0. Cause I just wanna wake up in the fleeting light
0.1 アイスクリームみた溶けそう、その瞳にみつめられたなら
新论文方向想好了,一个改进的TextCNN应用实例吧。数据集来源于学长之前打比赛时官方发的2G数据包,大概达到的效果就是通过用户短评去给某个景点的旅行指标进行打分。当然会有一个疑问,在我们现实的应用场景中不都是用户进行打分吗。但这里我要做的是对短评的深层语义进行挖掘,然后得出打分(无奈,为了写论文而写),其实确实没有什么意义,但是自然语言处理就是这样。
为了给论文做一点铺垫,今天更新一个基于TextCNN的情感二分类问题。这个实验做了很久,4月3号完成的。当时边做边写,用了很多时间给虚拟机的使用写了一个README文档。
简单描述一下这个问题。电影影评一般属于短评,那么我们要做的就是将任一条用户影评分类至 [positive,negative] 两个标签,也就俗称为情感二分类问题。数据集源自于Movie Review Data这个开源站点http://www.cs.cornell.edu/people/pabo/movie-review-data/ ,里面有不同大小的datasets,均按照positive和negative两个标签分好类,可以根据电脑内存配置和实验需求进行选择。
现在每个方向都是基于深度学习的XXXX。自然语言处理也不例外,每天学习的还是CNN和RNN。3月份跟老师吵架的时候,因为那时候弄了一个基于LSTM的自动音乐序列生成,也就是训练集不是文本,他因为这个事情跟我生了半个月的气。TextCNN简单来说,就是比卷积神经网络CNN多了一个Embedding层,这个Embedding层的作用就是为了把文字转化为向量和矩阵,完毕。
0.2 会いたいなんて思っても、恥ずかしいからなかなか言えない
今天的标题会不会太长了,这一节结合Tensorboard简单说一下TextCNN的网络结构吧。前提是稍微熟悉一点CNN,如果忘记了可以参考我之前写一篇的CNN的学习记录博文,可以说非常的入门级和清晰了。代码将会在第二部给出,运行结果在第三部分给出。

图1 tensorboard中展示的TextCNN结构
可以看到,TextCNN在第一层加入了Embedding层,将输入的文本向量转化为数字向量。在输入Embedding之前,我们需要写一个data_helper的函数,去做文本的切词、去停用词、去标点符号、补齐等操作。把每一条短评处理为相同长度的文本向量(比如每一条都是100个词)后,输入Embedding层。Embedding层调用google开发的Word2vec方法将文本向量映射至数字向量。也就是说,经过Embedding层后每一条短评(100个词为例,每个词为100维)变成 [(x1_1,x1_2,...x1_100)....(x100_1,....x100_100)] 这样一组向量或者成为矩阵进行后续的计算。这里需要补充一点,Embedding层也可以只是简单做一个映射,使用一个已经训练好的词表(该词表每一行代表一个词,第一列为词本身,第二列为100维或200维甚至更高的数字向量表达形式),Embedding层只需要做一个查表和映射就可以了。
经过Embedding层后的操作和CNN基本没区别,也是遵循Conv+Pool最后在全连接层进行Softmax操作,但在每一步的细节上有区别,这需要去代码里面好好看看,卷积采样窗口和池化方法等等都有不同。针对NLP的CNN常用Pool方法可以参考我之前写的一篇CNN中常见的几种pool操作。
这一小节最后再借用Yoon Kim论文中的一张图进行解释吧,论文参考 Convolutional Neural Networks for Sentence Classification 。wait这个词经过Embedding层后变为下图第一步中的向量形式,然后通过卷积Conv层变成第二步中的方格。然后下图中使用的pool方法为maxpool,因为第二步中多个方格只有一个输出到全连接层中。最后一步,全连接层通过softmax输出一个二分类概率。具体原理可以参考我写的CNN学习记录。
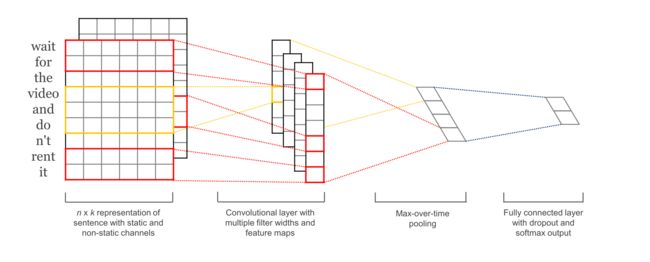
图2 TextCNN的情感二分类图示
1. Before these lights they all went dark
这一部分还是继续上干货,贴代码,总共有4个py文件。简单解释一下作用。
data_helpers.py:文本文件导入,切词、去停用词、去标点符号,文本向量填充等等。
eval.py:负责参数和结果的部分输出。
text_cnn.py:网络定义。
train.py:训练部分。
使用时直接运行train.py就可以了。想查看更多的中间过程(比如每条短评经过Embedding层后是什么样子的),参考 https://blog.csdn.net/github_38414650/article/details/74019595 。下面我按上述顺序贴代码。
|
# data_helpers.py import numpy as np import re import itertools from collections import Counter import builtins def clean_str(string): string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string) string = re.sub(r"\'s", " \'s", string) string = re.sub(r"\'ve", " \'ve", string) string = re.sub(r"n\'t", " n\'t", string) string = re.sub(r"\'re", " \'re", string) string = re.sub(r"\'d", " \'d", string) string = re.sub(r"\'ll", " \'ll", string) string = re.sub(r",", " , ", string) string = re.sub(r"!", " ! ", string) string = re.sub(r"\(", " \( ", string) string = re.sub(r"\)", " \) ", string) string = re.sub(r"\?", " \? ", string) string = re.sub(r"\s{2,}", " ", string) return string.strip().lower() def load_data_and_labels(positive_data_file,negative_data_file): positive_examples = list(builtins.open(positive_data_file,"r").readlines()) positive_examples = [s.strip() for s in positive_examples] negative_examples = list(builtins.open(negative_data_file, "r").readlines()) negative_examples = [s.strip() for s in negative_examples] x_text = positive_examples + negative_examples x_text = [clean_str(sent) for sent in x_text] positive_labels = [[0,1] for _ in positive_examples] negative_labels = [[1,0] for _ in negative_examples] y = np.concatenate([positive_labels, negative_labels],0) return [x_text,y] def batch_iter(data,batch_size,num_epochs,shuffle=True): data = np.array(data) data_size = len(data) num_batches_per_epoch = int((len(data)-1)/batch_size) + 1 for epoch in range(num_epochs): if shuffle: shuffle_indices = np.random.permutation(np.arange(data_size)) shuffle_data = data[shuffle_indices] else: shuffle_data = data for batch_num in range(num_batches_per_epoch): start_index = batch_num * batch_size end_index = min((batch_num + 1) * batch_size,data_size) yield shuffle_data[start_index:end_index] |
|
#! /usr/bin/env python # eval.py import tensorflow as tf import numpy as np import os import time import datetime import data_helpers from text_cnn import TextCNN from tensorflow.contrib import learn import csv # Parameters # ================================================== # Data Parameters tf.flags.DEFINE_string("positive_data_file", "./data/pos.txt", "Data source for the positive data.") tf.flags.DEFINE_string("negative_data_file", "./data/neg.txt", "Data source for the negative data.") # Eval Parameters tf.flags.DEFINE_integer("batch_size", 64, "Batch Size (default: 64)") tf.flags.DEFINE_string("checkpoint_dir", "", "Checkpoint directory from training run") tf.flags.DEFINE_boolean("eval_train", False, "Evaluate on all training data") # Misc Parameters tf.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement") tf.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices") FLAGS = tf.app.flags.FLAGS #FLAGS._parse_flags() print("\nParameters:") for attr, value in sorted(FLAGS.__flags.items()): print("{}={}".format(attr.upper(), value)) print("") # CHANGE THIS: Load data. Load your own data here if FLAGS.eval_train: x_raw, y_test = data_helpers.load_data_and_labels(FLAGS.positive_data_file, FLAGS.negative_data_file) y_test = np.argmax(y_test, axis=1) else: x_raw = ["a masterpiece four years in the making", "everything is off."] y_test = [1, 0] # Map data into vocabulary vocab_path = os.path.join(FLAGS.checkpoint_dir, "..", "vocab") vocab_processor = learn.preprocessing.VocabularyProcessor.restore(vocab_path) x_test = np.array(list(vocab_processor.transform(x_raw))) print("\nEvaluating...\n") # Evaluation # ================================================== checkpoint_file = tf.train.latest_checkpoint(FLAGS.checkpoint_dir) graph = tf.Graph() with graph.as_default(): session_conf = tf.ConfigProto( allow_soft_placement=FLAGS.allow_soft_placement, log_device_placement=FLAGS.log_device_placement) sess = tf.Session(config=session_conf) with sess.as_default(): # Load the saved meta graph and restore variables saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file)) saver.restore(sess, checkpoint_file) # Get the placeholders from the graph by name input_x = graph.get_operation_by_name("input_x").outputs[0] # input_y = graph.get_operation_by_name("input_y").outputs[0] dropout_keep_prob = graph.get_operation_by_name("dropout_keep_prob").outputs[0] # Tensors we want to evaluate predictions = graph.get_operation_by_name("output/predictions").outputs[0] # Generate batches for one epoch batches = data_helpers.batch_iter(list(x_test), FLAGS.batch_size, 1, shuffle=False) # Collect the predictions here all_predictions = [] for x_test_batch in batches: batch_predictions = sess.run(predictions, {input_x: x_test_batch, dropout_keep_prob: 1.0}) all_predictions = np.concatenate([all_predictions, batch_predictions]) # Print accuracy if y_test is defined if y_test is not None: correct_predictions = float(sum(all_predictions == y_test)) print("Total number of test examples: {}".format(len(y_test))) print("Accuracy: {:g}".format(correct_predictions/float(len(y_test)))) # Save the evaluation to a csv predictions_human_readable = np.column_stack((np.array(x_raw), all_predictions)) out_path = os.path.join(FLAGS.checkpoint_dir, "..", "prediction.csv") print("Saving evaluation to {0}".format(out_path)) with open(out_path, 'w') as f: csv.writer(f).writerows(predictions_human_readable) |
|
# text_cnn.py import tensorflow as tf import numpy as np class TextCNN(object): """ A CNN for text classification. Uses an embedding layer, followed by a convolutional, max-pooling and softmax layer. """ def __init__( self, sequence_length, num_classes, vocab_size, embedding_size, filter_sizes, num_filters, l2_reg_lambda=0.0): # Placeholders for input, output and dropout self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x") self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y") self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob") # Keeping track of l2 regularization loss (optional) l2_loss = tf.constant(0.0) # Embedding layer with tf.device('/cpu:0'), tf.name_scope("embedding"): self.W = tf.Variable( tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0), name="W") self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x) self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1) # Create a convolution + maxpool layer for each filter size pooled_outputs = [] for i, filter_size in enumerate(filter_sizes): with tf.name_scope("conv-maxpool-%s" % filter_size): # Convolution Layeri filter_shape = [filter_size, embedding_size, 1, num_filters] W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W") b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b") conv = tf.nn.conv2d( self.embedded_chars_expanded, W, strides=[1, 1, 1, 1], padding="VALID", name="conv") # Apply nonlinearity h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu") # Maxpooling over the outputs pooled = tf.nn.max_pool( h, ksize=[1, sequence_length - filter_size + 1, 1, 1], strides=[1, 1, 1, 1], padding='VALID', name="pool") pooled_outputs.append(pooled) # Combine all the pooled features num_filters_total = num_filters * len(filter_sizes) self.h_pool = tf.concat(pooled_outputs, 3) self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total]) # Add dropout with tf.name_scope("dropout"): self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob) # Final (unnormalized) scores and predictions with tf.name_scope("output"): W = tf.get_variable( "W", shape=[num_filters_total, num_classes], initializer=tf.contrib.layers.xavier_initializer()) b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b") l2_loss += tf.nn.l2_loss(W) l2_loss += tf.nn.l2_loss(b) self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores") self.predictions = tf.argmax(self.scores, 1, name="predictions") # Calculate mean cross-entropy loss with tf.name_scope("loss"): losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y) self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss # Accuracy with tf.name_scope("accuracy"): correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1)) self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy") |
|
# train.py import tensorflow as tf import numpy as np import os import time import datetime import data_helpers from text_cnn import TextCNN from tensorflow.contrib import learn # Parameters # ================================================== # Data loading params tf.flags.DEFINE_float("dev_sample_percentage", .1, "Percentage of the training data to use for validation") tf.flags.DEFINE_string("positive_data_file", "./data/pos.txt", "Data source for the positive data.") tf.flags.DEFINE_string("negative_data_file", "./data/neg.txt", "Data source for the negative data.") # Model Hyperparameters tf.flags.DEFINE_integer("embedding_dim", 128, "Dimensionality of character embedding (default: 128)") tf.flags.DEFINE_string("filter_sizes", "3,4,5", "Comma-separated filter sizes (default: '3,4,5')") tf.flags.DEFINE_integer("num_filters", 128, "Number of filters per filter size (default: 128)") tf.flags.DEFINE_float("dropout_keep_prob", 0.5, "Dropout keep probability (default: 0.5)") tf.flags.DEFINE_float("l2_reg_lambda", 0.0, "L2 regularization lambda (default: 0.0)") # Training parameters tf.flags.DEFINE_integer("batch_size", 64, "Batch Size (default: 64)") tf.flags.DEFINE_integer("num_epochs",20, "Number of training epochs (default: 200)") tf.flags.DEFINE_integer("evaluate_every", 100, "Evaluate model on dev set after this many steps (default: 100)") tf.flags.DEFINE_integer("checkpoint_every", 100, "Save model after this many steps (default: 100)") tf.flags.DEFINE_integer("num_checkpoints", 5, "Number of checkpoints to store (default: 5)") # Misc Parameters tf.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement") tf.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices") FLAGS = tf.app.flags.FLAGS #FLAGS._parse_flags() print("\nParameters:") for attr, value in sorted(FLAGS.__flags.items()): print("{}={}".format(attr.upper(), value)) print("") # Data Preparation # ================================================== # Load data print("Loading data...") x_text, y = data_helpers.load_data_and_labels(FLAGS.positive_data_file, FLAGS.negative_data_file) # Build vocabulary max_document_length = max([len(x.split(" ")) for x in x_text]) vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length) x = np.array(list(vocab_processor.fit_transform(x_text))) # Randomly shuffle data np.random.seed(10) shuffle_indices = np.random.permutation(np.arange(len(y))) x_shuffled = x[shuffle_indices] y_shuffled = y[shuffle_indices] # Split train/test set # TODO: This is very crude, should use cross-validation dev_sample_index = -1 * int(FLAGS.dev_sample_percentage * float(len(y))) x_train, x_dev = x_shuffled[:dev_sample_index], x_shuffled[dev_sample_index:] y_train, y_dev = y_shuffled[:dev_sample_index], y_shuffled[dev_sample_index:] del x, y, x_shuffled, y_shuffled print("Vocabulary Size: {:d}".format(len(vocab_processor.vocabulary_))) print("Train/Dev split: {:d}/{:d}".format(len(y_train), len(y_dev))) # Training # ================================================== with tf.Graph().as_default(): session_conf = tf.ConfigProto( allow_soft_placement=FLAGS.allow_soft_placement, log_device_placement=FLAGS.log_device_placement) sess = tf.Session(config=session_conf) with sess.as_default(): cnn = TextCNN( sequence_length=x_train.shape[1], num_classes=y_train.shape[1], vocab_size=len(vocab_processor.vocabulary_), embedding_size=FLAGS.embedding_dim, filter_sizes=list(map(int, FLAGS.filter_sizes.split(","))), num_filters=FLAGS.num_filters, l2_reg_lambda=FLAGS.l2_reg_lambda) # Define Training procedure global_step = tf.Variable(0, name="global_step", trainable=False) optimizer = tf.train.AdamOptimizer(1e-3) grads_and_vars = optimizer.compute_gradients(cnn.loss) train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step) # Keep track of gradient values and sparsity (optional) grad_summaries = [] for g, v in grads_and_vars: if g is not None: grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g) sparsity_summary = tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g)) grad_summaries.append(grad_hist_summary) grad_summaries.append(sparsity_summary) grad_summaries_merged = tf.summary.merge(grad_summaries) # Output directory for models and summaries timestamp = str(int(time.time())) out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp)) print("Writing to {}\n".format(out_dir)) # Summaries for loss and accuracy loss_summary = tf.summary.scalar("loss", cnn.loss) acc_summary = tf.summary.scalar("accuracy", cnn.accuracy) # Train Summaries train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged]) train_summary_dir = os.path.join(out_dir, "summaries", "train") train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph) # Dev summaries dev_summary_op = tf.summary.merge([loss_summary, acc_summary]) dev_summary_dir = os.path.join(out_dir, "summaries", "dev") dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph) # Checkpoint directory. Tensorflow assumes this directory already exists so we need to create it checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints")) checkpoint_prefix = os.path.join(checkpoint_dir, "model") if not os.path.exists(checkpoint_dir): os.makedirs(checkpoint_dir) saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.num_checkpoints) # Write vocabulary vocab_processor.save(os.path.join(out_dir, "vocab")) # Initialize all variables sess.run(tf.global_variables_initializer()) def train_step(x_batch, y_batch): """ A single training step """ feed_dict = { cnn.input_x: x_batch, cnn.input_y: y_batch, cnn.dropout_keep_prob: FLAGS.dropout_keep_prob } _, step, summaries, loss, accuracy = sess.run( [train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy], feed_dict) time_str = datetime.datetime.now().isoformat() print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy)) train_summary_writer.add_summary(summaries, step) def dev_step(x_batch, y_batch, writer=None): """ Evaluates model on a dev set """ feed_dict = { cnn.input_x: x_batch, cnn.input_y: y_batch, cnn.dropout_keep_prob: 1.0 } step, summaries, loss, accuracy = sess.run( [global_step, dev_summary_op, cnn.loss, cnn.accuracy], feed_dict) time_str = datetime.datetime.now().isoformat() print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy)) if writer: writer.add_summary(summaries, step) # Generate batches batches = data_helpers.batch_iter( list(zip(x_train, y_train)), FLAGS.batch_size, FLAGS.num_epochs) # Training loop. For each batch... for batch in batches: x_batch, y_batch = zip(*batch) train_step(x_batch, y_batch) current_step = tf.train.global_step(sess, global_step) #sess.run(train_step,feed_dict={xs:x_data,}) if current_step % FLAGS.evaluate_every == 0: print("\nEvaluation:") dev_step(x_dev, y_dev, writer=dev_summary_writer) print("") if current_step % FLAGS.checkpoint_every == 0: path = saver.save(sess, checkpoint_prefix, global_step=current_step) print("Saved model checkpoint to {}\n".format(path)) |
2. I would fade away with you
首先是控制台的输出情况,训练轮数与每轮迭代次数可以在eval.py中进行修改。

图3 控制台的输出
因为写了save model的东西,所以可以在tensorboard中查看更多训练的详细情况。tensorboard的使用方法查看我之前写的一篇博客有关TensorBoard一些小Tip和实例。可以看到train的准确率基本达到1,在该训练集上TextCNN能够准确进行短评的情感归类了。不信你试试,I hate this movie。如何调用存储好的训练model移步CSDN进行查询。今天就写到这里了。周末愉快。
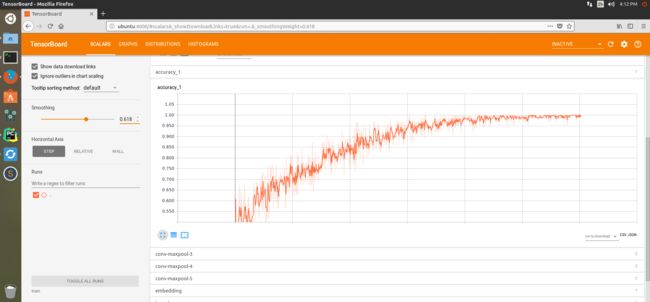
图4 训练的准确率函数
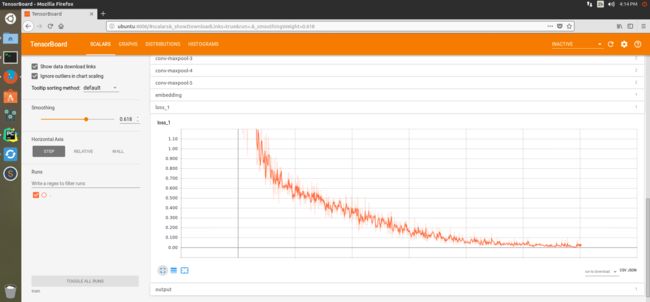
图5 损失函数