02_混淆矩阵、准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F值(F-Measure) +Roc曲线和PR曲线+sklearn中分类模型评估API+ 自己补充整理
此博文参考:
关于ROC绘制参考博文:
https://blog.csdn.net/u011630575/article/details/80250177
Python+ROC相关的博文:
https://www.jianshu.com/p/2ca96fce7e81
另外就是百度百科、《机器学习原理》
1、混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)
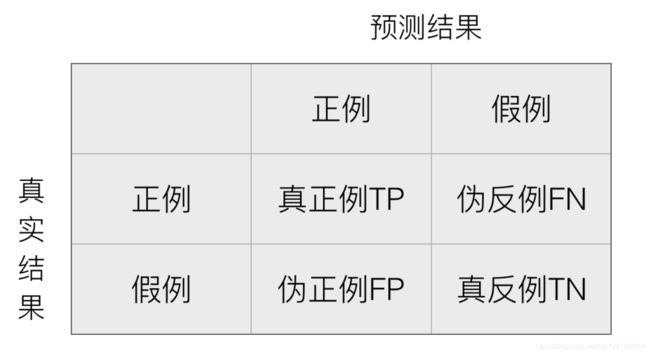
2、准确率、精确率、召回率和F值是选出目标的重要评价指标。不妨先看看这些指标的定义:
(1)若一个实例是正类,但是被预测成为正类,即为真正类(True Postive TP)
(2)若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN)
(3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
(4)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
下表中:1代表正类,0代表负类:

TP:正确的匹配数目
FP:误报,没有的匹配不正确
FN:漏报,没有找到正确匹配的数目
TN:正确的非匹配数目
准确率(正确率)=所有预测正确的样本/总的样本 (TP+TN)/总
精确率= 将正类预测为正类 / 所有预测为正类 TP/(TP+FP)
召回率 = 将正类预测为正类 / 所有正真的正类 TP/(TP+FN)
F值 = 精确率 * 召回率 * 2 / ( 精确率 + 召回率) (F 值即为精确率和召回率的调和平均值)
在某些文章中还会出现"特异性"的概念。特异性的公式是:
S = FP/(FP + TN)
F1值用来综合评估精确率和召回率,它是精确率和召回率的调和均值。当精确率和召回率都高时,F1值也会高。
有时候我们精确率和召回率并不是一视同仁,比如我们更加重视精确率。我们用一个参数
1、精确率:预测结果为正例样本中真实为正例的比例(查得准)

2、召回率:真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力)

其它分类标准,F1,反映了模型的稳健性

3、Roc曲线和PR曲线
接受者操作特性曲线(receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve)。它是指在特定刺激条件下,以被试在不同判断标准下所得的虚报概率P(y/N)为横坐标,以击中概率P(y/SN)为纵坐标,画得的各点的连线。
ROC得名的原因在于曲线上各点反应着相同的感受性,它们都是对同一信号刺激的反应,只不过是在击中不同的判定标准下所得的结果而已。接受者操作曲线就是以虚惊概率为横轴,击中概率为纵轴所组成的坐标图,和被试在特定刺激条件下由于采用不同的判断标准得出的不同结果画出的曲线。
如下图:

再如:
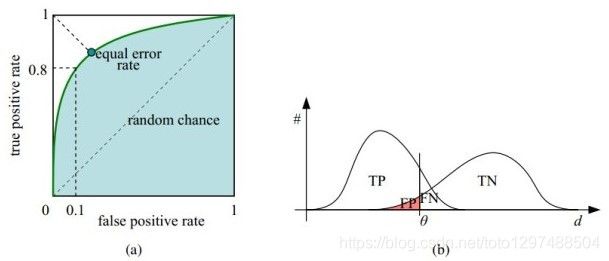
该曲线:
纵轴: 真正类率(true postive rate TPR),也叫真阳性率,计算公式:TP/(TP + FN),代表分类器 预测为正类中实际为正实例占 所有正实例 的比例。
横轴: 假正类率(false postive rate FPR),也叫伪阳性率,计算公式:FP/(FP + TN),代表分类器 预测为正类中实际为负实例 占 所有负实例 的比例。
横轴FPR: FPR越大,预测正类中实际负类越多。
纵轴TPR: TPR越大,预测正类中实际正类越多。
理想目标:TPR=1,FPR=0,即图中(0,1)点,此时ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。
如上图所示,(a)图中实线为ROC曲线,(深绿色)线上每个点对应一个阈值(threshold)。假设是二分类分类器,输出为每个实例预测为正类的概率。那么通过设定一个特定阈值(threshold),预测为正类的概率值 大于等于 特定阈值的为 正类,小于 特定阈值的为 负类,然后统计TP、TN、FP、FN每个类别的数目,然后根据上面的公式,就能对应的就可以算出一组 特定阈值下(FPR,TPR)的值,即 在平面中得到对应坐标点。如果这里没懂也没关系,下面有详细的例子说明。
右上角的阈值最小,对应坐标点(1,1);左下角阈值最大,对应坐标点为(0,0)。从右上角到左下角,随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。
4、分类模型评估API
在深度学习中,分类任务评价指标是很重要的,一个好的评价指标对于训练一个好的模型极其关键;如果评价指标不对,对于任务而言是没有意义的。
一般都是用准确率来作为评价指标,然而对于类别不均衡的任务来说,或者在任务中某一个类的准确率非常重要。如果再使用单纯的准确率肯定是不合理的,对任务来说 没有意义。所以我们需要一个好的评价指标来。目前一般都是用精确率,召回率,F1分数来评价模型;
在sklearn中有自动生成这些指标的的工具,就是 sklearn.metrics.classification_report模块
sklearn.metrics.classification_report(y_true, y_pred, labels=None, target_names=None, sample_weight=None, digits=2, output_dict=False)
y_true:类别的真实标签值,类标签的列表
y_pred:预测值的标签,类标签的列表
labels:labels: 报告中要包含的标签索引的可选列表;这个参数一般不需要设置(如果要设置,比如200个类别,那么就应该如此设置:lable= range(200); 然后在sklearn.metrics.classification_report中将labels=label),可是有的时候不设置就会出错,之所以会出错是因为:比如你总共的类别为200个类,但是,你的测试集中真实标签包含的类别只有199个,有一个类别缺失数据,如果不设置这个参数就会报错;
target_names:与标签匹配的名称,就是一个字符串列表,在报告中显示;也即是显示与labels对应的名称
sample_weight:设置权重的参数,一般不用,需要就可以用
digits:这个参数是用来设置你要输出的格式位数,就是几位有效数字吧,大概就是这个意思,即是输出格式的精确度;
output_dict:一般不用,好像没啥用;如果为True,则将输出作为dict返回。
return:每个类别精确率与召回率
5.classification_report 的指标分析
案例:
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0 ,2, 2, 1]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true,y_pred,target_names=target_names))
输出结果为:
precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
accuracy 0.60 5
macro avg 0.50 0.56 0.49 5
weighted avg 0.70 0.60 0.61 5
在这个报告中:
- y_true 为样本真实标签,y_pred 为样本预测标签;
- support:当前行的类别在测试数据中的样本总量,如上表就是,在class 0 类别在测试集中总数量为1;
- precision:精度=正确预测的个数(TP)/被预测正确的个数(TP+FP);人话也就是模型预测的结果中有多少是预测正确的
- recall:召回率=正确预测的个数(TP)/预测个数(TP+FN);人话也就是某个类别测试集中的总量,有多少样本预测正确了;
- f1-score:F1 = 2精度召回率/(精度+召回率)
- micro avg:计算所有数据下的指标值,假设全部数据 5 个样本中有 3 个预测正确,所以 micro avg 为 3/5=0.6
- macro avg:每个类别评估指标未加权的平均值,比如准确率的 macro avg,(0.50+0.00+1.00)/3=0.5
- weighted avg:加权平均,就是测试集中样本量大的,我认为它更重要,给他设置的权重大点;比如第一个值的计算方法,(0.501 + 0.01 + 1.0*3)/5 = 0.70
打个赏呗,您的支持是我坚持写好博文的动力。
