韩松EIE:Efficient Inference Engine on Compressed Deep Neural Network论文详解
EIE为韩松博士在ISCA 2016上的论文。实现了压缩的稀疏神经网络的硬件加速。与其近似方法的ESE获得了FPGA2017的最佳论文。
目录
一、背景与介绍
1.1 Motivation
1.2 前期工作
1.3 贡献点
二、方法
2.1 公式描述
神经网络的基本运算
对于神经元的运算
Deep compression后的公式
查表与值
2.2 矩阵表示(重要)
三、硬件实现
3.1 CCU与PE
3.2 Activation Queue and Load Balancing
3.3 Pointer Read Unit
3.4 Sparse Matrix Read Unit
3.5 Arithmetic Unit
3.6 Activation Read/Write
3.7 Distributed Leading Non-Zero Detection
3.8 Central Control Unit(CCU)
3.9 布局情况
四、实验情况
4.1 速度与功耗
4.2 负载平衡中FIFO队列的长度
4.3 SRAM的位宽度
4.4 运算精度
4.5 并行PE数对速度的提升
4.6 与同类工作的对比
五、重要信息总结
平台为ASIC
重要贡献
运算吞吐量
一、背景与介绍
1.1 Motivation
最新的DNN模型都是运算密集型和存储密集型,难以硬件部署。
1.2 前期工作
Deep compression 通过剪枝,量化,权值共享等方法极大的压缩了模型。Deep compression解析见下链接
https://blog.csdn.net/weixin_36474809/article/details/80643784
1.3 贡献点
- 提出了EIE (Efficient Inference Engine)的方法,将压缩模型应用与硬件。
- 对于压缩网络来说,EIE可以带来120 GOPS/s 的处理效率,相当于同等未压缩的网络 3TGOP/s的处理效率。(AlexNet需要1.4GOPS,ResNet-152需要22.6GOPS)
- 比CPU和GPU带来24000x和3400x的功率提升。
- 比CPU,GPU和Mobile GPU速度快189x, 13x,307x
二、方法
2.1 公式描述
神经网络的基本运算
对于神经网络中的一个Fc层,相应的运算公式是下面的:

其中,a为输入,v为偏置,W为权重,f为非线性的映射。b为输出。此公式即神经网络中的最基本操作。
对于神经元的运算
针对每一个具体的神经元,上面的公式可以简化为下面这样:

输入a与权重矩阵W相乘,然后进行激活,输出为b
Deep compression后的公式
Deep compression将相应的权重矩阵压缩为一个稀疏的矩阵,将权值矩阵Wij压缩为一个稀疏的4比特的Index Iij,然后共享权值存入一个表S之中,表S有16种可能的权值。所以相应的公式可以写为:

即位置信息为i,j,非零值可以通过Iij找到表S中的位置恢复出相应的权值。
查表与值
权值的表示过程经过了压缩。即CSC与CRC的方法找到相应的权值,即
具体可以参考Deep compression或者网上有详细的讲解。
https://blog.csdn.net/weixin_36474809/article/details/80643784

例如上面的稀疏矩阵A。我们将每一个非零值存下来在AA中。
JA表示换行时候的第一个元素在AA中的位置。例如A中第二列第一个元素在A中为第四个,第3行元素在A中为第6个。
IC为对应AA每一个元素的列。这样通过这样一个矩阵可以很快的恢复AA表中的行和列。
2.2 矩阵表示(重要)

这是一个稀疏矩阵相乘的过程,输入向量a,乘以矩阵W,输出矩阵为b,然后经过了ReLU。
用于实现相乘累加的单元称为PE,相同颜色的相乘累加在同一个PE中实现。例如上面绿色的都是PE0的责任。则PE0只需要存下来权值的位置和权值的值。所以上面绿色的权值在PE0中的存储为下面这样:

通过CSC存储,我们可以很快看出virtual weight的值。(CSC不懂见上一节推导)。行标与元素的行一致,列标可以恢复出元素在列中的位置。
向量a可以并行的传入每个PE之中,0元素则不并行入PE,非零元素则同时进入每一个PE。若PE之中对应的权重为0,则不更新b的值,若PE之中对应的权重非零,则更新b的值。
三、硬件实现
3.1 CCU与PE

CCU(Central control unit中央控制器)用于查找非零值,广播给PE(Processing Element处理单元,可以并行的单元,也是上文中的PE)。上图a为CCU,b为单个PE
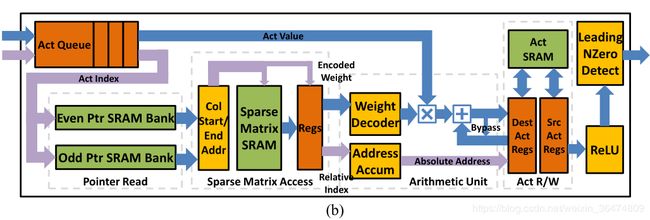
PE即上面算法中的PE单元, 实现将CCU广播过来的数据进行卷积的相乘累加和ReLU激活。下面为每个具体单元的作用。
3.2 Activation Queue and Load Balancing
数据序列与负载平衡
上图之中的连接PE与CCU之间的序列。如果CCU直接将数据广播入PE,则根据木桶短板效应,最慢的PE是所有PE的时间的时长。

所以我们在每个PE之前设置一个队列,用于存储,这样PE之间不同同步,只用处理各自队列上的值。
- 只要队列未满,CCU就向PE的队列广播数据
- 只要队列之中有值,PE就处理队列之中的值
这样,PE之间就能最大限度的处理数据。
3.3 Pointer Read Unit

根据当前需要运算的行与列生成相应的指针传入稀疏矩阵读取单元。运用当前的列j(CCU传来的数据是数据和数据的列j)来生成相应的指针pj(此指针用于给Sparse Matrix Read Unit来读取对应的权值)
3.4 Sparse Matrix Read Unit

根据前面传入的指针值,从稀疏矩阵的存储之中读取出权重。即用前面传来的指针pj读取权重v,并将数据x一并传给ArithMetic Unit。即传给Arithmetic Unit的值为(v,x)
3.5 Arithmetic Unit

进行卷积之中的权重与feature相乘,然后累加的操作。从前面Sparse Matrix Read Unit中读出相乘得两个值,从后面的 Act R/W中读出偏移和加上后结果写入。
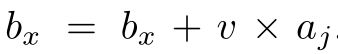
3.6 Activation Read/Write

取出偏置给Arithmetic Unit并且将Arithmetic Unit运算之后的结果传给激活ReLU层。即实现+bx的过程和传给最终结果给ReLU
3.7 Distributed Leading Non-Zero Detection

LNZD node,用于写入每层计算feature,下一层计算的时候直接传给CCU到下一层。在写入过程直接写入,运算过程可以探测非零值然后传给CCU。

这个因为神经网络计算方式,本层计算结果作为下一层的计算输入,激活神经元要被分发到多个PE里乘以不同的权值(神经网络计算中,上一层的某个神经元乘以不同的权值并累加,作为下一层神经元),Leading非零值检测是说检测东南西北四个方向里第一个不为0(激活)的神经元,就是每个PE都接受东南西北4个方向来的输入,这4个输入又分别是其他PE的输出,是需要计算的,那我这个PE计算时取哪个方向来的数据呢?用LNZD判断,谁先算完就先发射谁,尽量占满流水线。
PE之间用H-tree结构,可以保证PE数量增加时布线长度以log函数增长(增长最缓慢的形式)
3.8 Central Control Unit(CCU)
用于将LZND模块之中的值取出来然后传入PE的队列之中。
IO模式:当所有PE空闲的时候, the activations and weights in every PE can be accessed by a DMA connected with the Central Unit
运算模式:从LZND模块之中,取出相应的非零值传入PE的队列之中。
3.9 布局情况

作者运用台积电TSMC的45nm的处理器。上图为单个PE的布局情况。

表II为各个模块的功率消耗与区域占用情况。(其实我们看出,主要的功率消耗和区域占用在于稀疏矩阵读取单元SpmatRead,而不是直观上的运算单元ArithmUnit)
四、实验情况
实现平台
作者运用Verilog将EIE实现为RTL,synthesized EIE using the Synopsys Design Compiler (DC) under the TSMC 45nm GP standard VT library with worst case PVT corner. 运用台积电45nm和最差的PVT corner。作者用较差的平台来体现压缩及设计带来的数据提升。
We placed and routed the PE using the Synopsys IC compiler (ICC).We annotated the toggle rate from the RTL simulation to the gate-level netlist, which was dumped to switching activity interchange format (SAIF), and estimated the power using Prime-Time PX.
4.1 速度与功耗

运算平台:不同颜色是不同架构的运算平台,如CPU为Intel core i7 5930k,GPU为NVIDIA GeForce GTX Titan X,mobilt GPU为NVIDIA的cuBLAS GEMV。我们看到EIE起到了最快的效果。
运行的神经网络:如下:
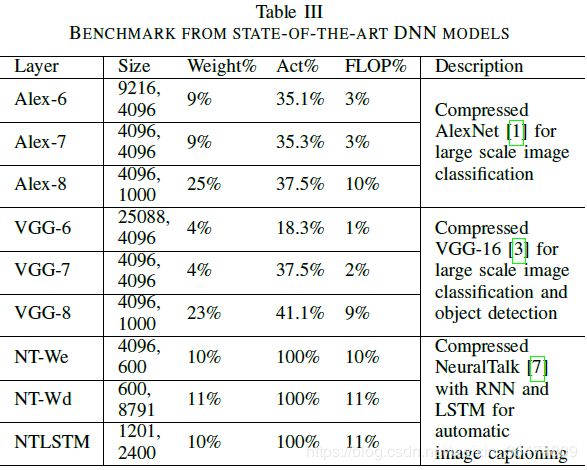
运行时间见下表

4.2 负载平衡中FIFO队列的长度
负载平衡见3.2 ,FIFO为先进先出队列,用于存储CCU发来的数据给PE进行处理。FIFO越长越利于负载平衡

因为每个PE分得的是否为稀疏的数量为独立同分布的,所以FIFO越长,其总和的方差越小。所以增大FIFO会有利于PE之间的负载平衡。

4.3 SRAM的位宽度
SRAM的位宽度接口,位宽越宽则获取数据越快,读取数据次数越少(下图绿线),但是会增大功耗(蓝色条)。如下图:

总体的能量消耗需要两者相乘,如下:

4.4 运算精度
作者运用的是16bit定点运算。会比32bit浮点减少6.2x的功率消耗,但是会降低精度。

4.5 并行PE数对速度的提升

4.6 与同类工作的对比
内容较多,感兴趣自行查看原文。

五、重要信息总结
平台为ASIC
EIE的platform Type为ASIC(专门目的定制集成电路)。现在的大部分ASIC设计都是以半定制和FPGA形式完成的。半定制和FPGA可编程ASIC设计的元件成本比较:CBIC元件成本IC价格的2-5倍。但是半定制ASIC必须以数量取胜,否者,其设计成本要远远大于FPGA的设计成本。
重要贡献
速率和功耗。例如9层全连接层之中,
- 速率比CPU,GPU,mobile GPU速率快了189x,13x,307x,
- 功率降低24000x,3400x,2700x
运算吞吐量
稀疏网络达到102 GOPS/s,相当于未压缩的网络 3TOPS/s