类别的数量(这里是5)。
(a)
i.提供两个包含具有模棱两可类型的命名实体的句子示例(例如,实体可以是个人或组织,也可以是组织或非实体)。
1)"Spokesperson for Levis, Bill Murray, said...",其中Levis可能是人名也可能是组织。
2)"Heartbreak is a new virus,",其中Heartbreak可能是其他命名实体(实际上是virus的名字),也可能只是简单的名词。
ii.为什么使用单词本身以外的特征来预测命名实体标签很重要?
通常命名实体会是稀有词,例如人名或者"heartbreak",使用大小写这样的特征使得系统具有泛化性。
iii.描述至少两个有助于预测单词是否属于命名实体的特征(单词除外)。
单词大小写和词性。
(b)
i.如果窗口大小为w,则![]() 的维度为多少?
的维度为多少?
![]()
![]()
![]()
ii.预测序列长度为T的标签的计算复杂度是多少?
![]()
(c)实现基于窗口的分类器模型:
i.在make_windowed_data函数中将一个输入序列的batch转换为一个窗口化的输入-输出对的batch。
def make_windowed_data(data, start, end, window_size = 1):
"""Uses the input sequences in @data to construct new windowed data points.
TODO: In the code below, construct a window from each word in the
input sentence by concatenating the words @window_size to the left
and @window_size to the right to the word. Finally, add this new
window data point and its label. to windowed_data.
Args:
data: is a list of (sentence, labels) tuples. @sentence is a list
containing the words in the sentence and @label is a list of
output labels. Each word is itself a list of
@n_features features. For example, the sentence "Chris
Manning is amazing" and labels "PER PER O O" would become
([[1,9], [2,9], [3,8], [4,8]], [1, 1, 4, 4]). Here "Chris"
the word has been featurized as "[1, 9]", and "[1, 1, 4, 4]"
is the list of labels.
start: the featurized `start' token to be used for windows at the very
beginning of the sentence.
end: the featurized `end' token to be used for windows at the very
end of the sentence.
window_size: the length of the window to construct.
Returns:
a new list of data points, corresponding to each window in the
sentence. Each data point consists of a list of
@n_window_features features (corresponding to words from the
window) to be used in the sentence and its NER label.
If start=[5,8] and end=[6,8], the above example should return
the list
[([5, 8, 1, 9, 2, 9], 1),
([1, 9, 2, 9, 3, 8], 1),
...
]
"""
windowed_data = []
for sentence, labels in data:
# YOUR CODE HERE (5-20 lines)
T = len(labels) # 序列长度T
for t in range(T): # 遍历单个序列的每个单词
sen2fea = []
for l in range(window_size, 0, -1): # 左窗口的w个单词
if t-l < 0:
sen2fea.extend(start)
else:
sen2fea.extend(sentence[t-l])
sen2fea.extend(sentence[t])
for r in range(1, window_size+1): # 右窗口的w个单词
if t+r >= T:
sen2fea.extend(end)
else:
sen2fea.extend(sentence[t+r])
windowed_data.append((sen2fea, labels[t]))
# END YOUR CODE
return windowed_dataii.在WindowModel类中实现前面描述的前馈模型。
class WindowModel(NERModel):
"""
Implements a feedforward neural network with an embedding layer and
single hidden layer.
This network will predict what label (e.g. PER) should be given to a
given token (e.g. Manning) by using a featurized window around the token.
"""
def add_placeholders(self):
"""Generates placeholder variables to represent the input tensors
These placeholders are used as inputs by the rest of the model building and will be fed
data during training. Note that when "None" is in a placeholder's shape, it's flexible
(so we can use different batch sizes without rebuilding the model).
Adds following nodes to the computational graph
input_placeholder: Input placeholder tensor of shape (None, n_window_features), type tf.int32
labels_placeholder: Labels placeholder tensor of shape (None,), type tf.int32
dropout_placeholder: Dropout value placeholder (scalar), type tf.float32
Add these placeholders to self as the instance variables
self.input_placeholder
self.labels_placeholder
self.dropout_placeholder
(Don't change the variable names)
"""
# YOUR CODE HERE (~3-5 lines)
self.input_placeholder = tf.placeholder(shape=[None, Config.n_window_features], dtype=tf.int32)
self.labels_placeholder = tf.placeholder(shape=[None, ], dtype=tf.int32)
self.dropout_placeholder = tf.placeholder(dtype=tf.float32)
# END YOUR CODE
def create_feed_dict(self, inputs_batch, labels_batch=None, dropout=1):
"""Creates the feed_dict for the model.
A feed_dict takes the form of:
feed_dict = {
: ,
....
}
Hint: The keys for the feed_dict should be a subset of the placeholder
tensors created in add_placeholders.
Hint: When an argument is None, don't add it to the feed_dict.
Args:
inputs_batch: A batch of input data.
labels_batch: A batch of label data.
dropout: The dropout rate.
Returns:
feed_dict: The feed dictionary mapping from placeholders to values.
"""
# YOUR CODE HERE (~5-10 lines)
if labels_batch is None:
feed_dict = {self.input_placeholder: inputs_batch,
self.dropout_placeholder: dropout}
else:
feed_dict = {self.input_placeholder: inputs_batch,
self.labels_placeholder: labels_batch,
self.dropout_placeholder: dropout}
# END YOUR CODE
return feed_dict
def add_embedding(self):
"""Adds an embedding layer that maps from input tokens (integers) to vectors and then
concatenates those vectors:
- Creates an embedding tensor and initializes it with self.pretrained_embeddings.
- Uses the input_placeholder to index into the embeddings tensor, resulting in a
tensor of shape (None, n_window_features, embedding_size).
- Concatenates the embeddings by reshaping the embeddings tensor to shape
(None, n_window_features * embedding_size).
Hint: You might find tf.nn.embedding_lookup useful.
Hint: You can use tf.reshape to concatenate the vectors. See following link to understand
what -1 in a shape means.
https://www.tensorflow.org/api_docs/python/array_ops/shapes_and_shaping#reshape.
Returns:
embeddings: tf.Tensor of shape (None, n_window_features*embed_size)
"""
# YOUR CODE HERE (!3-5 lines)
embedding = tf.Variable(self.pretrained_embeddings, name='embedding')
embeddings_3d = tf.nn.embedding_lookup(embedding, self.input_placeholder)
embeddings = tf.reshape(embeddings_3d, shape=[-1, Config.n_window_features*Config.embed_size])
# END YOUR CODE
return embeddings
def add_prediction_op(self):
"""Adds the 1-hidden-layer NN:
h = Relu(xW + b1)
h_drop = Dropout(h, dropout_rate)
pred = h_dropU + b2
Recall that we are not applying a softmax to pred. The softmax will instead be done in
the add_loss_op function, which improves efficiency because we can use
tf.nn.softmax_cross_entropy_with_logits
When creating a new variable, use the tf.get_variable function
because it lets us specify an initializer.
Use tf.contrib.layers.xavier_initializer to initialize matrices.
This is TensorFlow's implementation of the Xavier initialization
trick we used in last assignment.
Note: tf.nn.dropout takes the keep probability (1 - p_drop) as an argument.
The keep probability should be set to the value of dropout_rate.
Returns:
pred: tf.Tensor of shape (batch_size, n_classes)
"""
x = self.add_embedding()
dropout_rate = self.dropout_placeholder
# YOUR CODE HERE (~10-20 lines)
W = tf.get_variable(initializer=tf.contrib.layers.xavier_initializer(),
shape=[Config.n_window_features*Config.embed_size, Config.hidden_size],
name='W')
b1 = tf.get_variable(initializer=tf.zeros(Config.hidden_size), name='b1')
h = tf.nn.relu(tf.matmul(x, W) + b1)
h_drop = tf.nn.dropout(h, keep_prob=dropout_rate)
U = tf.get_variable(initializer=tf.contrib.layers.xavier_initializer(),
shape=[Config.hidden_size, Config.n_classes],
name='U')
b2 = tf.get_variable(initializer=tf.zeros(Config.n_classes), name='b2')
pred = tf.matmul(h_drop, U) + b2
# END YOUR CODE
return pred
def add_loss_op(self, pred):
"""Adds Ops for the loss function to the computational graph.
In this case we are using cross entropy loss.
The loss should be averaged over all examples in the current minibatch.
Remember that you can use tf.nn.sparse_softmax_cross_entropy_with_logits to simplify your
implementation. You might find tf.reduce_mean useful.
Args:
pred: A tensor of shape (batch_size, n_classes) containing the output of the neural
network before the softmax layer.
Returns:
loss: A 0-d tensor (scalar)
"""
# YOUR CODE HERE (~2-5 lines)
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=pred,
labels=self.labels_placeholder))
# END YOUR CODE
return loss
def add_training_op(self, loss):
"""Sets up the training Ops.
Creates an optimizer and applies the gradients to all trainable variables.
The Op returned by this function is what must be passed to the
`sess.run()` call to cause the model to train. See
https://www.tensorflow.org/versions/r0.7/api_docs/python/train.html#Optimizer
for more information.
Use tf.train.AdamOptimizer for this model.
Calling optimizer.minimize() will return a train_op object.
Args:
loss: Loss tensor, from cross_entropy_loss.
Returns:
train_op: The Op for training.
"""
# YOUR CODE HERE (~1-2 lines)
train_op = tf.train.AdamOptimizer(learning_rate=Config.lr).minimize(loss)
# END YOUR CODE
return train_op
def preprocess_sequence_data(self, examples):
return make_windowed_data(examples, start=self.helper.START, end=self.helper.END, window_size=self.config.window_size)
def consolidate_predictions(self, examples_raw, examples, preds):
"""Batch the predictions into groups of sentence length.
"""
ret = []
#pdb.set_trace()
i = 0
for sentence, labels in examples_raw:
labels_ = preds[i:i+len(sentence)]
i += len(sentence)
ret.append([sentence, labels, labels_])
return ret
def predict_on_batch(self, sess, inputs_batch):
"""Make predictions for the provided batch of data
Args:
sess: tf.Session()
input_batch: np.ndarray of shape (n_samples, n_features)
Returns:
predictions: np.ndarray of shape (n_samples, n_classes)
"""
feed = self.create_feed_dict(inputs_batch)
predictions = sess.run(tf.argmax(self.pred, axis=1), feed_dict=feed)
return predictions
def train_on_batch(self, sess, inputs_batch, labels_batch):
feed = self.create_feed_dict(inputs_batch, labels_batch=labels_batch,
dropout=self.config.dropout)
_, loss = sess.run([self.train_op, self.loss], feed_dict=feed)
return loss
def __init__(self, helper, config, pretrained_embeddings, report=None):
super(WindowModel, self).__init__(helper, config, report)
self.pretrained_embeddings = pretrained_embeddings
# Defining placeholders.
self.input_placeholder = None
self.labels_placeholder = None
self.dropout_placeholder = None
self.build() 
iii.训练模型,模型和输出会被存在results/window/
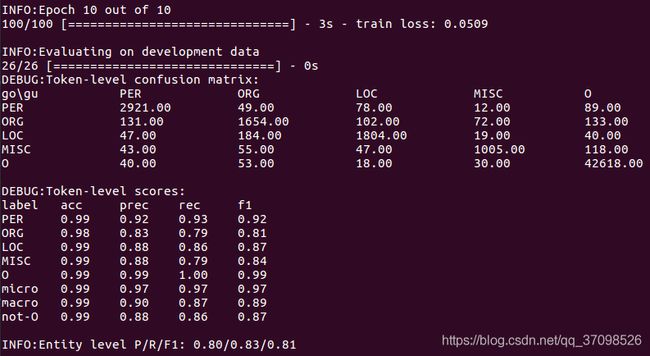
(d)使用上面生成的文件分析模型的预测。
i.简要描述混淆矩阵显示的关于模型预测错误的信息。
混淆矩阵显示模型的最大混淆源来自组织标签,其中许多组织被误认为人名或直接被忽略,另一方面,人名似乎被识别的很好。
ii.描述基于窗口的模型的至少2个建模限制。
基于窗口的模型不能使用来自相邻预测的信息来消除标签决策的歧义,从而导致不连续的实体预测。
关于tf.Variable和tf.get_variable的区别:
https://blog.csdn.net/MrR1ght/article/details/81228087
关于tf.nn.embedding_lookup:
https://blog.csdn.net/yinruiyang94/article/details/77600453
https://tensorflow.google.cn/api_docs/python/tf/nn/embedding_lookup
关于tf.contrib.layers.xavier_initializer:
https://blog.csdn.net/yinruiyang94/article/details/78354257
https://tensorflow.google.cn/api_docs/python/tf/contrib/layers/xavier_initializer