轻松搞定实时分析及监控大屏
通过最佳实践帮助您实现上述案例效果
Step1:数据准备
数据格式如下:
$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent"$http_referer" "$http_user_agent" [unknown_content];主要字段说明如下:
| 字段名称 | 字段说明 |
| $remote_addr | 发送请求的客户端IP地址 |
| $remote_user | 客户端登录名 |
| $time_local | 服务器本地时间 |
| $request | 请求,包括HTTP请求类型+请求URL+HTTP协议版本号 |
| $status | 服务端返回状态码 |
| $body_bytes_sent | 返回给客户端的字节数(不含header) |
| $http_referer | 该请求的来源URL |
| $http_user_agent | 发送请求的客户端信息,如使用的浏览器等 |
真实源数据如下:
18.111.79.172 - - [12/Feb/2014:03:15:52 +0800] "GET /articles/4914.html HTTP/1.1" 200 37666
"http://coolshell.cn/articles/6043.html" "Mozilla/5.0 (Windows NT 6.2; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36"Step2:实时数据采集与解析
2.1 数据采集概述
首先需要将该网站产生的日志实时采集上来才有下一步的加工分析可能。本文采用常见的开源工具:Logstash,Logstash是一种分布式日志收集框架,非常简洁强大适合用来做日志数据分析。最终目的是将log数据采集至DataHub。
2.2 Logstash安装与配置
配置前须知:
阿里云流计算为了方便用户将更多数据采集进入DataHub,提供了针对Logstash的DataHub Output插件。
Logstash安装要求JRE 7版本及以上,否则部分工具无法使用。
操作步骤:
步骤1: 点击下载Logstash 2.4.1,点击下载
步骤2: 通过如下命令解压即可使用:
$ tar -xzvf logstash-2.4.1.tar.gz
$ cd logstash-2.4.1 步骤3: 下载 DataHub Logstash Output 插件并使用如下命令进行安装:
${LOG_STASH_HOME}
/bin/plugin install --local logstash-output-datahub-1.0.0.gem步骤4: 配置Logstash任务.conf,示例如下:
input {
file {
path => "/Users/yangyi/logstash-2.4.1/sample/coolshell_log.log"
start_position => "beginning"
}
}
filter{
grok {
match => {
"message" => "(?[^ ]*) - (?[- ]*) \[(?[^\])*]\] \"(?\S+)(?: +(?[^\"]*?)(?: +\S*)?)?(?: +(?[^\"]*))\" (?[^ ]*) (?[^ ]*) \"(?[^\"]*)\" \"(?[^\"]*)\""
}
}
geoip {
source => "ip"
fields => ["city_name","latitude", "longitude"]
target => "geoip"
database => "/Users/yangyi/logstash-2.4.1/bin/GeoLiteCity.dat"
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
}
mutate {
add_field=>{"region" => "%{[geoip][city_name]}"}
add_field=>{"coordinates" => "%{[geoip][coordinates]}"}
add_field=>{"x" => "%{[geoip][longitude]}"}
add_field=>{"y" => "%{[geoip][latitude]}"}
convert => [ "x", "float" ]
convert => [ "y", "float" ]
#convert => [ "coordinates", "float" ]
}
ruby{
code => "
md = event.get('accesstime')
event.set('dt',DateTime.strptime(md,'%d/%b/%Y:%H:%M:%S').strftime('%Y%m%d'))
"
}
}
output {
datahub {
access_id => "输入您的access_id"
access_key => "输入您的access_key"
endpoint => "需要根据自己的网络情况输入对应的endpoint"
project_name => "输入您的DataHub Project名称"
topic_name => "输入您对应的DataHub Topic"
#shard_id => "0"
#shard_keys => ["thread_id"]
dirty_data_continue => true
dirty_data_file => "/Users/yangyi/logstash-2.4.1/sample/dirty.data"
dirty_data_file_max_size => 1000
}
}
配置文件为coolshell_log.conf。具体DataHub Topic信息可详见 数据存储 章节。如果是在阿里云生产网上请填写为:http://dh-cn-hangzhou-internal.aliyuncs.com
如果是在本地进行请填写为:http://dh-cn-hangzhou.aliyuncs.com
步骤5: 启动任务示例如下:
bin/logstash -f sample/coolshell_log.conf步骤6: 任务启动成功,如下示意图:

【备注】启动Logstash任务可以在DataHub Topic目标源创建之后。
2.3 小结
阿里云流计算为了方便用户将更多数据采集进入DataHub,提供了针对Logstash的DataHub Output插件。使用Logstash,您可以轻松享受到Logstash开源社区多达30+种数据源支持(file,syslog,redis,log4j,apache log或nginx log),同时Logstash还支持filter对传输字段自定义加工等功能。
Step3:数据存储
3.1 数据存储概述
通过Logstash实时采集上来的日志数据存储在DataHub中,通过阿里云数加·流计算处理的流数据将存储在云数据库RDS中。在使用数据存储情况先,需要首先来在阿里云流计算中注册其存储信息,即可与这些数据源进行互通。
3.2 DataHub配置
目前DataHub都是定向开通,需要用户邮件申请。
点击申请,[email protected],邮件标题须置为DataHub需求沟通。
创建Project和Topic
项目(project)是DataHub数据的基本组织单元,下面可以包含多个Topic。
操作步骤:
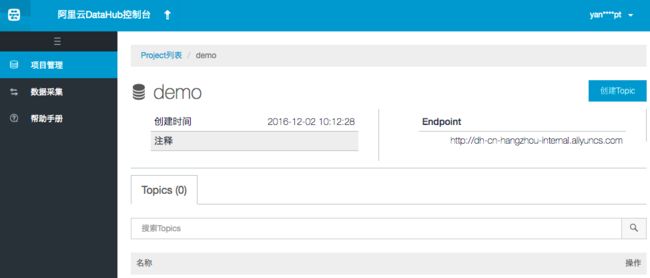
步骤1:登录 DataHub 管理控制台,点击创建Project(目前项目为demo)。

步骤2:点击新创建的project操作栏中的查看,进入project创建Topic。
步骤3:按照弹出框来填写相关配置项,具体如下图所示:
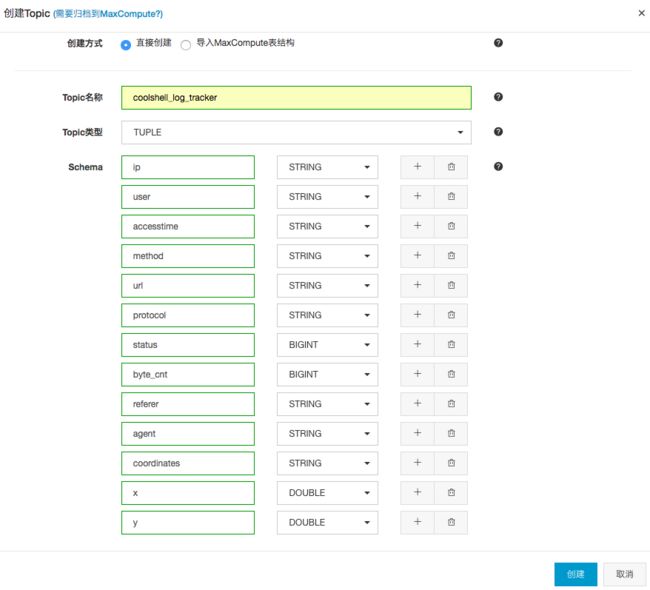
配置项完成后,点击创建即可完成DataHub具体project下Topic的创建。
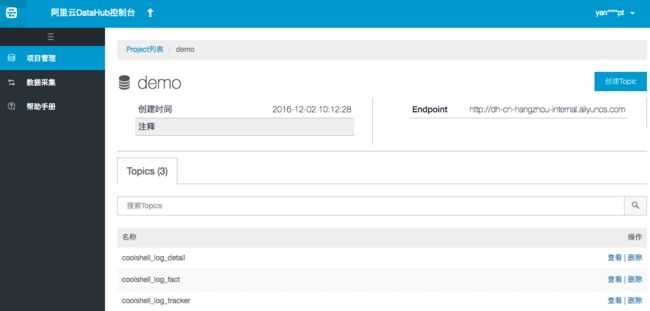
同样方式创建coolshell_log_detail、coolshell_log_fact两个Topic(具体Topic结构详见章节3.2 DataHub配置)。
如下图所示:
3.3 RDS数据表创建
目前阿里云数加·StreamCompute只支持RDS for MySQL数据源。
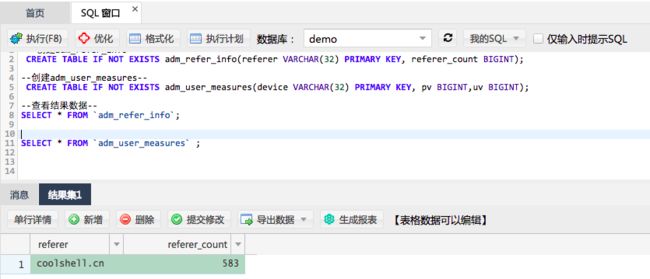
创建表的SQL如下(可以使用阿里云DMS:

--创建adm_refer_info--
CREATE TABLE IF NOT EXISTS adm_refer_info(referer VARCHAR(32) PRIMARY KEY, referer_count BIGINT);
-创建adm_user_measures-
CREATE TABLE IF NOT EXISTS adm_user_measures(device VARCHAR(32) PRIMARY KEY, pv BIGINT,uv BIGINT);3.4 小结
根据数据结构设计中涉及到的DataHub Topic以及RDS表结构进行建表,为后续案例顺利展开提供准入条件。
Step4:流式数据处理
接下来我们就需要对流数据进行加工和处理,目前阿里云数加·流计算支持Stream SQL语法预检查、SQL在线调试、代码版本管理等IDE开发环境。
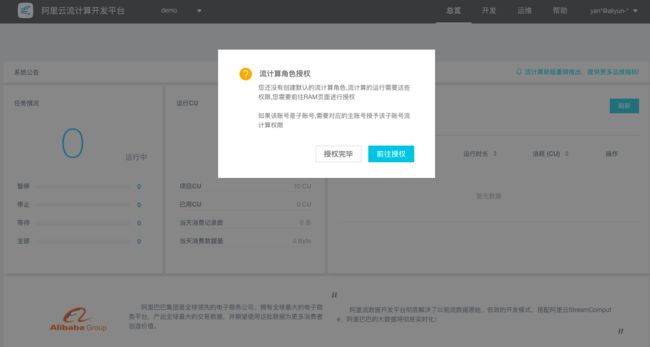
4.1 角色授权(仅限首次开通)
此步骤仅适用于首次开通阿里云数加·流计算服务,需要给一个名称为AliyunStreamComputeDefaultRole的系统默认角色给流计算的服务账号,当且仅当该角色被正确授予后,流计算才能正常地调用相关服务。
操作步骤:
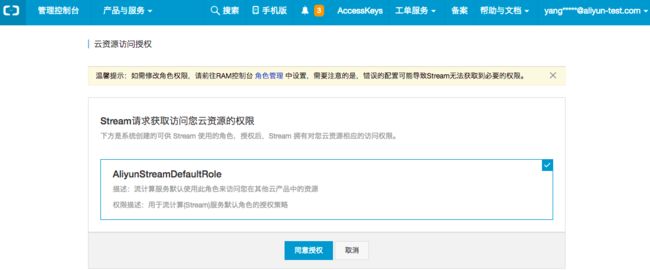
步骤1: 首次登录 StreamCompute将会有弹出框,点击前往授权。如下图所示:
步骤2: 点击同意授权即可完成将默认角色AliyunStreamComputeDefaultRole授予给流计算 服务账号。此时即完成了授权的全部内容,如下图所示:
4.2. 注册DataHub数据存储
数据源在使用前必须经过流计算里面的注册过程,注册相当于在流计算平台中登记相关数据源信息,方便后续的数据源使用。
操作步骤:
步骤1:登录 StreamCompute,点击开发,并在左侧切换至数据存储。

步骤2: 选择DataHub数据源右键 注册数据源或 点击+,如下图所示:

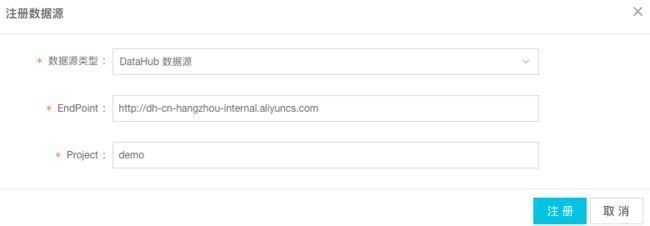
步骤3: 输入注册的数据源信息,单击 注册,如下图所示:
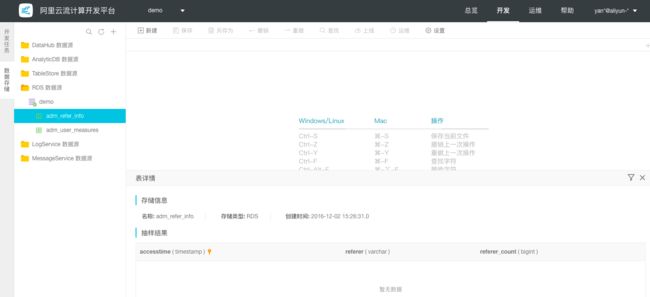
步骤4: 注册成功的数据源信息,可以通过点击DataHub数据源逐层展开,然后右键方式 查看数据详情,如下图所示:
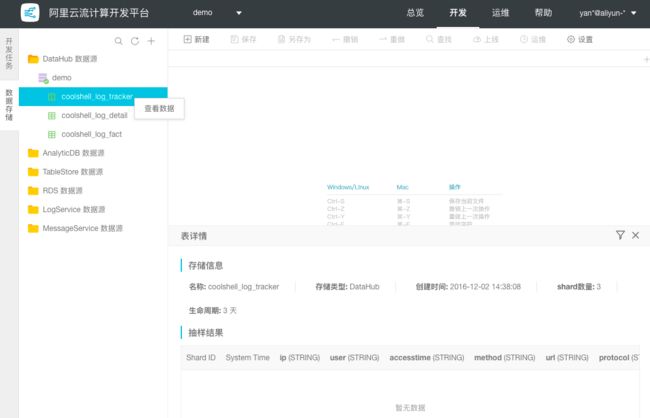
备注:细心用户会发现在Topic数据预览中显示暂无数据,这是因为本文是模拟一个场景,并没有真实流数据进入所以Logstash并不会进行采集。接下来我们将通过shell命令模拟数据流动。
注册信息说明:
Endpoint:填写DataHub的Endpoint地址,公网地址统一为http://dh-cn-hangzhou.aliyuncs.com
Project为DataHub中具体对应的Project为demo
4.3 注册RDS数据存储
当前RDS仅支持MySQL引擎的数据库,其他的数据库引擎暂时不支持。
操作步骤:
步骤1: 登录StreamCompute,点击开发,并在左侧切换至数据存储。
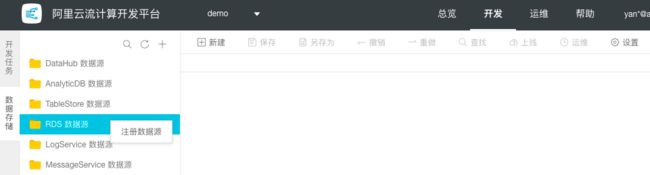
步骤2:选择RDS数据源并右键点击注册数据源。

步骤3:输入注册的数据源信息,点击注册。
步骤4:逐层展开RDS数据源,可查看到已被注册在流计算的相关RDS数据表。
注册信息说明:
地域:选择RDS地域,建议在购买RDS资源的时候选择华东2或尽可能靠近华东地域。
Instance:填写RDS实例ID。
DataBaseName:填写需要连接的数据库名称。
UserName/Password:数据库登录名称/密码。
4.4 创建Stream SQL任务
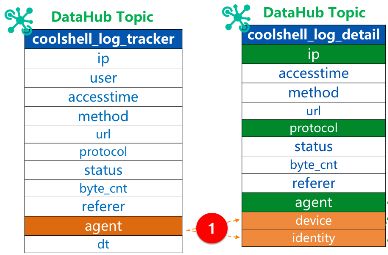
处理逻辑1
新建Stream SQL任务来对流数据进行分析和处理。先来处理coolshell_log_tracker到coolshell_log_detail的处理逻辑。
操作步骤:
步骤1:登录 StreamCompute,点击开发,并新建文件夹(文件夹深度最大值为5)。
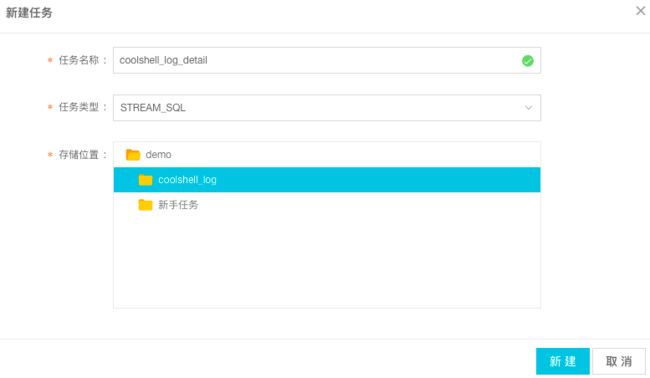
步骤2:输入需要新建的文件夹名称并选择存储位置,点击新建。
步骤3:选择新建的文件夹右键选择新建任务。
步骤4:输入要创建的任务名称,任务类型默认为Stream SQL,点击新建。
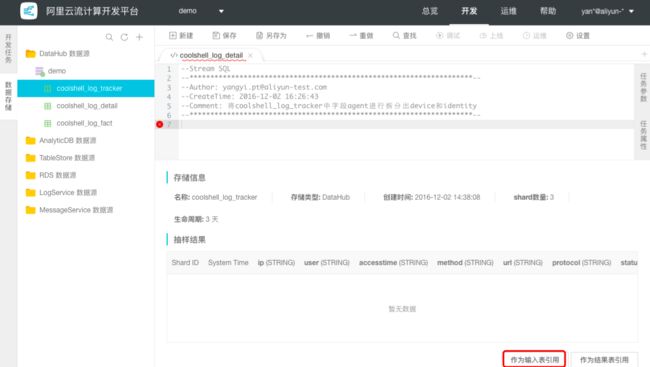
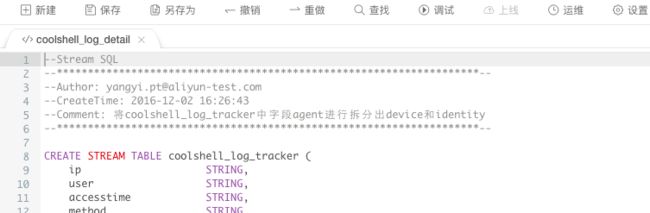
步骤5: 创建流式源表,双击需要引用的源表coolshell_log_tracker,并点击表详情页中作为输入表引用。
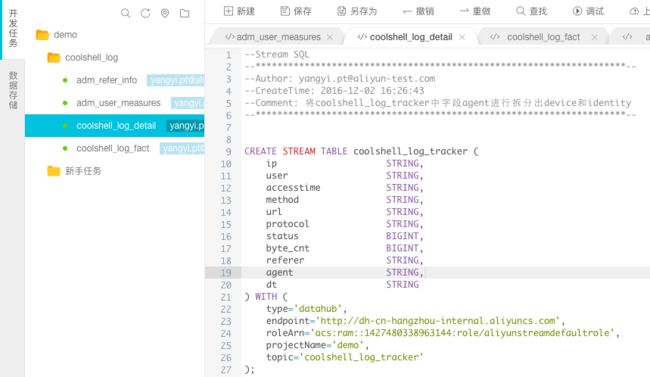
步骤6:创建流式结果表,双击需要引用的DataHub Topic:coolshell_log_detai,并点击表详情页中作为结果表引用。
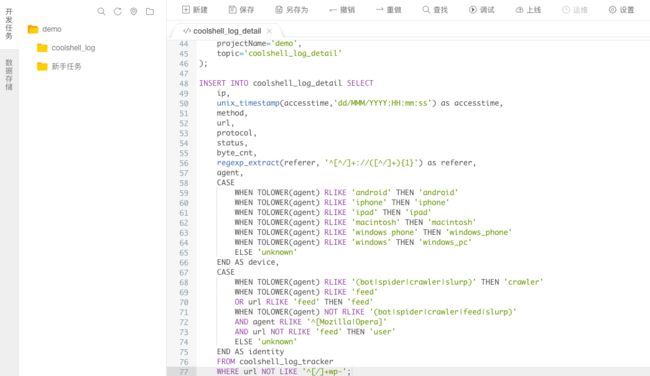
步骤7:编写Stream SQL处理逻辑。
INSERT INTO coolshell_log_detail SELECT
ip,
accesstime,
method,
url,
protocol,
status,
byte_cnt,
regexp_extract(referer, '^[^/]+://([^/]+){1}') as referer,
agent,
CASE
WHEN TOLOWER(agent) RLIKE 'android' THEN 'android'
WHEN TOLOWER(agent) RLIKE 'iphone' THEN 'iphone'
WHEN TOLOWER(agent) RLIKE 'ipad' THEN 'ipad'
WHEN TOLOWER(agent) RLIKE 'macintosh' THEN 'macintosh'
WHEN TOLOWER(agent) RLIKE 'windows phone' THEN 'windows_phone'
WHEN TOLOWER(agent) RLIKE 'windows' THEN 'windows_pc'
ELSE 'unknown'
END AS device,
CASE
WHEN TOLOWER(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler'
WHEN TOLOWER(agent) RLIKE 'feed'
OR url RLIKE 'feed' THEN 'feed'
WHEN TOLOWER(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)'
AND agent RLIKE '^[Mozilla|Opera]'
AND url NOT RLIKE 'feed' THEN 'user'
ELSE 'unknown'
END AS identity
FROM coolshell_log_tracker
WHERE url NOT LIKE '^[/]+wp-';编写完成的Stream SQL任务如下图所示。
调试Stream SQL任务
数据开发为用户提供了一套模拟的运行环境,在该环境中运行Stream SQL可以实现和生产完全隔离和支持构造测试数据。
操作步骤:
步骤1: 编写好Stream SQL任务后,点击 调试 对该任务进行调试。
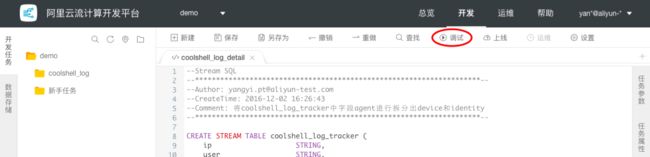
步骤2: 构造调试数据,首先下载调试模板至本地进行构造调试数据(只支持CSV)。
步骤3: 本地构造好数据后,选择调试数据进行调试Stream SQL任务,点击 调试。
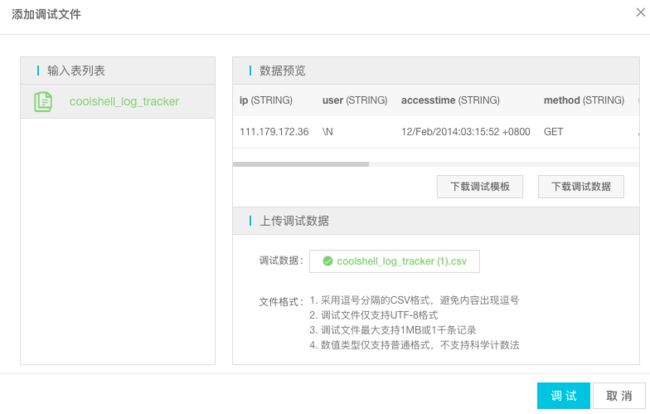
步骤4: 查看调试结果,如下图:
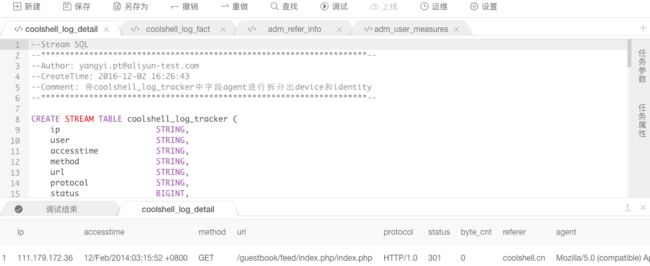
验证结果正确无误后,可右键点击调试结果将其下载到本地(csv文件)用于下一处理逻辑的调试数据。
处理逻辑2
接下来处理coolshell_log_detail到coolshell_log_fact的处理逻辑。如下示意图:

操作步骤:
步骤1: 同样在上述文件目录下新建Stream SQL任务,点击新建。
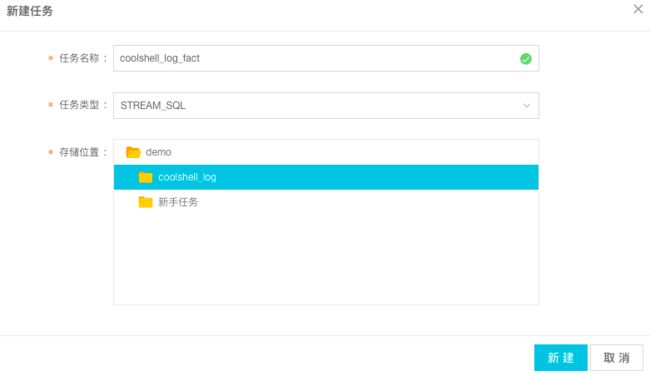
步骤2: 创建流式源表,双击需要引用的源表coolshell_log_detail,并点击表详情页中作为输入表引用。
步骤3: 创建流式结果表,双击需要引用的DataHub Topic:coolshell_log_fact,并点击表详情页中作为结果表引用。
步骤4: 编写流式数据处理逻辑,SQL如下:
INSERT INTO coolshell_log_fact select
md5(concat(ip, device, protocol, identity, agent)),--根据ip、device、protocol、identity和agent字段可以唯一确定uid
ip,
accesstime,
method,
url,
protocol,
status,
byte_cnt,
referer,
agent,
device,
identity
FROM coolshell_log_detail;步骤5:同上的处理逻辑,选择上一环节中的调试数据,进行本次逻辑的调试。
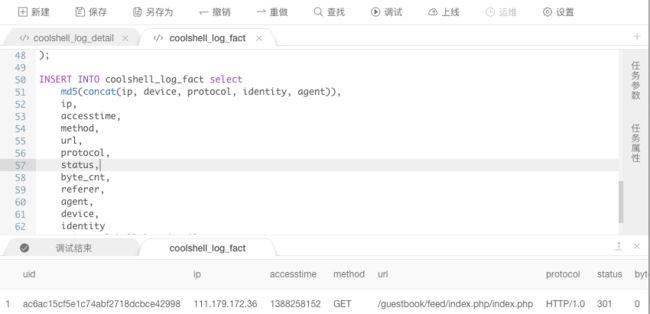
如调试结果所示,确认是否为自己业务所需要的正确结果。
处理逻辑3和处理逻辑4
同样安装上述步骤下来配置adm_refer_info到adm_user_measures的处理逻辑。主要SQL如下:(统一引用输入数据源为coolshell_log_fact,输出结果数据源为RDS表:adm_refer_info和adm_user_measures)
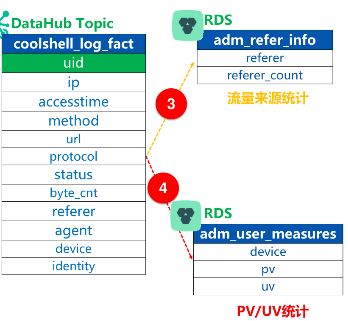
---adm_refer_info中的处理逻辑---
REPLACE INTO adm_refer_info SELECT
referer,
COUNT(referer) as referer_count
FROM coolshell_log_fact
WHERE LENGTHqi(referer) > 1
GROUP BY referer;--adm_user_measures中的处理逻辑---
REPLACE INTO adm_user_measures SELECT
device,
COUNT(uid) as pv,
COUNT(distinct uid) as uv
FROM coolshell_log_fact
GROUP BY device;附录:adm_region_measures和flyingline_coordinates处理逻辑
REPLACE INTO adm_region_measures SELECT
CASE
WHEN region='%{[geoip][city_name]}' THEN 'unknown'
WHEN region!='%{[geoip][city_name]}' THEN region
END AS region,
count(region) FROM coolshell_log_tracker_bak
GROUP BY region;
INSERT INTO flyingline_coordinates
SELECT CASE
WHEN region='%{[geoip][city_name]}' THEN 'unknown'
WHEN region!='%{[geoip][city_name]}' THEN region
END AS region,
coordinates,x,y FROM coolshell_log_tracker_bak where coordinates is NOT NULL;4.5. 上线Stream SQL任务
当您完成开发、调试,经过验证Stream SQL正确无误之后,可将该任务上线到生产系统中。
操作步骤:
步骤1: 点击上线 即可将上述两个Stream SQL任务依次一键发布至生产系统。

步骤2: 选择coolshell_log_detail任务,点击上线。
步骤3: 选择coolshell_log_fact任务,点击上线。
步骤4: 经过上述步骤已将任务上线至生产环境,但该任务处于未启动状态,需要进入运维中依次启动上述任务。
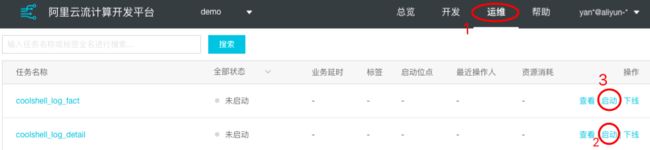
步骤5:点击启动按钮,在启动coolshell_log_detail任务时弹出框中选择 指定读取数据时间 一定要小于实时采集任务的启动时间。点击按以上配置启动。

任务处于启动中的状态。具体如下图所示:
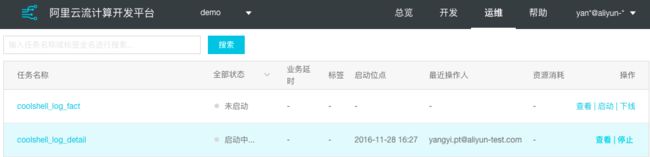
当任务正常启动后期状态如下图所示:
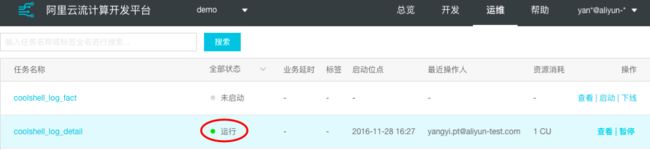
也可点击操作栏中的查看,进行任务监控仪表盘。

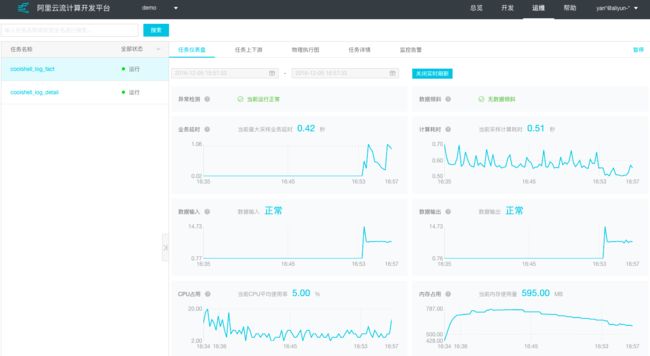
步骤6:以同样的方式启动coolshell_log_fact任务,启动时间选择到上述任务正常启动时间前即可。最终配置的工作流如下图:
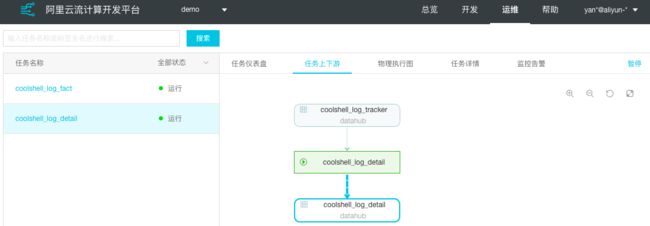
从图中可以看出数据表与流式任务之间的处理逻辑和上下游关系。
步骤7: 以同样的方式将adm_user_measures和adm_refer_info两个流式任务上线。
4.6 确认结果输出
当所有流式任务跑起来后,需要确认DataHub Topic/RDS结果表中的数据输出情况。
操作步骤:
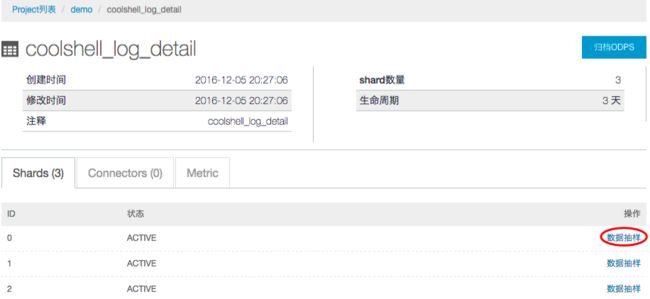
步骤1: 首先确认DataHub结果情况,可通过点击进入某Topic然后进行数据抽样。

步骤2: 其次确认RDS表数据写入情况,登录DMS for RDS,如下图:
4.7 小结
本章主要针对采集上来的日志数据进行流式任务处理和分析,并根据数据结果链路图中逻辑关系进行了一定程度的数据处理,最终将需要在大屏上展示的数据写入云数据RDS中。在阿里云数加·流计算中提供与生产完全隔离的调试环境,当任务调试无误后在进行发布至生产系统中。
Step5:数据可视化展现
相较于传统图表与数据仪表盘(如通过离线日志分析的结果展现案例),如今的数据可视化更生动并可即时呈现隐藏在瞬息万变且庞杂数据背后的业务洞察。
5.1 创建RDS数据源
经过数据实时采集、流式数据的处理,将结果数据写入RDS,为了较好的展现并洞察业务数据,我们需要在DataV中新建数据源来源。
操作步骤:
步骤1: 登录数加管控台。

步骤2:点击 DataV数据可视化,进入DataV开发页面。
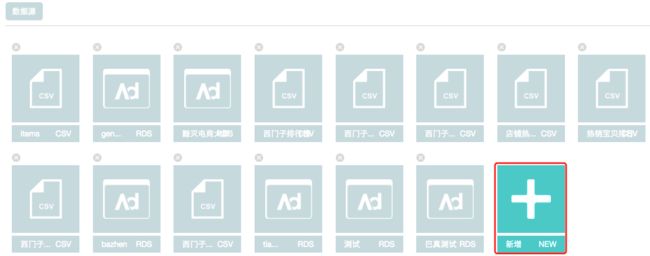
步骤3:在页面中找到数据源栏,点击+进行配置数据源。
步骤4: 选择类型为云数据库RDS版,并配置要连接的数据库信息,点击测试,测试成功后点击确定保存配置信息即可。

5.2 创建DataV大屏
经过数据实时采集、流式数据的处理,将结果数据写入RDS,为了较好的展现并洞察Coolshell网站的业务数据,我们需要在DataV中新建数据源来源。
操作步骤:
步骤1: 在项目栏中点击 新建 +,进行创建大屏项目。
步骤2: 进入模板页,可以选择具体模块进行,也可以选择空白页面进行创建。本案例选择第一个模板进行构建Coolshell网站运营数据分析的大屏。
步骤3:点击图表左上角删除按钮进行删除不需要的图表,并调整布局如下图所示:
步骤4:需要修改模板中的元素。首先点击【中国公路物流指数】,在右侧中修改其显示内容为【Coolshell.cn运营指数】,同样修改其他显示字样如下图所示:
步骤5:配置日流量量数据。点击日流量并在右侧切换至面板数据tab。
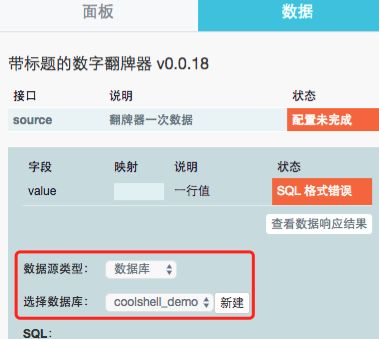
步骤6:选择数据源类型为上一章节配置的数据源。
步骤7:编辑日浏览量翻牌器的SQL如下:
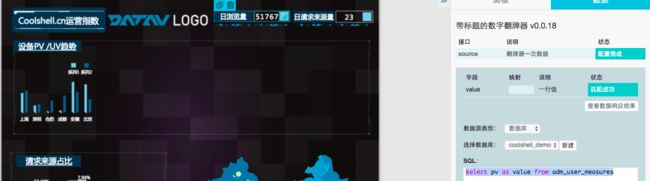
select sum(pv) as value from adm_user_measures;
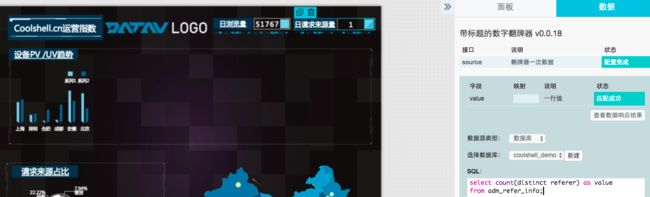
步骤8:编辑日请求来源翻牌器的SQL如下,并勾选自动更新。
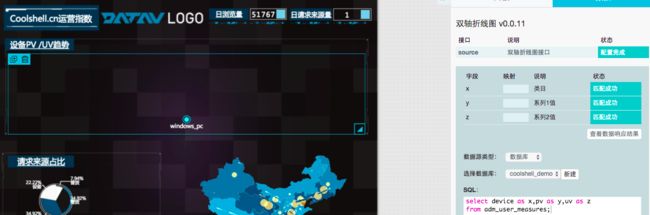
select count(referer) as value from adm_refer_info;步骤9:删除设备PV/UV趋势的现有柱状图替换为双轴折线图,并配置数据如下(勾选底部 自动更新)。
select device as x,pv as y,uv as z from adm_user_measures;步骤10: 删除请求来源占比的现有饼图替换为【指标-轮播列表】配置数据如下(勾选底部自动更新)。

select referer as 请求来源,referer_count as 请求量from adm_refer_info;步骤11: 其中地图暂不进行设置(备注:有兴趣朋友可以根据Logstash的geoip地址查询归类研究下PV或者用户的地域分布)。
步骤12:点击有上角预览 进行查看配置后的效果。
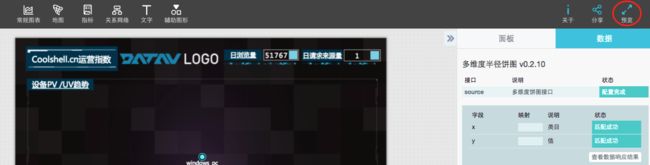
预览效果如下所示:

5.3 小结
本章节中主要进行数据可视化大屏的配置,大屏中的地图数据并没有进行对接,如果感兴趣的用户可以尝试利用Logstash中的GeoIPO地址查询归类的过滤插件,将IP地址转化为对应的地域信息,包括国别,省市和经纬度等,详见。
如果您已经熟悉使用整套解决方案,可以根据个性化定制如下大屏并对接RDS数据。

常见问题
Q:在使用Logstash向DataHub实时推送数据时发现报time out。
A :在endpoint配置项中DataHub提供两个地址可供填写,一个是阿里云生产网http://dh-cn-hangzhou-internal.aliyuncs.com,一个是 http://dh-cn-hangzhou.aliyuncs.com。 若发现用户处于公网环境中需要使用http://dh-cn-hangzhou.aliyuncs.com,否则会出现报错。
Q:修改Stream SQL后也进行了上线,但是并没有生效。
A :一般情况下,点击上线后需要在【运维】中进行暂停任务->停止任务->启动任务,新代码才能才生效。
Q:配置了数据可视化DataV大屏后,在预览情况下发现数据不自动刷新。
A :需要在大屏配置中勾选数据底部的自动更新,并根据需求填写隔多少秒自动刷新一次数据。