【深度学习】---行人检测应用
行人检测综述
涉及论文
主要围绕王晓刚的几篇关于深度学习在行人检测的应用。
Ouyang, W. and X. Wang (2013). “Joint Deep Learning for Pedestrian Detection.” 2056-2063.*
Ouyang, W. and X. Wang (2012). A discriminative deep model for pedestrian detection with occlusion handling. Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, IEEE.Ouyang, W. and X. Wang (2013). Single-pedestrian detection aided by multi-pedestrian detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
Walk, S., et al. (2010).New features and insights for pedestrian detection. Computer vision and pattern recognition (CVPR), 2010 IEEE conference on, IEEE.
Zeng, X., et al. (2013). “Multi-stage Contextual Deep Learning for Pedestrian Detection.” 121-128.
主要思路
利用深度学习的方法解决行人检测的Feature extraction, deformation handling, occlusion handling, and classification四个问题进行联合学习的思想,尤其处理occlusion handling遮挡的问题花费的篇幅比较多。
本次笔记主要围绕Joint Deep Learning for Pedestrian Detection这篇文章来进行讨论,其他几篇文章属于其前驱文章,有借鉴内容会详细说。
论文讨论
论文原文
http://www.cv-foundation.org/openaccess/content_iccv_2013/html/Ouyang_Joint_Deep_Learning_2013_ICCV_paper.html
摘要
特征提取、形变处理、遮挡处理、分类是四个行人检测中的重要部分。目前的方法一般都是把这四个部分孤立起来处理,本文的思路是将这四部分联合来学习,来发挥他们之间协同的最大作用。本文将这四部分在一个深度模型中进行学习,并且在几个数据集上进行测试得到的结果在漏检上提高了9%的概率。
Contributions
1.将四个主要部分联合学习,利用这个深度模型,这几个部分协同作用使得每部分发挥更大作用。
2.我们通过在cnn加入形变层层(deformation layer)来丰富了深度模型,使得许多形变处理可以依赖于我们的深度模型。
3.特征是通过形变处理和遮挡处理两个部分协同下的像素得到,由此可以得到更多不同的特征。
核心内容
深度模型概要
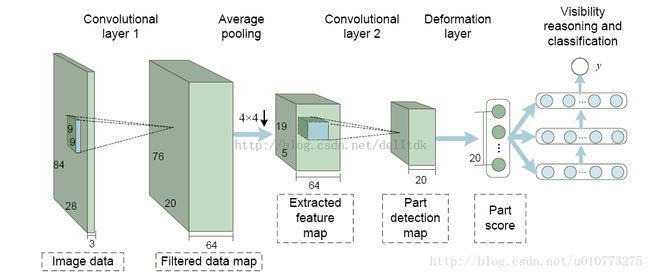
图 1 网络结构图
主要用CNN+Part Detection+Deformation Model+Visibility reasoning构建神经网络,但是前端需要预检测,本文作者采用的之前的一篇文章的方法进行预处理,得出candidate window(HOG+CSS+SVM基本方法),然后后面用的本网络进行检测,主要结构如图 1。
(注:CSS特征出自
https://wenku.baidu.com/view/612db676302b3169a45177232f60ddccdb38e674)
大致流程如下:
1.以修改过的YUV特征和map作为输出
2.一个卷积层(应该是看成root)
3.又一个卷积层(引入不同大小的卷积核,带有part信息)
4.处理deformable的一个层
5.处理occlusion的层,并得到最后结果
输入层虽然是3channel,但却不是直接的RGB或者YUV等等三通道图,而是经过预处理阶段之后的。第一个map是原图的Y通道,第二个map被均分为四个block,分别是 U通道,V通道,Y通道和全0,见下图2a;第三个map是sobel算子计算的第二个map的边缘,不同的是第四个block是前面三个block的边缘的最大值,如图 2。(注意,最终每个map都要归一到零均值-单位方差的分布)。

图 2输入层的第二、第三层map
构建部分检测map(part detection map)
本文建立了三个等级的部分map,具体如图 3,每个等级由身体的部分大小分类,高等级部分又低等级部分组成。用这20个大小不同的part卷积核与detection map进行处理,然后得到20个part的带检测map。
从这里面得到的model要比HOG特征得到的结果更细致。
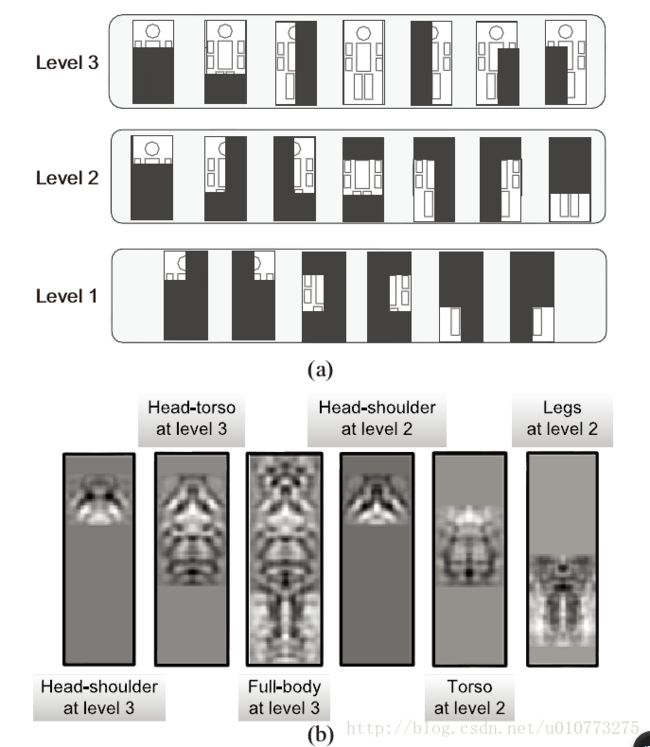
图 3(a)部分模型(b)第二层卷基层学习的部分模型
形变层(deformation layer)
为了得到不同部分的约束,我们为cnn添加了形变处理层。感觉上这部分是这个论文对行人检测的关键贡献吧。
输入为P部分detection map,输出为P部分的得分s = {s1, … , sP },由图 1得到P为20个。
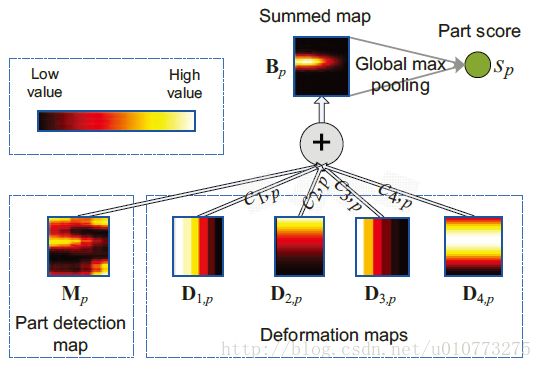
图 4得分系统和最终得分,其中B_p是得到的和结果,
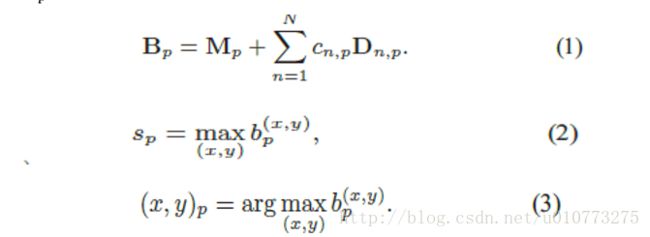
(1)式中的c_(n,p) D_(n,p)是建立模型的关键,是需要学习的参数。然后进行融合得到一张deformation part的map(summed map),之后求全图得到max就为part的得分。
文中举了三种特殊情况的例子,主要是围绕着代价来讨论的,然后用到了
其他两篇文章的处理办法,貌似是区域形变和二次约束之类的方法,那两篇文章大概翻了一下没有看懂,这部分就没有细看。
可见性根据和分类器
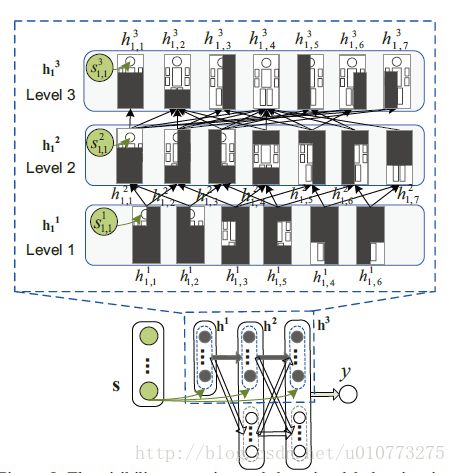
图 5 DBN网络层
DBN的网络是之前文章DBN网络的升级版。
http://ieeexplore.ieee.org/abstract/document/6248062/?reload=true
http://www.cv-foundation.org/openaccess/content_iccv_2013/html/Zeng_Multi-stage_Contextual_Deep_2013_ICCV_paper.html
每个部分可以有不止一个父节点,和子节点。基于本网络,一个节点的可视性可以看做是与同层其他节点存在相关性的(通过他们之间的父节点)。
很多的文章的方法也是进行每部分的评分然后进行得到最终的结论,但是每个部分之间的相关性没有被开发,本文就是利用深度模型学习出每部分模型的相关性的。
DBN与RBM的简单介绍:
http://crad.ict.ac.cn/CN/article/downloadArticleFile.do?attachType=PDF&id=2724
上述神经网络的传导模型公式如下:
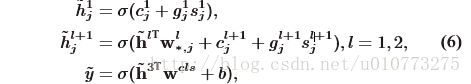
其中 σ是sigmoid函数,g是s的权重,c是偏置项。W塑造了h在l与l+1层之间的联系。g,h,w,b是需要学习的参数。
本文对上述引用论文的网络改进主要有下面两个方面:
1.在第1层和第2层的信息需要通过第3层传给分类器,但是第3层的不好的样本不会影响到之前层的信息,于是在第2层和第3层中间加了一些隐藏节点,来帮助第1,第2层来直接传导信息到分类器,而不会被其他的部分影响。隐藏节点不采用之前的detection的分数,并且在g_j^(l+1) s_j^(l+1)=0,在图 5中是用白圈代表,而g_j^(l+1) s_j^(l+1)≠0的用灰圈表示。
2.(*)原来的网络只是通过部分的分数来学习了可视之间的联系(visiblity relationship),HOG特征和形变处理的参量都是固定的。本文中形变模型,可视联系都是通过联合学习的,为了学习两个卷基层的参数和形变层的参数,利用反向传导来求得预测误差。
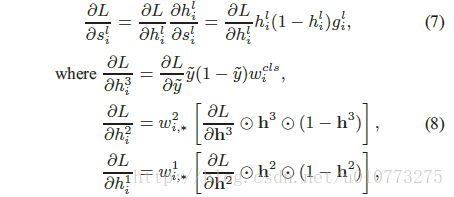
其中 为hadamard积, 具体就不是太懂了。L是损失函数。
为了训练这个深度模型,我们提出了一种多级训练策略,开始时采用监督学习训练一层cnn,因为Gabor滤波器和人类视觉系统比较相似,用来初始化最初的cnn,我们在每一级添加一层,前一级得到的结果来初始化下一层。层层学习得到最终结果,然后BP算法调整。
总结
本文主要着眼于将行人检测中的重要的四部分工作进行联合学习。把他们联系在一起可以获得之间比较好的相关性,然后得到更准确的检测。
但是论文的预处理还是要进行candidate window的获得,也就是说之前的核心检测还是没有发生本质的变化,而是在原来现有的算法的基础上进行了一个增加的深度学习的方法来进行确认,从而提高检测的成功率。